YugabyteDB 2.1 is GA: Scaling New Heights with Distributed SQL
February 25, 2020
Team Yugabyte is excited to announce the general availability of YugabyteDB 2.1! The highlight of this release is that Yugabyte SQL (YSQL), YugabyteDB’s PostgreSQL-compatible API, has not only improved performance 10x since the 2.0 release in September 2019 but is also production ready for multiple geo-distributed deployment scenarios. For those of you who are new to distributed SQL, YugabyteDB is a Google Spanner-inspired, cloud native distributed SQL database that is 100% open source. It puts a premium on high performance, data resilience, and geographic distribution while ensuring PostgreSQL wire compatibility.
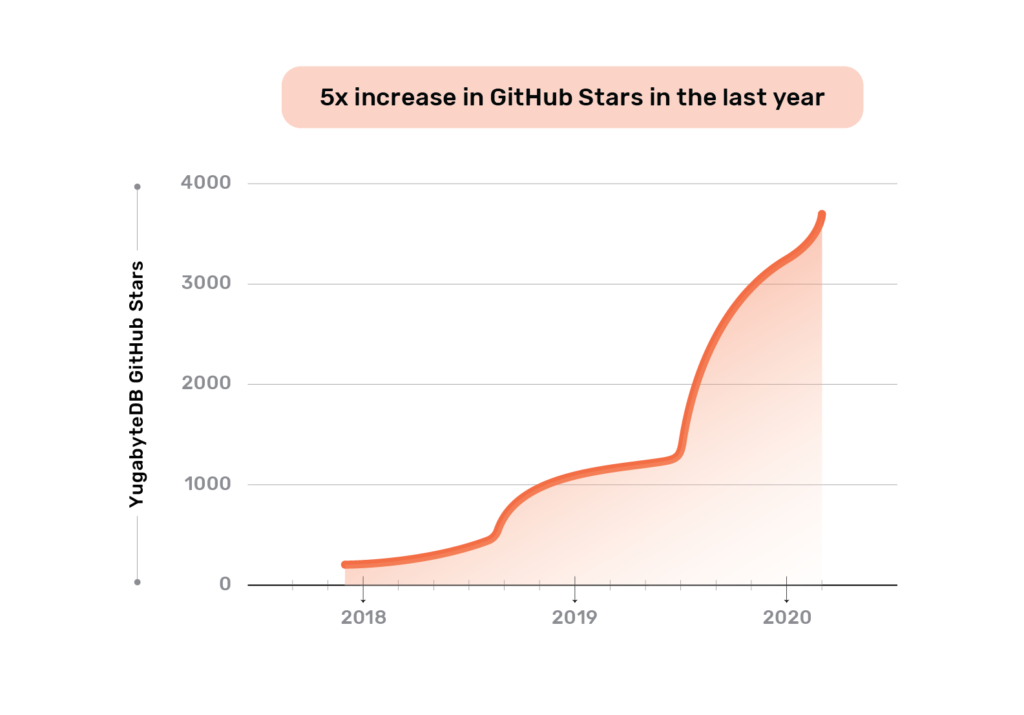
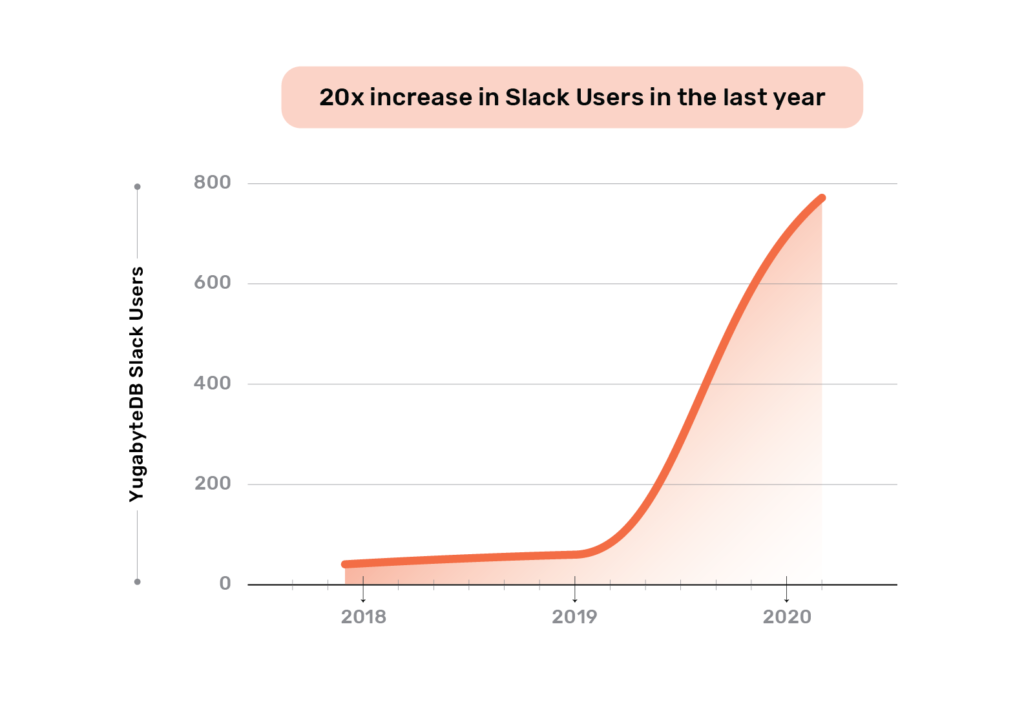
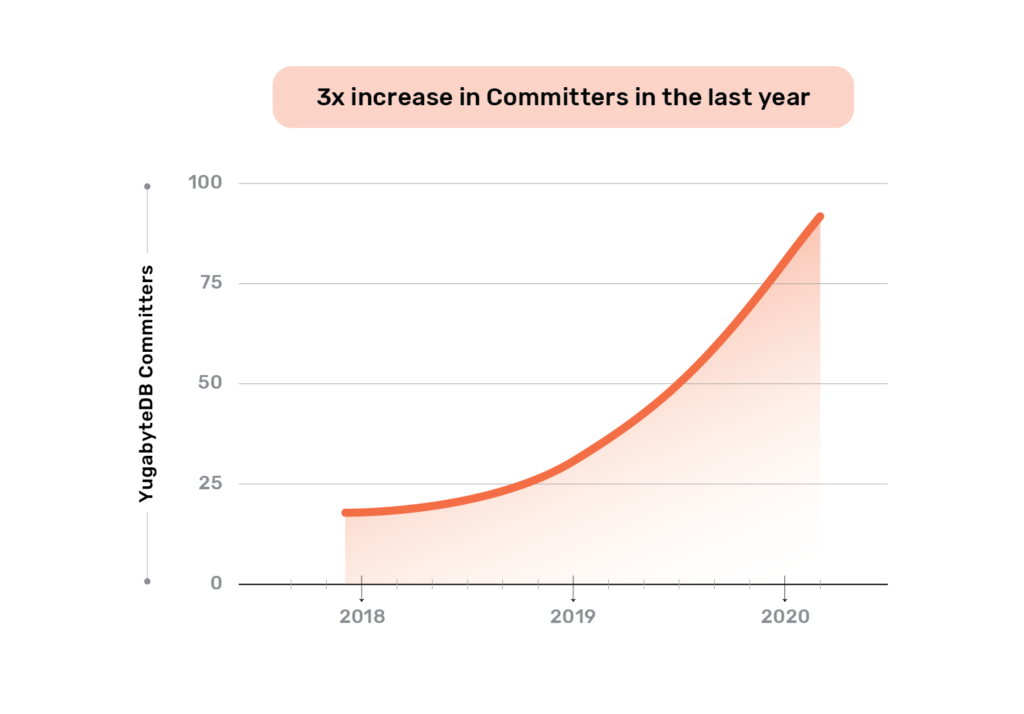
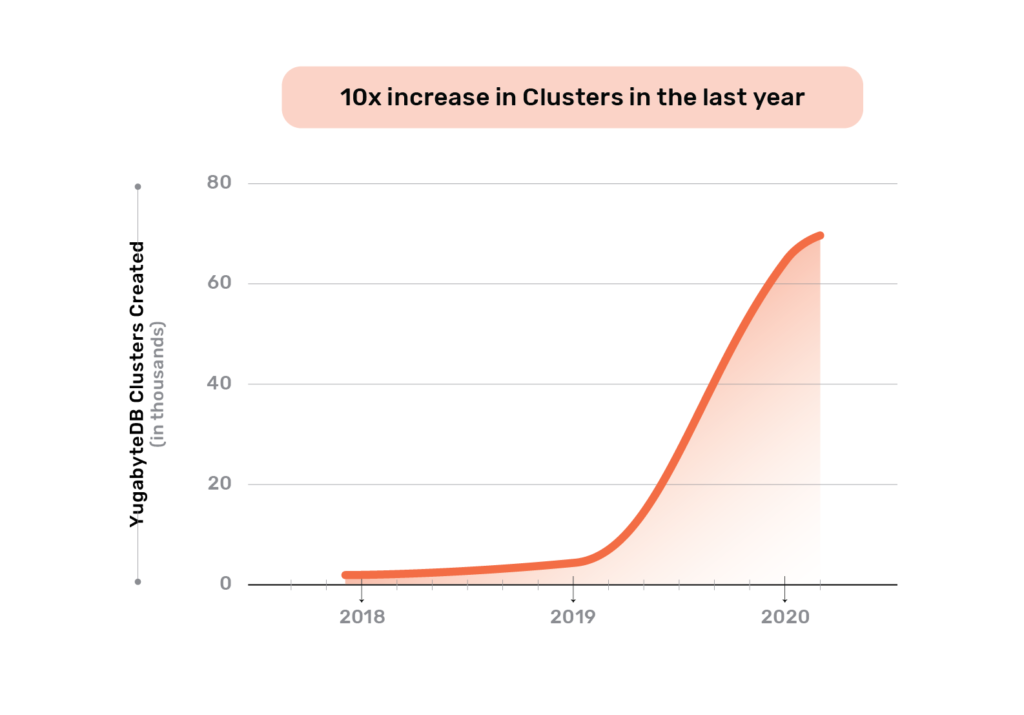
The operational DBMS industry has been experiencing the distributed SQL revolution over the last few years. Unlike specialized databases, distributed SQL appeals broadly to both startups and large enterprises looking to adopt cloud native technologies for their entire software stack which includes database infrastructure. Application development and operations teams are excited that they no longer give up the data modeling flexibility and transactional capabilities of SQL in the process of going cloud native. From our vantage point, YugabyteDB’s GitHub stars have grown 5x and community Slack users have grown 20x in the last year. And these users have created 10x more clusters in the same period. All the while, the committer base has also grown 3x. We attribute this explosive growth to distributed SQL getting widely recognized as the next “big thing” in RDBMS technology with YugabyteDB as the definition of such a technology.
In this post we’ll share what’s new in 2.1, performance benchmarks, and a preview of upcoming features currently in beta.
Summary of New YugabyteDB 2.1 Features
Here’s a summary of the new generally available and beta features in our latest release. All features are described in detail later in this post.
Generally available in release 2.1:
- 10x performance increase in Yugabyte SQL
- Geo-distributed, multi-cloud clusters
- Enterprise-grade security enhancements
In beta in release 2.1:
- Yugabyte Cloud as fully-managed DBaaS
- Colocated tables for reducing JOIN latency
- yugabyted for simplifying getting started UX
- Change Data Capture for streaming data out to external systems
- Distributed transactional backups (in progress)
Also new and noteworthy since our last release:
YugabyteDB 2.1 Generally Available Features in Detail
High Performance Meets Cloud Native
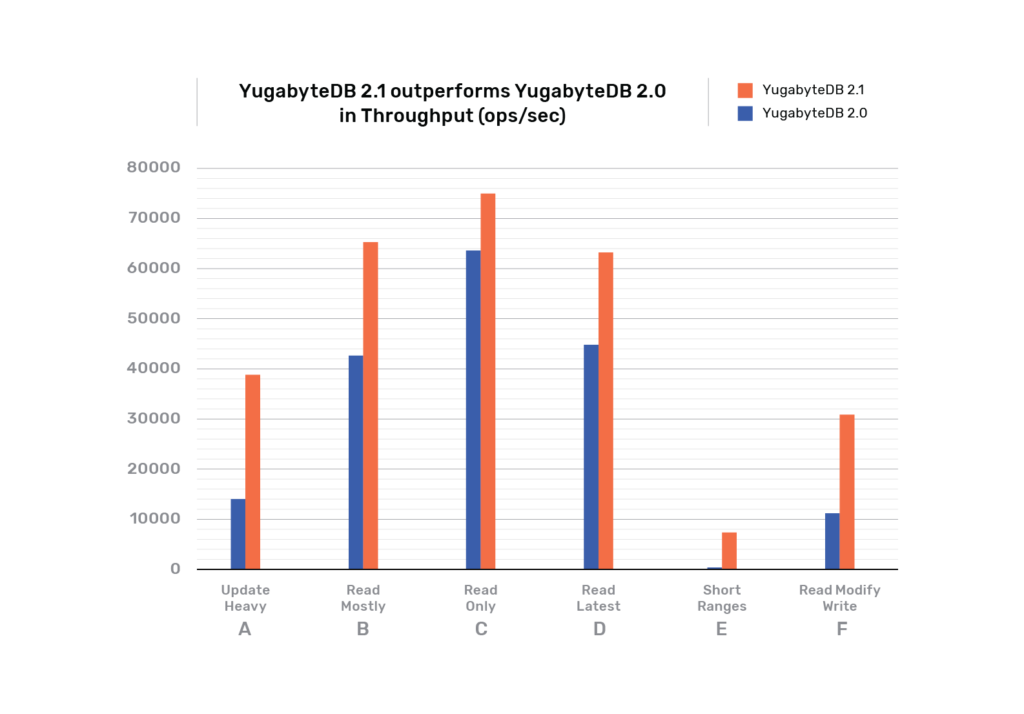
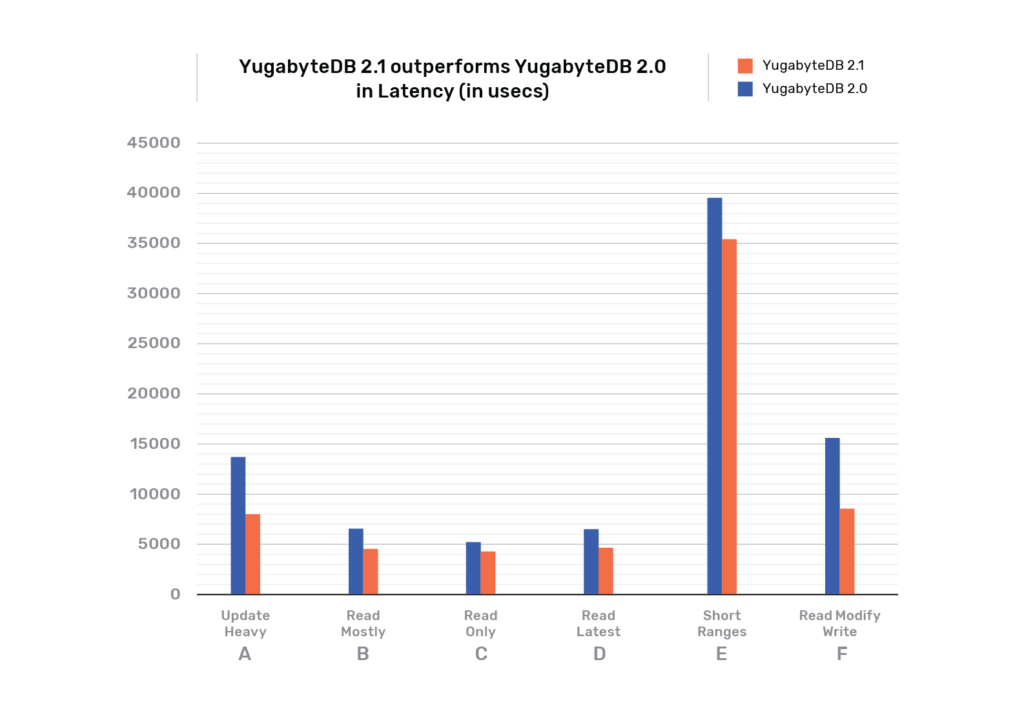
Bringing high-performance distributed SQL to cloud native architectures is the founding thesis of the YugabyteDB project. We are proud to highlight that the YugabyteDB 2.1 release is, on average, 10x better on the performance front than the 2.0 release as per the throughput and latency measurements from the 6 workloads in the YCSB benchmark. Multiple other enhancements have also gone into this release as detailed in the Achieving 10x Better Distributed SQL Performance in YugabyteDB 2.1 post.
YCSB
Yahoo! Cloud Serving Benchmark (YCSB) is a widely known benchmark for cloud databases. We ran YCSB tests against YugabyteDB 2.1 and 2.0 releases. Following are the throughput and latency results. The jump in YugabyteDB 2.1 performance can be attributed to a number of improvements to the SQL query processing and storage layers of the distributed database.
TPC-C
Another achievement in the 2.1 release is the ability to run the complete TPC-C suite. The following table shows the initial results of running the open source oltpbench TPC-C workload with 100 warehouses accessed by 64 terminals. We are actively working on enhancing our benchmark suite to follow all specifications of TPCC and get accurate performance numbers. YugabyteDB was running on a 3-node cluster using c5.4xlarge AWS instances, each with 16 CPU cores, 32GB RAM and 2 x 500GB gp2 EBS volumes.
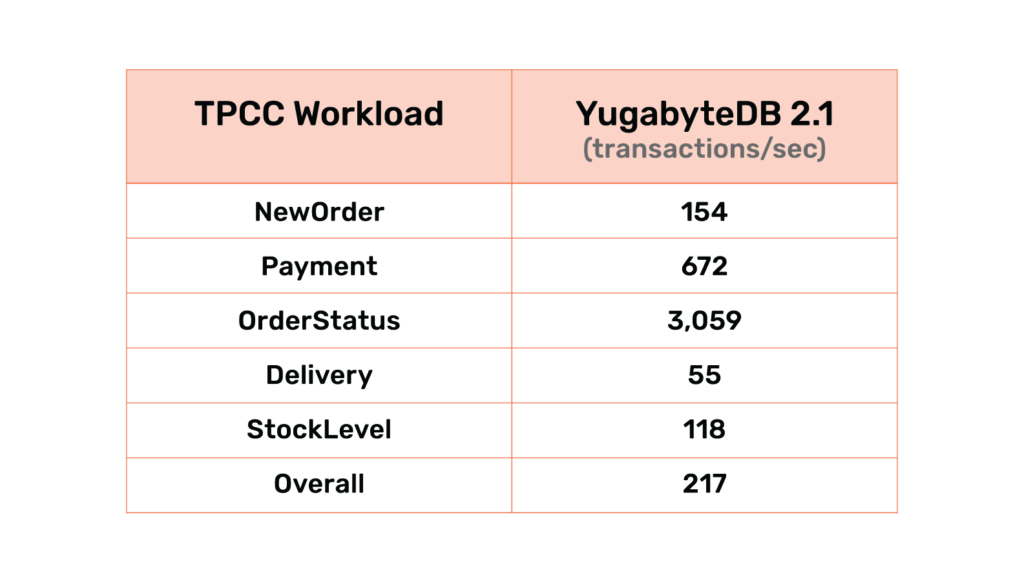
In the table above, “Overall” represents the transactions/sec when running a weighted mix (as per TPC-C specification) of all five transaction types (new order, payment, order status, delivery and stock level). The other rows represents the transactions/sec when running a transaction type individually.
Geo-Distributed, Multi-Cloud Clusters
YugabyteDB is a geo-distributed SQL database that can be easily deployed across multiple data centers and/or clouds. There are three primary configurations for such multi-DC and multi-cloud deployments. The first configuration–a globally consistent cluster–uses a single cluster stretched across 3 or more data centers with data getting automatically sharded across all data centers. This configuration is default for Spanner-inspired databases like YugabyteDB, and has been part of our distributed database since the beginning. Data replication across data centers is synchronous and is based on the Raft consensus protocol. This means writes are globally consistent and reads are either globally consistent or timeline consistent (when application clients use follower reads). Additionally, resilience against data center failures is fully automatic. However, this configuration has the potential to incur Wide Area Network (WAN) latency in the write path if the data centers are geographically located far apart from each other and are connected through the shared/unreliable Internet.
Two Data Center (2DC) Deployments for Reducing Write Latency
For applications not requiring global consistency and automatic resilience to datacenter failures, the above WAN latency can be eliminated altogether through a second configuration–a two data center deployment–where two independent, single-DC clusters are connected through asynchronous replication based on Change Data Capture. Both multi-master and master-follower configurations are supported. The 2.0 release introduced this feature in beta. We are excited that this feature is now generally available after getting hardened with additional features such as bootstrapping of new followers, one-master-to-many-followers/many-masters-to-one-follower configurations, TLS encryption, batched writes (for high throughput), automated WAL retention (based on replication lag), as well as metrics-driven monitoring. Detailed architectural overview and documentation are available to help you get started with this new feature.
Read Replicas for Reducing Read Latency
For applications with a global read pattern and local write pattern, a third configuration–read replicas–can be used. A single YugabyteDB universe can be divided into a primary cluster running in one data center and multiple read replica clusters each running in a different remote data center. The read replicas essentially work as Raft observer nodes that do not participate in the write path executed by nodes in the primary cluster. This approach allows reads in regions far away from the primary data center to be served by simply querying the read replica local to that region without any communication with the primary data center. Read replicas have been in beta for more than a year and we are pleased to inform you that they are now generally available starting in the 2.1 release. Yugabyte Platform, Yugabyte’s commercial self-managed DBaaS offering, makes creating and managing read replicas extremely easy and is documented here.
Enterprise-Grade Security
As a business-critical datastore, YugabyteDB has to protect data from malicious access. Features such as authentication, authorization and encryption are considered must-haves to build an enterprise-grade security posture. Building on our previous support for authentication and authorization, the YugabyteDB 2.1 release brings forth the important aspects of transparent data encryption (both at-rest and in-transit) and seamless key rotation.
Encryption at Rest & in Transit for Data Protection
Data at rest in the context of a transactional database refers to the permanent data files as well as the temporary write-ahead-log (WAL) files, all persisted on disk. YugabyteDB is able to encrypt these files using a single cluster key provided by the database administrator in a manner that is completely transparent to the application. It does so in the background as data gets flushed to disk and gets compacted thereafter. This also means that only newly-written data is encrypted while existing data in the cluster remains unaffected. It is recommended that this feature be turned on at cluster creation if encryption of all data stored in the cluster is desired.
Encryption in transit refers to the ability to encrypt data while it moves from the application client to the database server and then in between database servers. In the YugabyteDB context, this means encrypting data between the PostgreSQL-compatible app clients to YB-TServers and then doing the same for all communication across and in between YB-TServers and YB-Masters. The new server-to-server encryption feature is common across all distributed SQL APIs since it is handled at the DocDB layer of YugabyteDB. Additionally, YSQL client-to-server encryption is new in the 2.1 release.
KMS Integration for Seamless Key Rotation
The encryption keys and security certificates should be rotated periodically from a trusted source. YugabyteDB is itself agnostic to where these keys and certificates are acquired from. This is where Yugabyte Platform comes in with its integration with AWS KMS as well as Equinix Smart Key Service. Administrators can easily rotate the keys used for encryption by simply using the Yugabyte Platform API and UI.
The Road Ahead: YugabyteDB 2.1 Beta Features in Detail
What can you look forward to beyond YugabyteDB 2.1? Let’s take a look at some of the features now in beta.
Yugabyte Cloud as Fully-Managed DBaaS
Following our announcement last year in “Why We Changed YugabyteDB Licensing to 100% Open Source”, YugabyteDB remains a 100% Apache 2.0-licensed project even for enterprise features such as security and backups. Yugabyte’s commercial products focus only on database administration as opposed to the industry-standard practice of upselling proprietary database features. These commercial products come in two flavors–Yugabyte Platform, a management platform for building private YugabyteDB-as-a-Service offerings, and Yugabyte Cloud, a fully managed pay-as-you-go cloud service. Yugabyte Platform has been the primary offering since 2017 and has powered multiple success stories across key verticals. We are pleased to inform you that today we are adding Yugabyte Cloud to the portfolio. After a successful private beta over the last few months, Yugabyte Cloud is now available in public beta which includes the ability for any user to sign up for a free self-service tier.
Colocated Tables for Reducing JOIN Latency
The traditional RDBMS approach of modeling parent-child relationships as foreign key constraints can lead to high-latency JOIN queries in a geo-distributed SQL database. This is because the tablets (aka shards) containing the child rows may be hosted in nodes/zones/regions different than the tablets containing the parent rows. Colocated tables avoid this problem by sharing a single tablet across all the tables. Colocation can also be at the overall database level where all tables of a single database are located in the same tablet and hence are managed by the same Raft group. YugabyteDB 2.1 introduces database-level colocation as a beta feature. Tables that do not want to reside in the overall database’s tablet can override the feature at table creation time.
The natural question to ask is what happens when the tablet containing all the tables of a database becomes too big and starts impacting performance? The answer lies in automatic tablet splitting which is a work-in-progress feature that can be tracked on GitHub.
yugabyted for Simplifying Getting Started UX
YugabyteDB has traditionally relied on a 2-server architecture with YB-TServers managing the data and YB-Masters managing the metadata. However, this can introduce a burden to new users who want to get started right away without even understanding the underlying architecture. The 2.1 release introduces a new yugabyted server that acts as a parent server across YB-TServer and YB-Master. It also adds a new UI server (similar to the Yugabyte Platform UI) that allows users to experience a richer data placement map and metrics dashboard.
Change Data Capture
Change Data Capture (CDC) allows external clients to subscribe to modifications happening to the data in a database. This is a critical feature in a number of use cases, including the implementation of an event-driven architecture which uses a message bus (such as Apache Kafka) to propagate changes across multiple microservices. YugabyteDB’s CDC design is the first of its kind in the realm of distributed databases. Why? Because Yugabyte permits the continuous streaming of data without compromising on the foundational “global consistency” benefit that enables any node to process writes independent of other nodes and that too with full ACID guarantees. Instructions on how to stream data out to Apache Kafka or local stdout from a YugabyteDB 2.1 cluster can be found in the official documentation.
Distributed Transactional Backups
YugabyteDB backups come in two flavors today: snapshot-based backups that handle single-row transactions and full backups that essentially backup all committed data of a database. This means the only way to handle backups with multi-row transactions is to use full backups. However, full backups are expensive from a resource consumption standpoint. The snapshot-based backup approach is now being enhanced to handle multi-row transactions. This feature is currently in the design phase with progress getting tracked via GitHub.
Deep Ecosystem Integrations
No mission-critical software lives in a world of its own. Fortunately, YugabyteDB is compatible with and integrates with many popular technologies developers are already familiar with.
Powering Scalable, Geo-Distributed GraphQL Apps with Hasura
Modern consumer apps have users and data that are distributed all over the world. Cloud native patterns allow developers to even spread compute infrastructure globally. However, building these applications involves putting together a lot of different tools which makes it hard to move fast and slows down delivery. GraphQL has been gaining massive developer traction over the last couple years given that it simplifies such cloud native application development. When a GraphQL engine like Hasura is powered by a geo-distributed SQL database like YugabyteDB, developing massively-scalable, highly-resilient, low-latency, cloud native applications is easier than ever before. You can get started with Hasura on YugabyteDB today.
“Hasura plus YugabyteDB brings a new layer of scalability and fault tolerance to GraphQL services, helping to further accelerate and simplify the delivery of cloud native applications. Additionally, with the geo-distributed capabilities of YugabyteDB, we can now enable a best-of-breed approach to app development, specifically for high volume data sets in mobile, web and IoT apps. We’re excited to see how our users will take advantage of this partnership to build massively-scalable cloud native apps.”
— Tanmai Gopal, CEO of Hasura
Multi-Cloud Orchestration with Crossplane
YugabyteDB is now available as a self-managed database service on Crossplane, the open source multi-cloud control plane. Built on top of our recent Rook Kubernetes Operator for YugabyteDB, this offering makes YugabyteDB one of the first distributed SQL databases available on Crossplane. With Crossplane as the single control plane, users can provision and manage multiple YugabyteDB clusters across Google Kubernetes Engine, Amazon Elastic Kubernetes Service, and Azure Kubernetes Service with ease. The new addition gives applications a completely free in-cluster alternative to proprietary databases such as Google Cloud SQL, Amazon RDS Aurora, or Azure SQL DB. Unlike those monolithic SQL databases, YugabyteDB adds scalability, resilience, and geo-distribution capabilities to the data tier. You can get started with YugabyteDB on Crossplane today.
Integration with Multiple CNCF Projects
YugabyteDB now integrates with the following official CNCF projects:
- Graduated: Kubernetes, Prometheus, and Fluentd
- Incubating: Helm, Rook, and Falco
- Sandbox: Cortex, OpenEBS, and Longhorn
Look for updates in the coming days to the documentation and complementary how-to blog posts to go live related to these projects.
Community Momentum
Deep community engagement is the hallmark of any thriving open source project. The sense of belonging that users get by learning, sharing, and contributing their knowledge to the benefit of their fellow users is a unique feeling that proprietary products can never achieve. Given that the 2.1 release is the first major YugabyteDB release of 2020, it is an opportune time to review the community momentum behind this project. We are pleased to report that the YugabyteDB community experienced phenomenal growth over the last two years. After the original launch in November 2017, 2018 served as the year where users got an initial introduction to YugabyteDB. During 2019, users moved beyond this initial introduction and embraced the benefits of a 100% open source, cloud native, distributed SQL database wholeheartedly. We expect the momentum to accelerate in 2020 as releases like 2.1 are adopted widely by users.
GitHub Stars
Slack Users
Committers
Clusters Created
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner, and Amazon Aurora.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing, or to schedule a technical overview.
- We’re hiring! Check out our open positions and spread the word.


