Using GIN Indexes in YugabyteDB
December 13, 2021
At Yugabyte, we are committed to complete PostgreSQL compatibility. Similar to PostgreSQL, YugabyteDB supports the following three container column types. These three data types are extremely useful in various cases:
- jsonb – Makes it useful for schema-less data use cases
- tsvector – Supports full text search through a sorted list of distinct lexemes
- array – Gives the flexibility to store a large composite variable-length value in a single field
Each data type’s utility is severely limited without an efficient way to index them. Let’s explore the following containment search examples to see why these regular indexes are insufficient.
Why are ordinary secondary indexes insufficient?
- Filtering text columns based on what words they contain. Let’s take an example table from YugabyteDB docs:
CREATE TABLE book (page int PRIMARY KEY, word text[]);
To retrieve pages 4 to 7, you can easily create a regular index and use this query:
SELECT * FROM book WHERE page >= 4 and page <= 7;
But looking for the specific word ‘foo’ would need a full table scan:
SELECT * FROM book WHERE words && ARRAY['foo'];
Creating a regular index won’t help since you still need to search words for foo.
- Filtering array columns based on what array elements they contain. Let’s take an example of a “students” table. The table consists of name, exam scores as an array, and phone number. We could find out which student has a particular contact number efficiently by creating a secondary index on the phone number column. But to find out the number of students who received a 90 on one of the exams would need a full table scan.
- Similarly, we see JSON use cases where users need to filter based on the existence of top-level keys or primitive values of the JSON column. They also need to filter JSON columns based on primitive values of deeply-nested keys.
None of these use case questions are efficiently answered by conventional indexes without full table scans. We need to be able to index these data types in a more fine-grained way than the conventional regular indexes to support these data types for our customers. And generalized inverted (GIN) indexes are the answer.
What are GIN indexes?
In YugabyteDB 2.11, we added support for GIN indexes. GIN indexes were originally developed to support full-text search in PostgreSQL. However, they are generalized since they can be used with other data types (in particular, arrays and jsonb documents).
YugabyteDB is a distributed SQL database that reuses the PostgreSQL query layer. This means that many features come without additional effort. With that said, the distributed storage is different from the monolithic PostgreSQL, using LSM Tree tables instead of B-Tree and Heap tables. The YugabyteDB YBGIN is similar to PostgreSQL GIN, but implemented on top of LSM Tree indexes.
You can create the index using ybgin to specify the index access method:
CREATE INDEX <optional name> ON <table> USING YBGIN (<column>);Operator classes support
Operator classes define semantics for index columns of a particular data type and a particular index access method. An operator class specifies that a particular operator family is applicable to a particular indexable column data type. As shown in the below table, YugabyteDB supports all the GIN operator classes included in the core PostgreSQL distribution.
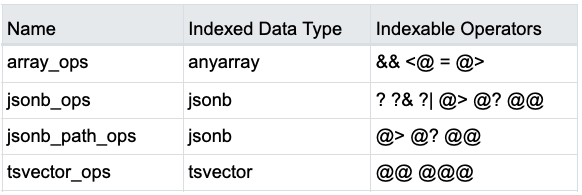
Of the two operator classes for type jsonb, jsonb_ops is the default in PostgreSQL. However, first implement the jsonb_path_ops index due to the reasons highlighted in the table below.

You can have multiple operator classes on a single index since operator classes are per column:
CREATE INDEX ON json_table USING gin (jsonb_col jsonb_ops, jsonb_col jsonb_path_ops);
Better performance with GIN indexes
Now let’s create three tables to demonstrate a performance improvement:
CREATE TABLE vectors (v tsvector, k serial PRIMARY KEY); CREATE TABLE arrays (a int[], k serial PRIMARY KEY); CREATE TABLE jsonbs (j jsonb, k serial PRIMARY KEY);
And let’s create GIN indexes using the below syntax:
CREATE INDEX ON vectors USING ybgin (v); CREATE INDEX ON arrays USING ybgin (a); CREATE INDEX ON jsonbs USING ybgin (j);
Now let’s insert data into these three tables and add some filler rows to make a sequential scan more costly:
INSERT INTO vectors VALUES
(to_tsvector('simple', 'the quick brown fox')),
(to_tsvector('simple', 'jumps over the')),
(to_tsvector('simple', 'lazy dog'));
INSERT INTO vectors SELECT to_tsvector('simple', 'filler') FROM generate_series(1, 1000);
INSERT INTO arrays VALUES
('{1,1,6}'),
('{1,6,1}'),
('{2,3,6}'),
('{2,5,8}'),
('{null}'),
('{}'),
(null);
INSERT INTO arrays SELECT '{0}' FROM generate_series(1, 1000);
INSERT INTO jsonbs VALUES
('{"a":{"number":5}}'),
('{"some":"body"}'),
('{"some":"one"}'),
('{"some":"thing"}'),
('{"some":["where","how"]}'),
('{"some":{"nested":"jsonb"}, "and":["another","element","not","a","number"]}');
INSERT INTO jsonbs SELECT '"filler"' FROM generate_series(1, 1000);We now have 1,000 rows in each table. The GIN index will have entries for each array element. These are words when the text is parsed by to_tsvector() while inserting the rows. Let’s compare the performance improvement with and without GIN indexes:

Similarly, for the arrays table:

Finally, let’s look at performance with a jsonbs table. JSON operators and functions behave exactly the same in YugabyteDB as they do in PostgreSQL. Much of YSQL’s functionality is built by reusing the PostgreSQL query layer.

That’s more than a 3x performance improvement when using a GIN index. GIN indexes store mappings from values within a container column to the row that holds that value. This helps speed up these types of searches or queries.
For simplicity, we have used a relatively small table with 1,000 rows. However, for a larger table with many rows and/or columns, the query performance should be greater than 3x.
Users can consider the following tips to further improve GIN index performance:
- Insertion into a GIN index can be slow due to the likelihood of many keys being inserted for each item. So, for bulk insertions into a table, drop the GIN index and recreate it after finishing a bulk insertion.
- Updating a GIN index tends to be slow because of the intrinsic nature of inverted indexes: inserting or updating one row can cause many inserts into the index (one for each key extracted from the indexed item).
Support for partial GIN indexes
YugabyteDB supports the ability to create a partial inverted index. It does this by including a clause that evaluates to true on a boolean predicate, like a WHERE clause. This is similar to partial indexes that use non-container data types,
Support for PG Extensions
Since YugabyteDB is compatible with PostgreSQL, PG extensions are readily available that add GIN support for some data types.
- pg_trgm: A trigram is a group of three consecutive characters taken from a string. This provides functions and operators for determining the similarity of alphanumeric text based on trigram matching, as well as index operator classes that support fast searching for similar strings. You can use this extension together with full-text search in order to suggest word options to fix typos.
What’s next for GIN indexes?
Yugabyte has been on the journey to near-complete PostgreSQL compatibility for some time now. Features such as stored procedures, triggers, partial indexes, hash joins, indexes, and user-defined types have always set us apart from other database offerings. With these new features, we’re making YugabyteDB the most familiar and developer-friendly distributed SQL database on the market.
At Yugabyte, we strive to be fully transparent with our customers and users. This blog covered an overview of the foundation we built in the first phase. Here are some notable features you can expect in the second phase as part of upcoming releases:
- Multi-column GIN indexes: Ability to create an inverted index with multiple columns. These indexes are used for queries that constrain all index columns.
- Optimize insert operations (background index insertion)
- Support ASC/DESC/HASH on GIN indexes
- Support hstore which implements “key-value” storage. For this data type, operator classes for various access methods are available, including GIN.
- Support btree_gin which adds GIN support for regular data types in order for them to be used in a multi-column index along with container types.
Get started
We’re very happy to release all of these enterprise-grade features in the newest version of our flagship product – YugabyteDB 2.11. We invite you to learn more and try it out:
- YugabyteDB 2.11 is available to download. You can install the release in just a few minutes.
- Join us in Slack for interactions with the broader YugabyteDB community and real-time discussions with our engineering teams.


