YugabyteDB vs CockroachDB Performance Benchmarks for Internet-Scale Transactional Workloads
January 24, 2019
Enterprises building cloud native services are gravitating towards transactional NoSQL and globally distributed SQL databases as their next-generation transactional stores. There are at least two distinct usage patterns among these cloud native services – internet-scale transactional workloads and scale-out RDBMS workloads. They have a lot of common demands from the database they use, such as transactions/strong consistency, data modeling flexibility, ease of scaling out and fault tolerance. However, there are some notable differences between these workloads:
- Internet-scale transactional workloads are optimized for scale and performance without any compromises to data correctness. They often require high read/write throughput with low latencies and topology-aware operations (such as multi-master or reading from the nearest data center). In fact, Werner Vogels says in his blog that at Amazon.com, they “…found that about 70 percent of our operations were key-value lookups, where only a primary key was used and a single row would be returned”. Examples include audit trail, stock market data, shopping cart checkouts, messaging applications and a user’s order history. Joins are typically done in the application tier, or using a framework such as Apache Spark or Presto to prevent inefficient queries in the serving tier.
- Scale-out RDBMS workloads require query flexibility because the query pattern keeps evolving over time, and it is almost impossible to predict these ahead of time. These workloads typically require full RDBMS support and referential integrity, including the use of joins, views, stored procedures and so on. While these workloads demand scalability from the underlying databases as well, they typically deal with comparatively smaller data sizes. Examples of such services include CRM and ERP applications, supply chain management, billing services and various reporting applications.
In this post, we are benchmarking internet-scale transactional workloads. Since YugabyteDB and CockroachDB are both ideal databases for such workloads, they are being benchmarked side-by-side here. For this workload, the Yugabyte Cloud Query Language (YCQL) API in YugabyteDB is most ideally suited and hence is being used to benchmark.
In a nutshell, YugabyteDB delivers an average of 3.5x higher throughput and 3x lower latency compared to CockroachDB. Following are the detailed performance characteristics at scale (millions of rows) for internet-scale transactional workloads:
- 5x more insert throughput, 9x faster
- 4x more query throughput, 3x faster
- 4x more distributed transactions throughput
- In addition, YugabyteDB offers additional features such as read replicas (for timeline-consistent, low-latency reads from the local region) and automatic data expiry (by setting a TTL at table level or row level).
If your application has any of the following requirements, you should consider YugabyteDB over CockroachDB:
- High write operations per second: In other words, these applications have to deal with a lot of data. In fact, the total dataset is either ever growing, or older data is purged from the database to keep data growth under control.
- Low latency reads: Put another way, adding nodes to the database cluster should improve read performance.
- Geographically distributed deployments: This often requires features such as topology-aware smart clients that enable writing/reading from nearest region and ability to create read replicas.
Download the in-depth benchmarking paper or register for the “YugabyteDB vs CockroachDB: Architecture, Features and Performance Benchmarks” webinar on Feb 28th. In this webinar will present the results of round 2 of our benchmarks where we look at scale-out RDBMS workloads using the PostgreSQL-compatible YSQL API.
Benchmark Setup
The following workload patterns, which form some of the fundamental building blocks for internet-scale transactional workloads, are being benchmarked here. See the benchmark suite GitHub repo. Below is a short description of these different tests.
- Inserts: Insert 50 Million unique key-values using at least 256 threads (each representing a real world client) running in parallel.
- Queries: Query the previously written 50 Million unique key-values using a number of concurrent clients.
- Distributed Transactions: In this benchmark, each transaction updates two random key values. The isolation level is set to Snapshot Isolation since there are no read-write conflicts in this workload pattern.
- Updates and Queries: A mixed read and write workload where the previously written values are updated. In this benchmark, there were 64 writers and 128 readers.
- Secondary Index Inserts: Insert 5 Million unique key-values into a database table with a secondary index enabled on the value column using the maximum possible concurrency. This internally exercises the distributed transactions feature (at least with Snapshot Isolation level).
- Secondary Index Queries: Query the previously written 5 Million unique key-values from the database. Each query uses a random value to look up the key, exercising the secondary index feature.
Schema Details
For each of these workloads, the underlying table is a simple two-column table (one key column and a value column). Each row in the table is a simple key-value entry with a combined size of about 64 bytes. The table below shows the schema of the tables for each of the databases.

Also, here are some points about the test setup:
- The databases were brought up on the exact same nodes.
- The benchmark program was run from a separate machine in one of the zones.
- All queries use prepare-bind statements to improve performance on both DBs.
- The IOPS and latencies reported in this benchmark are client-observed.
Versions Tested
- YugabyteDB v1.1.0, released Sept 2018
- CockroachDB v2.1.3, released Dec 2018
Hardware and Cluster Configuration
- Three AWS i3.4xlarge type nodes (16 vCPUs, 122 GB RAM, 2 x 1.9TB SSD disks)
- Disks mounted using XFS filesystem
- Both clusters had their Replication Factor set to 3
- Both clusters used a multi-availability zone configuration that spanned 3 zones
Inserts: 5x more throughput, 9x faster
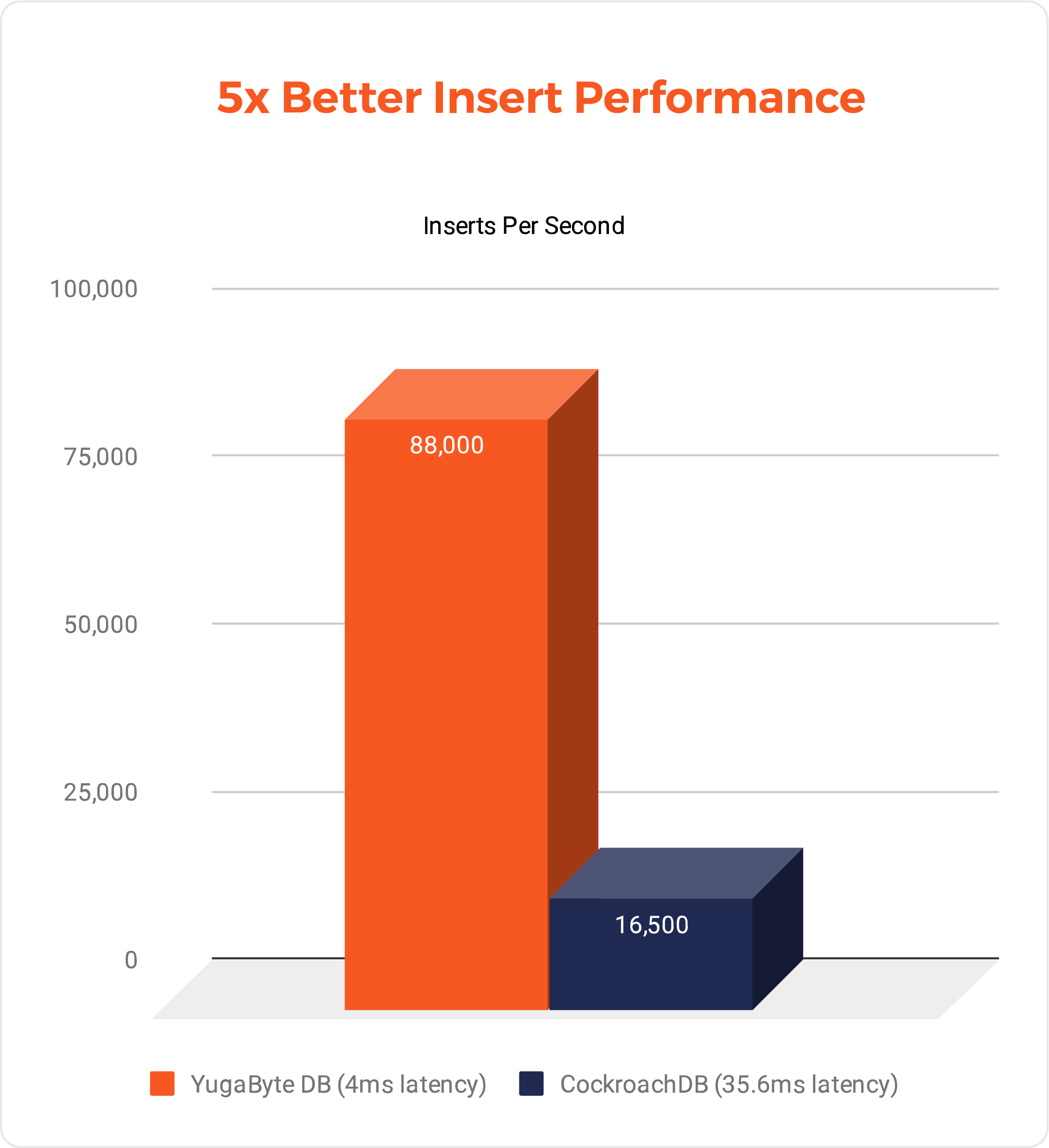
In many internet-scale applications, data needs to be written with high concurrency. For example, a shopping cart e-commerce application that needs to support high volume peak/holiday traffic hitting the database from several concurrent clients. In this test, we insert 50 Million unique key-values using at least 256 writer threads running in parallel. To simplify the analysis, there are no reads against the database during this period.
YugabyteDB did 88K writes/sec compared to 16.5K writes/sec by CockroachDB, which is 5x more. The average latency of YugabyteDB was 4ms compared to 35.6ms by CockroachDB, making it 9x faster.
The table below summarizes some of the key details of the test.
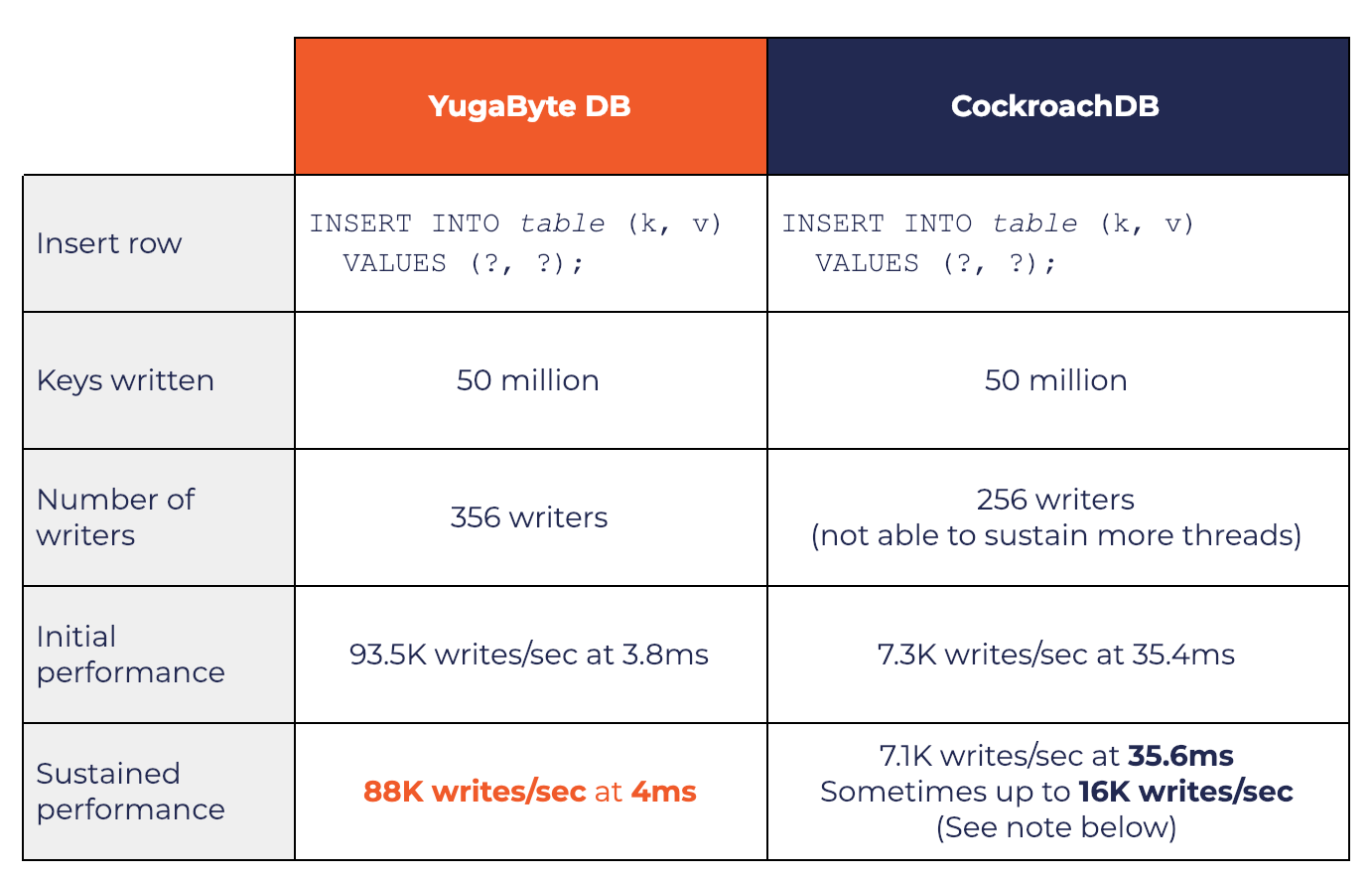
Note that the sustained write performance results for CockroachDB (last row, third column) yielded different results during various runs, hence we are reporting multiple numbers but picking the larger 16K value. The latest run against the 2.1.3 version yielded a constant 7.1K writes/sec while a previous run against the 2.0.6 version yielded 16K writes/sec. In both cases, the CockroachDB ranges were evenly balanced across the various nodes in the cluster.
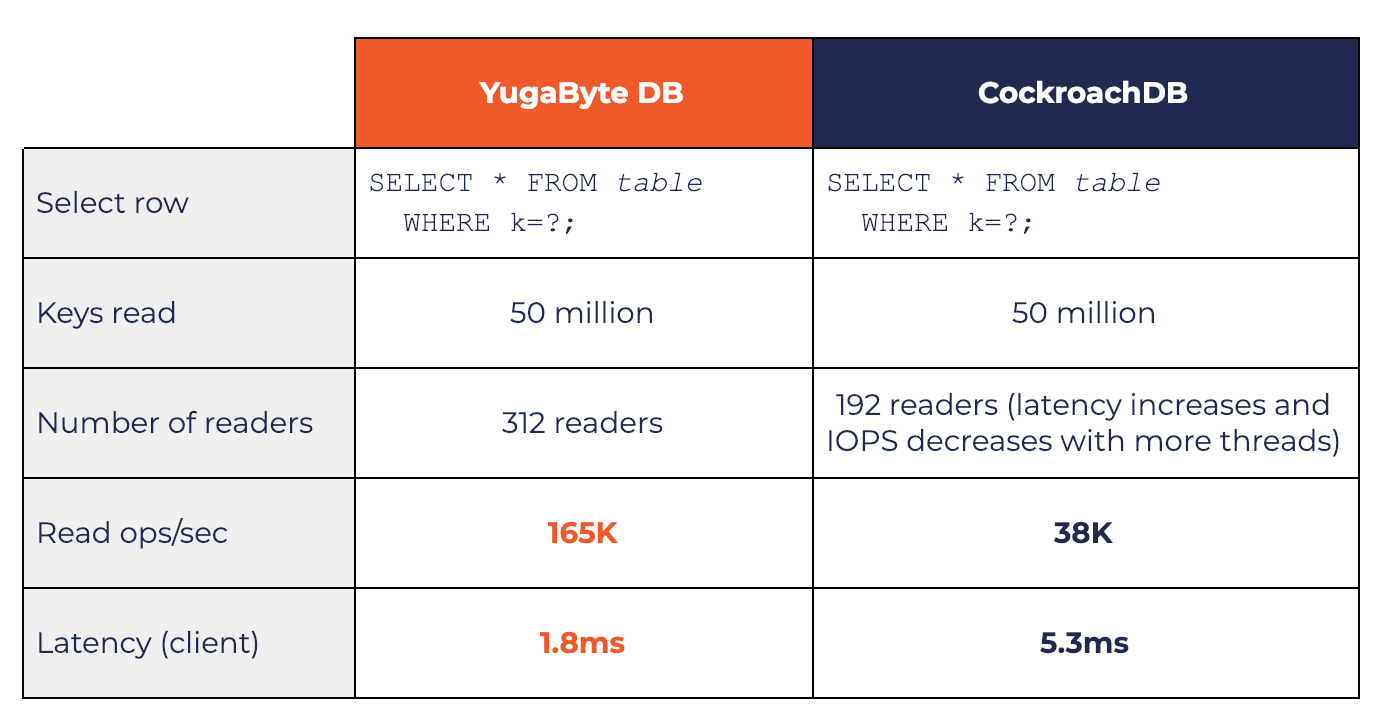
Queries: 4x more throughput, 3x faster
Just as in the case of the inserts test above, the need for low-latency queries concurrently from many clients is very common, especially in cloud-native applications. In this test, we query at random the 50 Million unique key-values inserted in the previous benchmark using at least 256 reader threads running in parallel.
YugabyteDB did 165K writes/sec compared to 38K writes/sec by CockroachDB, which is 4x more. The average latency of YugabyteDB was 1.8ms compared to 5.3ms by CockroachDB, making it 3x faster.
The table below summarizes some of the key details of the test.
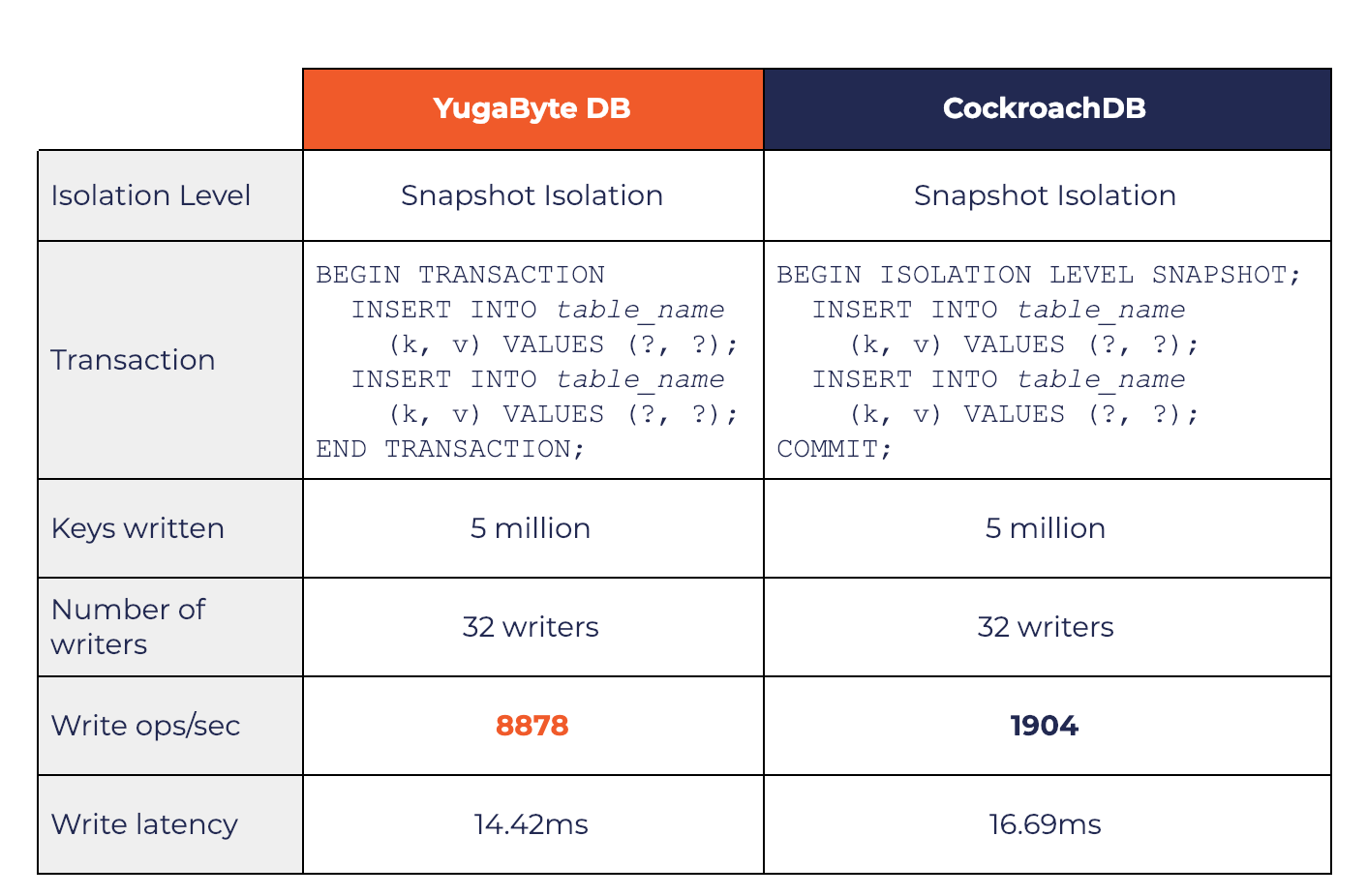
Distributed Transactions: 4x more throughput
Distributed transactions are very critical to building online applications. In fact, the secondary index feature often exercises distributed transactions internally. In this test, each transaction updates two random key values. Once again, there are no other operations on the database when this test is running.
YugabyteDB delivered 8.8K transactions/second compared to 1.9K writes/second by CockroachDB. This translated into 4x better throughput with YugabyteDB.
The table below summarizes some of the key details of the test.
Other Results
In addition to the above tests, the following benchmark tests were also performed:
- A mixed workload with updates and queries running simultaneously
- Secondary index inserts, followed by queries exercising the index
To see these results, you can download the detailed report, “Benchmarking YugabyteDB vs CockroachDB for Internet-Scale Transactional Workloads” or register for Feb 28th webinar for an in-depth analysis, as well as, the opportunity to ask questions.
What’s Next?
- Read the in-depth comparison and benchmarks.
- Get started with YugabyteDB on macOS, Linux, Docker or Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


