YugabyteDB 1.1 New Feature: Speeding Up Queries with Secondary Indexes
September 25, 2018
Welcome to another post from our ongoing series where we highlight a new feature from the latest 1.1 release! Today we are going to look at secondary indexes.
Defining Secondary Indexes
A database index is a data structure that improves the speed of data retrieval operations on a database table. Typically, databases are very efficient at looking up data by the primary key. A secondary index can be created using one or more columns of a database table, and provides the basis for both rapid random lookups and efficient access of ordered records when querying by those columns. To achieve this, secondary indexes require additional writes and storage space to maintain the index data structure.
The Benefits of Secondary Indexes
Secondary indexes can be used to speed up queries and to enforce uniqueness of values in a column.
Speed up Queries
The predominant use of a secondary index is to make lookups by some column values efficient. Let us take an example of a users table, where user_id is the primary key. Suppose we want to lookup user_id by the email of the user efficiently. You can achieve this as follows.
cqlsh> CREATE KEYSPACE example;
cqlsh> CREATE TABLE example.users(
user_id bigint PRIMARY KEY,
firstname text,
lastname text,
email text
) WITH transactions = { 'enabled' : true };
cqlsh> CREATE INDEX user_by_email ON example.users (email)
INCLUDE (firstname, lastname);Next let us insert some data.
cqlsh> INSERT INTO example.users (user_id, firstname, lastname, email)
VALUES (1, 'James', 'Bond', 'bond@yb.com');
cqlsh> INSERT INTO example.users (user_id, firstname, lastname, email)
VALUES (2, 'Sherlock', 'Holmes', 'sholmes@yb.com');You can now query the table by the email of a user efficiently as follows.
cqlsh> SELECT * FROM example.users WHERE email='bond@yb.com';
Read more about using secondary indexes to speed up queries in this quick guide to YugabyteDB secondary indexes.
Enforce Uniqueness of Column Values
In some cases, you would need to ensure that duplicate values cannot be inserted in a column of a table. You can achieve this in YugabyteDB 1.1 by creating a unique secondary index, where the application does not want duplicate values to be inserted into a column.
cqlsh> CREATE KEYSPACE example;
cqlsh> CREATE TABLE example.users(
user_id bigint PRIMARY KEY,
firstname text,
lastname text,
email text
) WITH transactions = { 'enabled' : true };
cqlsh> CREATE UNIQUE INDEX unique_emails ON example.users (email);Inserts would succeed as long as the email is unique.
cqlsh> INSERT INTO example.users (user_id, firstname, lastname, email)
VALUES (1, 'James', 'Bond', 'bond@yb.com');
cqlsh> INSERT INTO example.users (user_id, firstname, lastname, email)
VALUES (2, 'Sherlock', 'Holmes', 'sholmes@yb.com');But upon inserting a duplicate email, we get an error.
cqlsh> INSERT INTO example.users (user_id, firstname, lastname, email)
VALUES (3, 'Fake', 'Bond', 'bond@yb.com');
InvalidRequest: Error from server: code=2200 [Invalid query] message="SQL error: Execution Error. Duplicate value disallowed by unique index unique_emailsHow do Secondary Indexes Work in YugabyteDB?
Secondary indexes in YugabyteDB depend on distributed transactions. They have the following properties:
- Fully decentralized with no single point of failure. This makes the cluster resilient to various faults when running a workload that utilizes secondary indexes.
- Linear scalability to enable increasing the throughput/IOPS on demand by simply adding more nodes into the cluster.
- ACID compliant to ensure always correct results. This means that the primary table and the index table are always in sync.
- High performance since the index table supports efficient point-queries when looking up by the indexes columns. In addition, you can include additional columns (sometimes referred to as COVERING columns) into the index to further increase performance.
- Multiple indexes per table are supported to enable use-cases that need to optimize lookups by multiple columns.
The data for each secondary index is an internal table in YugabyteDB. The index tables are sharded into tablets, internally replicated and distributed across nodes much like user tables. When data is inserted or updated into the table, YugabyteDB internally uses a distributed ACID transaction to update both the primary table and all its secondary index tables.
To illustrate the above point, let us take the simple example of a key-value table with an index on the value.
cqlsh> CREATE KEYSPACE example;
cqlsh> CREATE TABLE example.key_value(
key text PRIMARY KEY,
value text
) WITH transactions = { 'enabled' : true };
cqlsh> CREATE INDEX value_idx ON example.key_value (value);Now let us insert a row into this table.
cqlsh> INSERT INTO example.key_value (key, value) VALUES ('k', 'v1');This effectively results in the following sequence internally.
BEGIN INTERNAL TRANSACTION
INSERT INTO key_value ('k', 'v1');
INSERT INTO value_idx ('v1', 'k');
END INTERNAL TRANSACTION;The high level flow for the above internal transaction is shown below.
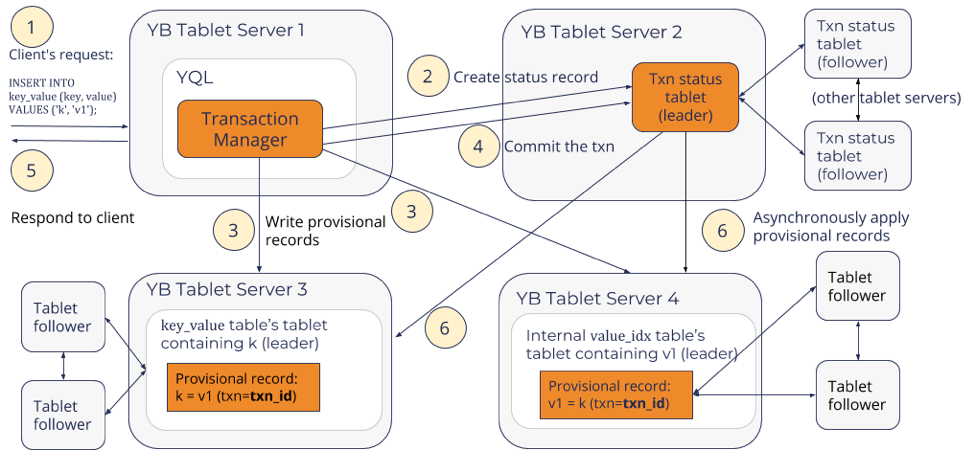
The above ensures that both the tables get updated atomically. Querying by the key reads from the key_value table, while querying by the value would read from the value_idx table.
Next let us update this row.
cqlsh> UPDATE example.key_value SET value='v2' WHERE key='k';
The above update is equivalent to the following internal transaction.
BEGIN INTERNAL TRANSACTION
UPDATE IN key_value ('k', 'v2');
DELETE FROM value_idx ('v1', 'k');
INSERT INTO value_idx ('v2', 'k');
END INTERNAL TRANSACTION;Note that value_idx’s tablet for v1 and tablet for v2 may be on different nodes altogether, hence the need to delete the old row as well as insert the new row. The above flow diagram will now include updates to the tablet-leader for v2. This highlights the need for database that handles such cases in a manner that is completely transparent from the application developer.
We can verify the update by running the following queries.
cqlsh> SELECT * FROM example.key_value; key | value -----+------- k | v2 (1 rows) cqlsh> SELECT * FROM example.key_value WHERE value='v1'; key | value -----+------- (0 rows) cqlsh> SELECT * FROM example.key_value WHERE value='v2'; key | value -----+------- k | v2 (1 rows)
What’s Next?
- Read the reference docs on using secondary indexes in YugabyteDB.
- Read the YugabyteDB 1.1 technical deep dive to catch up on all the new features.
- Get started with YugabyteDB on the cloud or container of your choice.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


