YugabyteDB 1.0 — A Peek Under The Hood
May 21, 2018
Modern user-facing apps, like E-Commerce and SaaS, frequently require features from multiple databases (broadly — SQL, NoSQL and a cache) to support their multi-workload needs. App developers are responsible for understanding and managing which pieces of data should be stored in which SQL and NoSQL database. Furthermore, the app is also responsible for moving data across the tiers (e.g. populating the cache on reads and invalidating it on writes). This greatly increases development and operational complexity, and hampers feature rollout agility.
YugabyteDB simplifies these problems by eliminating the need for multiple databases. It has been built ground-up over the last 2+ years with the 5 design principles.
- Transactional Consistency
- High Performance
- Planet-Scale
- Cloud Native
- Open Source Core with Open APIs
Recently, we announced the general availability of the production-ready 1.0 release. Customers running this release in production are already benefiting from higher development and operational agility that resulted from the simplification of their business-critical database tiers. This post dives into the capabilities of YugabyteDB 1.0 as it relates to the 5 design principles.
1. Transactional Consistency
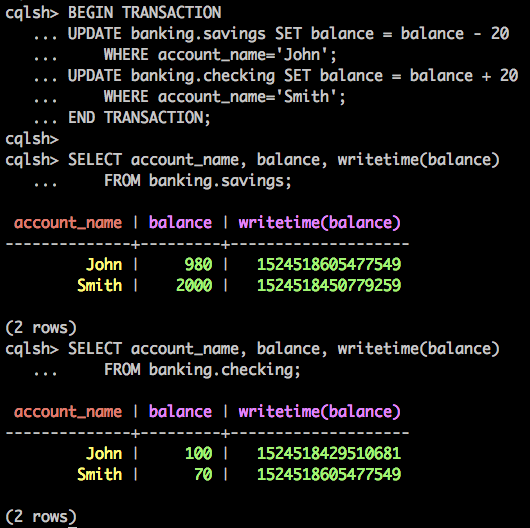
YugabyteDB is a strongly consistent database built on a key-to-document storage engine with support for single row and distributed ACID transactions. As described in “Yes We Can! Distributed ACID Transactions with High Performance”, it uses a number of techniques to ensure low latency and high throughput while remaining fully ACID compliant. It does not require atomic clocks to ensure correctness and can even leverage external atomic clock services (e.g. AWS Time Sync) to decrease conflict resolution latencies.
Secondary indexes in YugabyteDB are implemented on top of distributed ACID transactions to allow for efficient querying by columns/attributes that are not a part of the primary key.
YugabyteDB also supports a native
Finally, we have implemented a Jepsen test suite to verify the correctness of various features under a variety of fault scenarios. Stay tuned for a detailed update on this front soon.
2. High Performance
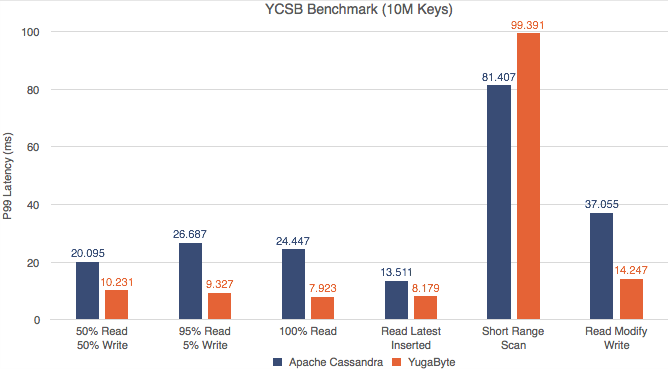
We compared the latency and throughput of YugabyteDB against Apache Cassandra using the YCSB benchmark, and found it to be outperforming Cassandra for all the 6 core workloads in the YCSB suite. Another experiment demonstrated YugabyteDB’s ability to serve data from disk under 1 millisecond in a public cloud setup. Additionally, YugabyteDB can also serve millions reads and writes, with read latencies around 200 microseconds.
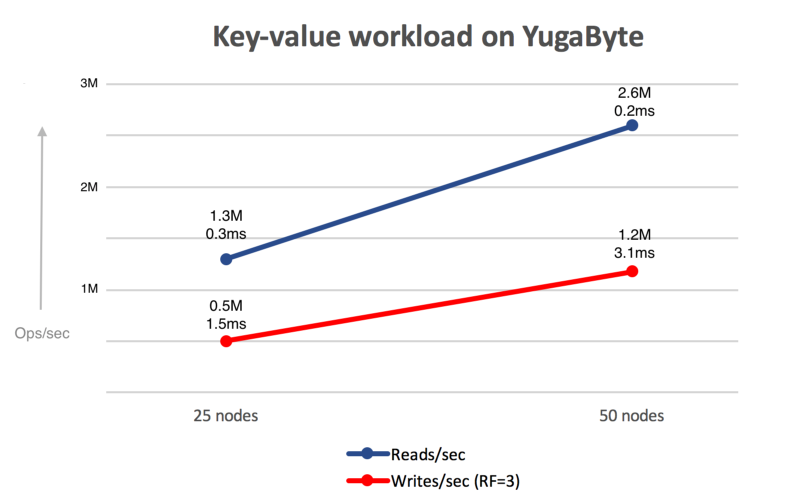
Improving performance of any software is a continuous journey. We have been steadily improving the performance of YugabyteDB, and will continue to do so in the future releases.
3. Planet Scale
YugabyteDB is ideal for a variety of multi-zone, multi-region, hybrid cloud and multi-cloud deployment options. Some of the common deployment options are listed below.
Multi-Zone and Multi-Region
In the multi-zone deployment illustrated below, the database replicates data across multiple zones (typically 3) inside a single region in order to be resilient to zone failures. However, this configuration is not tolerant against failure of the region.
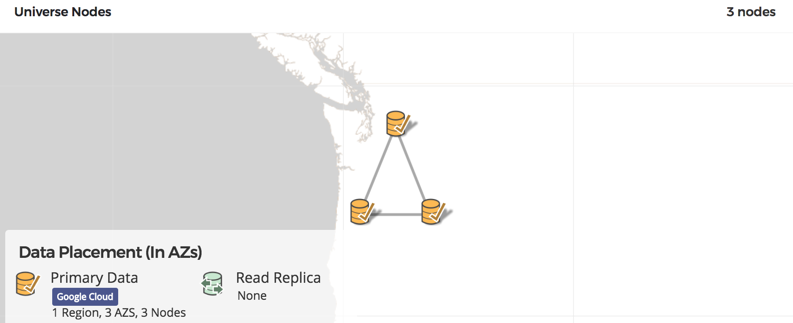
For applications needing region-level fault tolerance as well as low latency (by keeping a copy of the data close to the users), fully geo-distributed multi-region clusters (with global consistency across all the nodes) is recommended.

Additionally, the YugabyteDB Enterprise Edition makes it trivial to comply with regulatory requirements such as GDPR by ensuring that data remains local to its geographic region when required.
Hybrid Cloud and Multi-Cloud

With our 1.0 release, it is very easy to run hybrid and multi-cloud deployments. Hybrid cloud deployments have some nodes running on-premises and some nodes running in a public cloud in the context of a single database cluster. On the other hand, multi-cloud deployments enable different clusters to run in different clouds in addition to supporting a single database cluster to span multiple clouds.
Read Replicas

A common requirement for globally distributed applications is to simultaneously support low latency, high throughput writes and timeline-consistent, low latency reads (powered by copies of data replicated asynchronously to remote regions). Read replicas are the perfect solution for this use case. Read replicas in YugabyteDB are achieved by extending the underlying Raft consensus protocol to support observer nodes.
4. Cloud Native

There are a number of features that make YugabyteDB a cloud native database. It is elastic, meaning it is possible to add/remove nodes to achieve linear scalability. It is fault-tolerant, meaning the database survives failures of underlying infrastructure such as nodes, disks, networks without compromising data correctness. We can even completely reconfigure the database without any application downtime, thus enabling complex infrastructure portability scenarios such as migrating to new hardware or new region or even a new cloud platform.
YugabyteDB runs on any infrastructure layer — bare metal, virtual machines and containers. It also runs on any Infrastructure-as-a-Service provider — be it on-premise in private clouds, in public clouds or on container orchestration engines such as Kubernetes and Docker Swarm.
5. Open Source Core with Open APIs

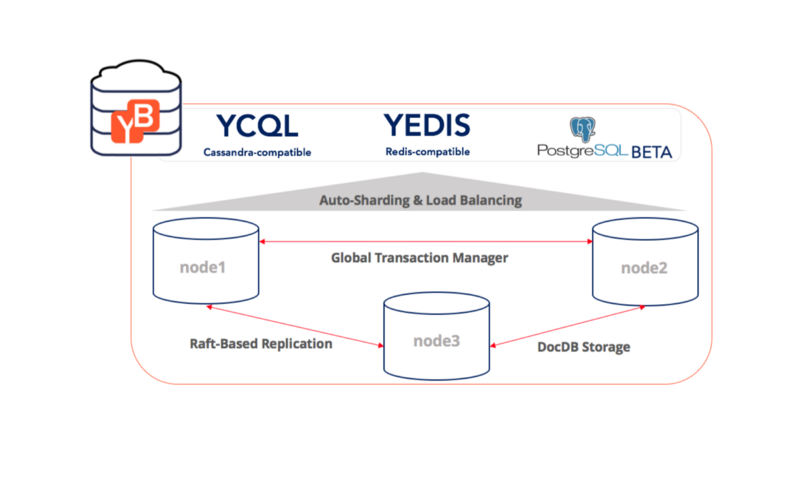
YugabyteDB is open sourced under Apache 2.0 license, and therefore embraces open source with the most easy-to-adopt license. Furthermore, it is a multi-model database with multiple open APIs:
- YCQL — compatible with Cassandra Query Language, used for modeling flexible schema workloads.
- YEDIS — compatible with the Redis commands library, used for modeling key-value workloads.
- PostgreSQL — compatible with the SQL language in PostgreSQL, used for modeling relational workloads.
By bringing together widely popular APIs and data models into one database, we hope to make it easy to get started with YugabyteDB and greatly simplify application development.
What’s Next?
We are grateful for the trust shown by the users who have chosen YugabyteDB to power their business-critical applications. The journey thus far has been exciting to say the least. The future looks even more fun and rewarding as we add more depth in each of the 5 core areas described above. Here are a few links for you to learn more.


