YugabyteDB High Availability and Transactions for PostgreSQL and MongoDB Developers
March 5, 2019
This post is a deeper dive into the high availability and transaction architecture of these MongoDB and PostgreSQL databases, comparing them to YugabyteDB.
High Availability
Almost all databases including YugabyteDB use replication to ensure that the database remains highly available under failures. The basic idea is to keep copies of data on independent failure domains so that loss of one domain does not lead to data loss or data unavailability from the application client standpoint. However, the key differences lie in the constraints of the replication solution for each database. The table below summarizes some of the key differences. ![]()
The above table can be summarized as:
YugabyteDB requires one more node to commit a write than PostgreSQL and same number of commits as MongoDB but in return gives the benefits of high availability (with automatic failover) and low latency reads simultaneously. Note that neither PostgreSQL nor MongoDB can guarantee this critical combination of benefits. Let’s look under the hood of both of them to understand why.
PostgreSQL vs. YugabyteDB
![]()
PostgreSQL Replication (Source: Packt Publishing)
The most common replication mechanism in PostgreSQL is that of asynchronous replication. Two completely independent database instances are deployed in a master-slave configuration in such a way that the slave instances periodically receive committed data from the master instance. The slave instance does not participate in the original writes to the master, thus making the latency of write operations low from an application client standpoint. However, the true cost is loss of availability (until manual failover to slave) as well as inability to serve recently committed data when the master instance fails (given the data lag on the slave). The less common mechanism of synchronous replication involves committing to two independent instances simultaneously. It is less common because of the complete loss of availability when one of the instances fail. Thus, irrespective of the replication mechanism used, it is impossible to guarantee always-on, strongly consistent reads in PostgreSQL.
YugabyteDB is designed to solve the high availability need that monolithic databases such as PostgreSQL were never designed for. This inherently means committing the updates at 1 more independent failure domain than compared to PostgreSQL. Let’s review how YugabyteDB does this in a bit more detail.
As highlighted in our previous post, there is no overall “leader” node in YugabyteDB that is responsible for handing updates for all the data in the database. There are multiple shards and those shards are distributed among the multiple nodes in the cluster. Each node has some shard leaders and some shard followers. Serving writes is the responsibility of a shard leader which then uses Raft replication protocol to commit the write at at least 1 more follower replica before acknowledging the write as successful back to the application client. When a node fails, some shard leaders will be lost but the remaining two follower replicas (on still available nodes) will elect a new leader automatically in a few seconds. Note that the replica that had the latest data gets the priority in such an election. This leads to extremely low write unavailability and essentially a self-healing system with auto-failover characteristics.
Most distributed databases do a quorum read to serve more consistent data but increase the latency of the operation since a majority of replicas located in potentially geo-distributed nodes now have to coordinate. YugabyteDB does not face this problem since it can serve strongly consistent reads directly from the shard leader without any quorum. It achieves this by implementing the notion of leader-leases to ensure that even in case a new leader is elected for a shard, the old leader doesn’t continue to serve potentially stale data. Serving low latency reads for internet-scale OLTP workloads thus becomes really easy.
MongoDB vs. YugabyteDB
MongoDB has been slowly evolving its high availability architecture since its inception as a monolithic database with only master-slave replication in the 1.0 release (2009). The Replica Set was introduced as a high availability concept in the 2.0 release (2011). Thereafter, it solved the primary auto-election problem using Raft starting the 3.4 release (2016) but has maintained an asynchronous replication approach when it comes to the actual data moving from the primary to the secondary members. Sharded Clusters are essentially a collection of Replica Sets that can be operated together.
![]()
MongoDB Replica Set
Assuming that all writes to the database are performed with majority writeConcern, MongoDB clients needing strongly consistent reads still have to query the database with linearizable readConcern which initiates a quorum among the replicas (since the secondary members may not have the latest data and the primary may not be available). This is because of the asynchronous data replication architecture MongoDB follows. The end result is high latency that can easily lead to dissatisfied application end-users.
As highlighted in the previous section, YugabyteDB is built for high availability and absolute consistency at the same time. The benefit of synchronously replicating a write to at least a 2 of 3 nodes in a cluster is not simply automatic failover but also low latency strongly-consistent reads.
ACID Transactions
ACID transactions are often mistakenly thought of as the multi-shard (aka distributed) kind only. However, the reality is more nuanced especially in the context of distributed databases. Our Primer on ACID Transactions highlights why internet-scale applications should take a fresh look at transactional guarantees in a distributed database. It is important for a developer to understand transactions in distributed databases at a finer detail. As shown in the table below, starting with YugabyteDB, PostgreSQL and MongoDB can be a good start.
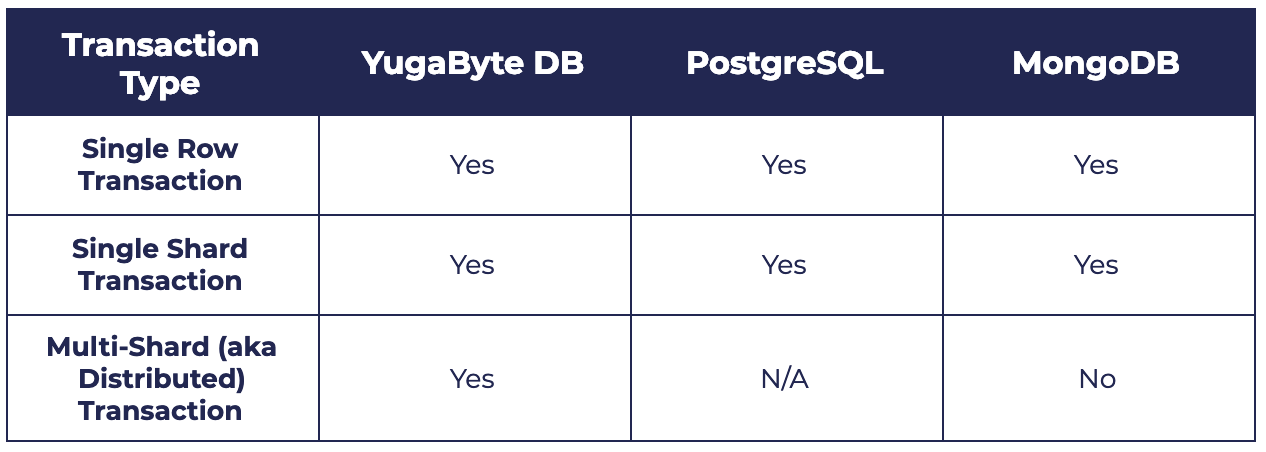
PostgreSQL can be thought of as a single-shard database which means it supports for single row (e.g. an INSERT statement) and single shard transactions (e.g. database operations bounded by BEGIN TRANSACTION and END TRANSACTION). The notion of multiple shards is not applicable to PostgreSQL and as a result, multi-shard transactions too are not applicable.
Coming to MongoDB, it is fair to say that transactions in MongoDB have gone through a long evolution similar to its high availability architecture. From its easy-to-lose-data roots, MongoDB first evolved to a single-row ACID database and then became a single-shard ACID database in the last major release. However, leveraging single-shard transactions in MongoDB come with a few high cost penalties such as lack of horizontal scalability and poor performance. “Are MongoDB’s ACID Transactions Ready for High Performance Applications?” details the underlying design issues.
Neither of PostgreSQL and MongoDB support distributed transactions that commit data on multiple shards located on multiple nodes in an ACID compliant manner. On the other hand, YugabyteDB takes inspiration from Google Spanner, Google’s globally distributed database, and supports all the 3 flavors of transactions. As described in “Yes We Can! Distributed ACID Transactions with High Performance”, it is designed to ensure the single row/shard transactions can be served with lowest latency possible while the distributed transactions can be served with absolute correctness.
Summary
PostgreSQL is great for small-scale relational apps but is not a good fit for use cases that require either horizontal write scalability or geo-distribution across multiple regions. Similarly, MongoDB is great for small-scale flexible-schema apps but is a misfit for use cases that simultaneously require massive write scalability, low latency reads and multi-shard transactions. As a high-performance distributed SQL database, YugabyteDB brings together the best of PostgreSQL and MongoDB (NoSQL) into a single database.
What’s Next?
- Read the first post of our series comparing YugabyteDB with PostgreSQL and MongoDB, we mapped the core concepts in YugabyteDB to the two popular databases.
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


