Why Distributed SQL Beats Polyglot Persistence for Building Microservices?
May 2, 2019
Today’s microservices rely on data with different models and read/write access patterns. Polyglot persistence, first introduced in 2008, states that each such data model should be powered by an independent database that is purpose-built for that model. This post highlights the loss of agility that microservices development and operations suffer when adopting polyglot persistence. We review how distributed SQL serves as an alternative approach that doesn’t compromise this agility.
E-Commerce Example
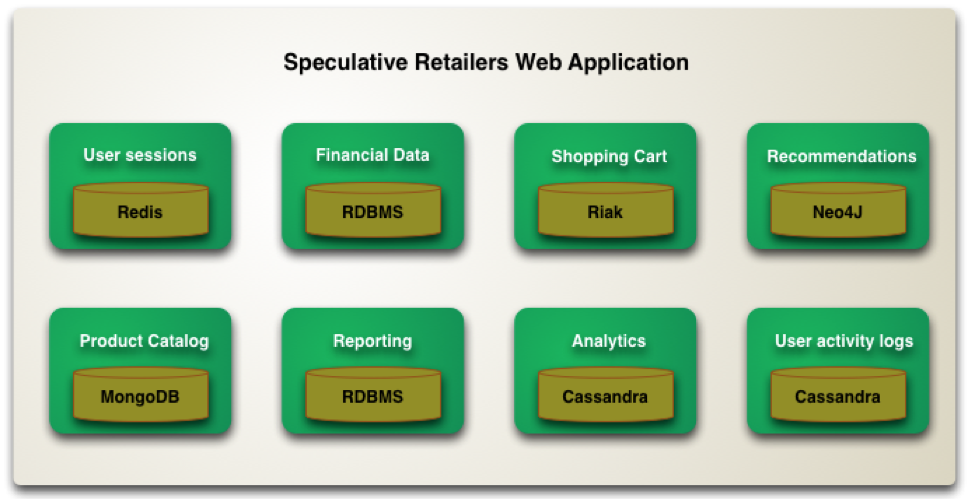
Polyglot Persistence in Action at an E-Commerce App (Source: Martin Fowler)
Breaking down monolithic applications into smaller, decoupled microservices for increased dev and ops agility is on top of the mind for most application architects. Let’s take the example of an E-Commerce application (think Amazon.com, eBay.com, and more) that undergoes such a decomposition resulting in eight different microservices. Since microservices are expected to be fully contained including the database they need, we can easily see how the application now needs six different databases as opposed to the only one RDBMS it started out with.
- The original RDBMS with relational data model for financial data (such as checkouts, invoices, refunds, and more) & reporting.
- MongoDB with flexible document data model for product catalog.
- Cassandra for high volume use cases such as real-time analytics (using Apache Spark) and user activity logs.
- Riak key-value store for managing shopping cart.
- Redis for managing user sessions and an in-memory cache for low latency reads.
- Neo4J graph database for storing recommendations.
The above is essentially polyglot persistence in action in the context of a real-world application.
Why Polyglot Persistence?
The biggest reasons behind the advent of polyglot persistence is the lack of horizontal write scalability and lack of resilience against failures in SQL-based monolithic RDBMS. During 2005-2010, as data volumes grew beyond what can be managed in a single instance of monolithic SQL database like Oracle, MS SQL Server, MySQL, and PostgreSQL, the need for a distributed database architecture became obvious. Architects had essentially two choices in front of them.
Sharded SQL is Too Complex
In the sharded SQL architecture, multiple independent RDBMS instances are brought together into a cluster using manual sharding that is managed at the application layer. The full power of relational data modeling across all instances in the cluster is not available since SQL operations such as JOINs, indexes, constraints, and transactions cannot cross shard boundaries. An in-memory cache like Redis or Memcached usually fronts the database cluster so that the more frequent read operations can be served from a low-latency storage without consuming resources from the persistent database. This allows the database serving capacity to be reserved more for write operations. Also, breaking up of hot shards manually as and when needed becomes an unavoidable reality. Engineers at large technology companies including Facebook, Uber, and Pinterest followed this architecture for their business critical data.
One SQL + Multiple NoSQL Seems Logical
Given the complex application logic involved in a sharded SQL infrastructure, traditional enterprises did not adopt such an architecture en masse. Instead, they took the path of least resistance by augmenting their existing SQL-based RDBMS with multiple NoSQL databases. Horizontal write scalability was front and center in NoSQL given the use of automatic sharding and rebalancing. However, this new NoSQL world brought forth two critical compromises.
Loss of the full power of SQL – NoSQL distributes data across multiple nodes. To ensure high performance, popular SQL operations that managed multiple rows such as JOINs, secondary indexes, and foreign key constraints were immediately disallowed. Sharded SQLs were already conditioning engineers to the loss of full SQL. NoSQLs accelerated this trend by adopting even more restrictive data modeling. The flexible model-once-query-forever relational data model we all were used to before was no longer available. Naturally, new languages had to be created to express these data models. E.g. key-value stores such as Riak and Redis restricted the language to single-key to single-value operations only. More complex values were added later as the maturity of these stores increased. MongoDB focused on a flexible JSON document as the value part. Cassandra introduced a SQL-like query language called Cassandra Query Language with all of SQL’s multi-key operations completely removed. Note that other than highly specialized data models such as graph, most of these NoSQL models were essentially subsets of SQL.
Loss of consistency and ACID transactions – Big data was the buzzword of the day and it was taken for granted that operational databases now need to embrace the corresponding design philosophies. A foundational tenet of big data architectures was that system availability has to be prioritized higher than system consistency. NoSQLs interpreted this as the mandate to adopt the AP side of CAP theorem. Single-key linearizability and the more general multi-row ACID transactions were dropped even though they were considered sacrosanct in the SQL/RDBMS world.
Engineers accepted the above compromises as the cost of developing highly scalable software. Every time new data needed to be managed by the application, they undertook careful modeling and adopted a best-of-breed NoSQL database that fit with that model. Thus, polyglot persistence was born.
The Silent Killer of Release Agility
Polyglot persistence leads to increased complexity across the board. Using multiple databases during development, testing, release, and production can be overwhelming for many organizations.
- App developers must not only learn efficient data modeling with various database APIs, but also understand the underlying storage engine and replication architectures for each of the databases. That is the only way to ensure that the database performs with high throughput and low latency for the application workload.
- Build engineers have to ensure that the full application stack including multiple databases can be built into deployment artifacts fast and reliably. The end result is a complex CI/CD pipeline that only a select few can understand and troubleshoot.
- Test automation engineers now have to account for the nuances of each database and how the microservices deal with them.
- Operations teams are now forced to understand scaling, fault tolerance, backup/restore, software upgrades, and hardware portability for multiple databases. And of course, the onerous part of “operationalizing” these databases across multiple different cloud platforms.
The end result is a painful development and deployment cycle that acts as a silent killer of release agility. Note that higher release agility was indeed the final outcome apps had desired when embracing the complexity of microservices architecture. Apps are now less agile than before, thanks to polyglot persistence.
AWS To The Rescue, But Buyer Beware
AWS CTO Werner Vogels describes how AWS views the polyglot persistence problem in his post titled, “A One Size Fits All Database Doesn’t Fit Anyone.”
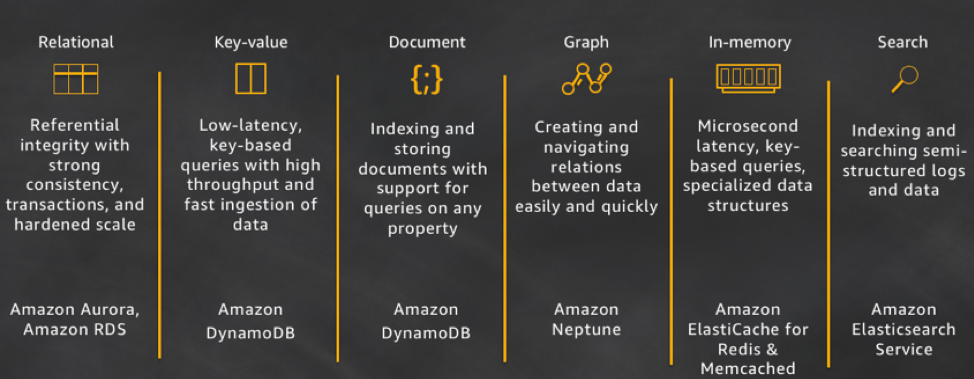
AWS Polyglot Database Offerings (Source: All Things Distributed)
As the world’s leading IaaS platform, AWS fully embraces Polyglot-Persistence-as-a-Service (no surprise!). App developers get the database model of their choice and the Operations teams don’t have to manage the multitude of databases picked by the developers. However, this point of view is self-serving to say the least. AWS charges top $ for its managed database services and gets the most effective form of lock-in (hello operational data!). If Google Cloud, Microsoft Azure, or a private cloud were to provide a lower cost solution at a higher performance, then good luck moving out of the AWS database services. At smaller scale, these issues may be immaterial but mid-to-large enterprises running their entire business on the cloud would be short-sighted to ignore the economic benefits of the multi-cloud era we live in.
Open Source, Cloud Native, Distributed SQL as the New Enterprise Choice
Over the last 10+ years, enterprises had little choice but to adopt the AWS Polyglot-Persistence-as-a-Service approach either directly with AWS or by running multiple databases themselves. AWS is now widely considered the 4th largest database vendor by revenue after the big 3 of Oracle, Microsoft (SQL Server), and IBM. Today Google Cloud and Microsoft Azure have become credible alternatives to AWS for running mission-critical services. Google Cloud and Azure also provide a set of proprietary database services on their own, but smart enterprises understand well that they cannot fall into the lock-in trap again.
So how does one build truly cloud-independent data services while also avoiding the complexity of operating multiple databases? The answer lies in making SQL scalable and resilient, thus solving the root causes that created polyglot persistence. Two additional qualities are desired to ensure we do not repeat the errors of the past. The first quality is that of open source leading to wider community of users and contributors and the second quality is that of cloud native infrastructure that enables cloud neutral deployments.
Distributed SQL is an emerging operational database category that solves the foundational problems in monolithic SQL databases by adding horizontal write scalability, high fault tolerance, and geo-distribution without compromising on low latency and high throughput. Open source, cloud native, distributed SQL databases such as YugabyteDB offer the following benefits:
- High developer productivity – model fully relational workloads as well as simpler key-value and flexible schema (with JSON column type) with ease.
- High performance – strongly-consistent reads served without expensive quorums to ensure low-latency user experience. Follower reads that make the database act as a low-latency cache by serving timeline-consistent data.
- Simplified operations – enables operations engineers to run as large a cluster as needed while ensuring zero data loss.
- No vendor lock-in – community-driven open development and open API compatibility to ensure no database vendor lock-in.
- Multi-cloud portability – allows on-demand, completely online migration to new cloud(s) using orchestration tools such as Kubernetes.
E-Commerce Example Reimagined
Now that we have understood the power of distributed SQL, let’s put it to test in the context of the E-Commerce application we reviewed earlier. As we can see below, by solving the core problems associated with monolithic SQL databases, we have allowed the E-Commerce application to function with only two types of databases instead of six types we saw before.
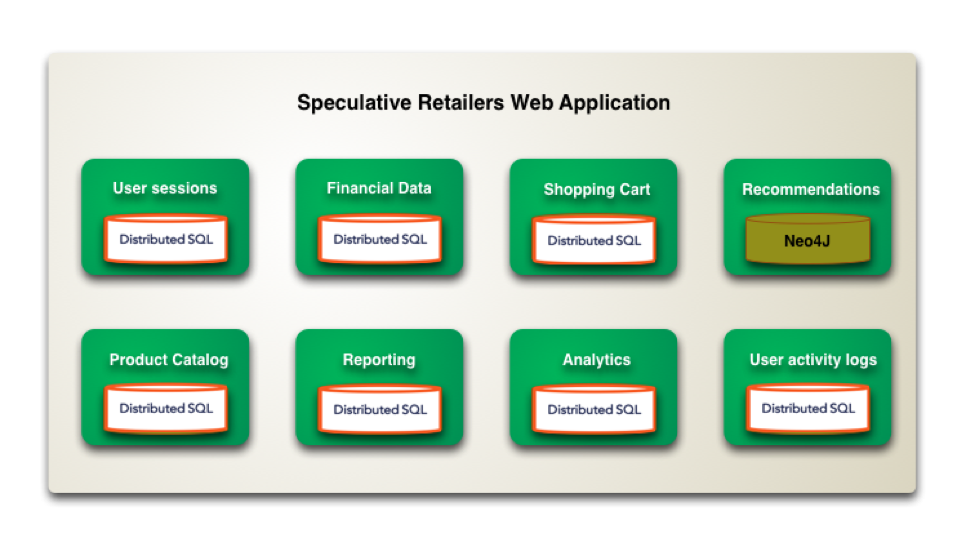 Distributed SQL database for the five use cases highlighted below.
Distributed SQL database for the five use cases highlighted below.
- As a fully relational OLTP database for financial data (such as checkouts, invoices, refunds, and more) & reporting.
- As a flexible schema database with JSON column type for product catalog.
- As a massively scalable HTAP database for real-time analytics and user activity logs.
- As a key-value store for managing shopping cart.
- As a persistent store for user sessions.
And, Neo4J graph database for storing recommendations.
Note that in the case of YugabyteDB, a separate in-memory Redis cache that offloads read operations away from the main persistent store is no longer needed because the database itself can power read operations with ease (without the use of quorum voting involving follower replicas). Additionally, YugabyteDB’s YCQL API can be used to power Janusgraph workloads without needing an additional graph database.
Summary
Lack of horizontal scalability and lack of fault tolerance in legacy SQL databases were the primary reasons behind acceptance of polyglot persistence as a necessary evil in application development. Both of these limitations have been solved by modern distributed SQL databases such as Google Spanner and its open source derivatives such as YugabyteDB. Continuing as-is with polyglot persistence even when such distributed SQL databases are available means signing up for never-ending development and operational complexity. Add to this the need to remain ever-ready for infrastructure changes such as compute instances, disks, availability zones, regions/datacenters, and even cloud platforms. Simplified development and operations combined with open source and cloud native principles make distributed SQL databases perfect for today’s multi-cloud era. It’s time to bid goodbye to the proprietary polyglot persistence of a single and expensive cloud platform!
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner, and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing, or to schedule a technical overview.


