YugabyteDB Savepoints: Checkpointing Work in Distributed Transactions
January 21, 2022
Yugabyte brings best-in-class performance, scalability, and availability to YugabyteDB, a fully PostgreSQL-compatible SQL database. Because YugabyteDB’s architecture uses PostgreSQL at the SQL layer, we get a long-tail of PostgreSQL compatibility for free. But implementing savepoints requires deeper integration into YugabyteDB’s distributed persistence and transaction layers.
In this blog post, we’ll discuss why you should care about savepoints. We’ll also examine how we built savepoints into YugabyteDB’s distributed transaction layer, and what other PostgreSQL functionality this unlocks.
Should you care about savepoints?
First, let’s talk about savepoints. Below’s a very basic example:

This contrived example illustrates the basic functionality of savepoints. With savepoints, you can save state within a transaction, and rollback to checkpoints without rolling back the whole transaction. You can create a very large number of savepoints if you’d like (technically, up to 2^32-1). And you can rollback to any of them at any point.
So, why would you do this? In plain english, this is most useful when you have pieces of work within a transaction that have low (but non-zero) risk of failure. It’s also useful where you have alternative ways to make progress in a transaction or may succeed when retrying. This case can come up, for example, in workloads with spurious unique index constraint violations or resolvable foreign key constraint violations.
Getting started with savepoints
Let’s start with a bit of terminology — we can think of savepoints as breaking a transaction into a series of subtransactions:
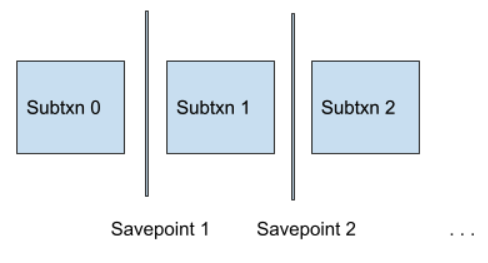
At any given moment within a transaction, we are working within the context of exactly one subtransaction with a unique subtransaction ID. These IDs get assigned sequentially any time we create a new savepoint or rollback to an old savepoint. In this way, if we’re currently in subtransaction ID 5, and we rollback to subtransaction ID 2, we can simply consider all data written in subtransactions 2->5 (inclusive) no longer valid, and jump to a new subtransaction ID 6 for subsequent operations.
How we built savepoints
As is the case with many features in YugabyteDB, we start by re-using as much PostgreSQL code as possible. In this case, we get code that manages savepoint creation and deletion. We also receive bookkeeping about which savepoint we’re currently working against, for free. The PostgreSQL client manages active subtransactions and which ones roll back.
Any time PostgreSQL sends operations to a tserver, there is a “subtransactionId” and a “rolled back subtransaction set” associated with the request. All data persisted in DocDB as part of that operation now persists with a subtransaction Id as well. Any reads which interact with data from this transaction will only surface data not part of a rolled-back subtransaction.
In the background, PostgreSQL will push state about which subtransactions are still live to the transaction coordinator. We already have a heartbeat to the transaction coordinator — we piggy back this additional state on the existing heartbeat. This allows conflict resolution to also take advantage of this state. Therefore, if another transaction conflicts with data from our transaction, but we rolled back the persisted subtransaction, then we can avoid treating this as a conflict.
Finally, when we commit the transaction, we send state tracking which subtransactions are still live to the transaction coordinator. This gets persisted as part of the transaction status update which flips the status to committed. Until this transaction is fully applied, any code paths which read the provisional data of this transaction will get this state from the same RPC. This indicates a committed transaction, and rolled-back subtransactions can mask provisional data.
Increased PostgreSQL compatibility
We spoke before about the importance of reusing PostgreSQL in our top layer. Supporting savepoints brings us even closer, allowing us to enable even more of PostgreSQL’s own regression tests. It also removes a blocker for full functionality of popular tools built on top of PostgreSQL. Such tools include: Spring, Hibernate, GORM, Sequelize, Django, and Dapper.
Implementing savepoints provides an ability to catch and handle pl/pgSQL exceptions. Thanks to YugabyteDB’s architecture, which fully reuses PostgreSQL’s’ implementation of savepoints at the query layer, we now get this exception handling essentially for free. This means you can now write stored procedures that handle more complex work and are more resilient to failures.
If you haven’t already, take YugabyteDB for a spin by downloading the latest version of the open source. And if you have any questions, please don’t hesitate to ask them in the YugabyteDB community Slack channel.


