Using the PostgreSQL Recursive CTE – Part One
March 1, 2021
Traversing an employee hierarchy
YugabyteDB is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. YugabyteDB uses its own special distributed document store called DocDB. But it provides SQL and stored procedure functionality by re-using the “upper half” of the standard PostgreSQL source code. This is explained in the two part blog post “Distributed PostgreSQL on a Google Spanner Architecture”: (1) Storage Layer; and (2) Query Layer.
This is the first post of a two-part blog series. Part Two is Computing Bacon Numbers for actors listed in the IMDb. Each of these case studies, the employee hierarchy and the Bacon Numbers problem, is a famous example of the use of the PostgreSQL recursive common table expression (CTE). Because YugabyteDB re-uses the PostgreSQL SQL processing code “as is” , everything that I say in the present two-part blog post series applies in the same way to PostgreSQL as it does to YugabyteDB. In particular, all the code works identically in the two environments. I hope, therefore, that developers who mainly use only PostgreSQL, as well as YugabyteDB aficionados, will find these posts interesting.
The Bacon Numbers problem is based on the most general kind of graph—an undirected cyclic graph. A hierarchy, at the other end of the spectrum, is the most restricted kind of graph. It is directed, acyclic, and has just a single node that has no incoming edges. For this reason, it is also known as a rooted tree. Because of these restrictions, a hierarchy can be represented in a simpler way than a general graph (and almost always is represented this way). And the simpler representation allows a specialized, simpler traversal method.
The present Part One uses the simple representation and the simple traversal method. Part Two uses the general representation and the general traversal method.
I recently finished writing a thorough treatment of the WITH clause in YugabyteDB’s YSQL documentation in this dedicated section:
The WITH clause and common table expressions
It includes this dedicated subsection:
I’ll link extensively to explanations and especially to code examples in my account in the YSQL documentation so that, in these two posts, I can focus on the high-level narrative and make them as short as possible. I included full accounts of the two case studies that these posts describe in the YSQL documentation here:
Using a recursive CTE to traverse an employee hierarchy
and here:
Using a recursive CTE to compute Bacon Numbers for actors listed in the IMDb
All the code snippets and pictures in this post are copied from the YSQL documentation. The main page of the overall WITH clause and common table expressions section explains that all the code is available in a downloadable code zip with a few master scripts to run all of the code mechanically.
Employee hierarchy traversal in the real world
These days, all organizations with a reasonably large staff provide an online employee directory application for internal use. Maybe it’s bought from a third party. Or maybe, like the one that Oracle Corporation uses (see this tweet), it’s home-grown. Typically, and for obvious reasons, the data are stored and maintained in a SQL database. These applications’ GUIs support a range of end-user queries that rest explicitly on the notion of the organization structure. Here are some common examples:
- Show me all employees with a last name sounding like “Jonson” in the subtree under the manager I have on my screen right now.
- I want to follow up with a staff member whom I’d never met until today’s meeting and who is working on a project where I feel I can make a contribution. Show me the chain of direct line managers above them all the way up to the very top.
The implementation of such queries depends on the techniques that the following sections present.
Notice, by the way, that the section Finding the paths in a rooted tree within the section “Using a recursive CTE to traverse graphs of all kinds” shows how, of course, the path finding approach for the most general kind of graph, an undirected cyclic graph, can be used on the most restricted kind of graph that looks like this:
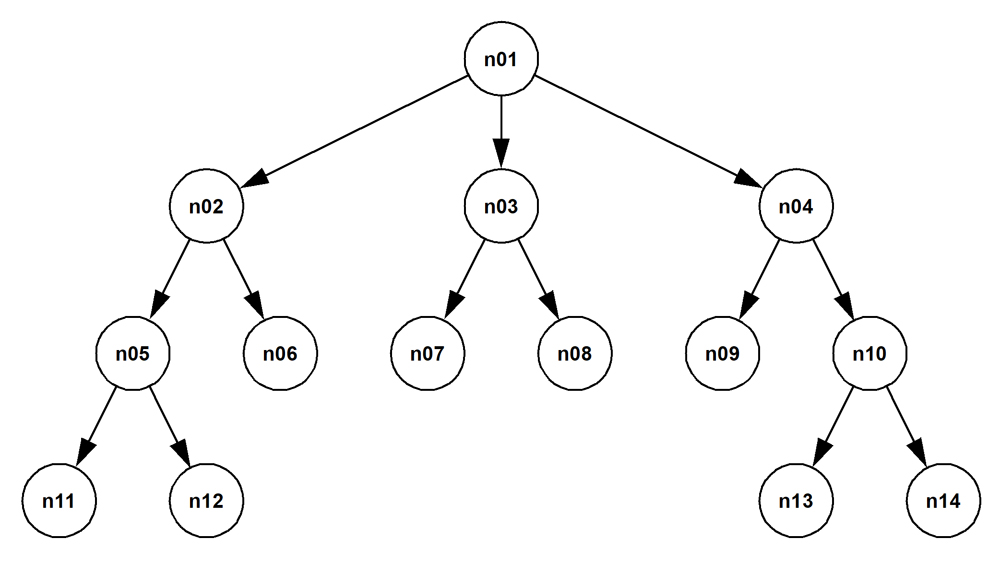
The directed edge goes from the manager to their direct report. A strict organization hierarchy is a rooted tree. But you don’t need to use the general approach where edges are represented explicitly, when you have a rooted tree. Rather, the edges can simply be implied by a self-referential foreign key. In the general formulation, the “nodes” table has a “parent_node_id” column that references the “node_id” column. This scheme allows the simple path finding scheme that the present Part One describes.
However, sometimes an organization has formalized the notions of a direct manager and a “dotted line” manager. This means that the organization structure isn’t described by a rooted tree. Rather, it’s described by a directed acyclic graph like this:
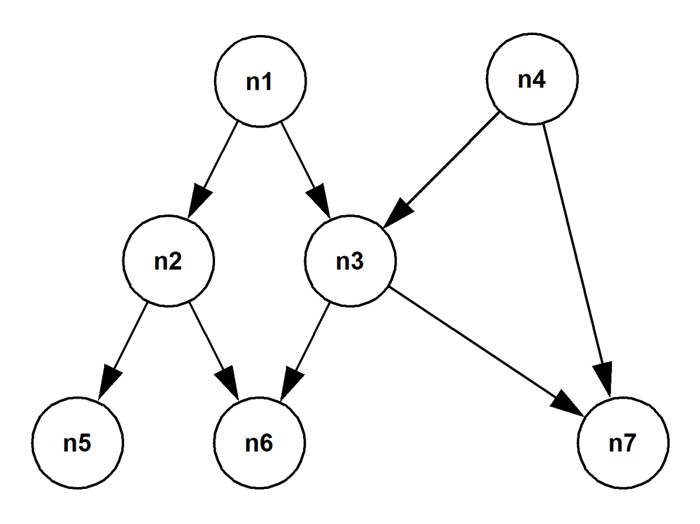
The node “n2” might be the direct manager of “n6”; and “n3” might be their dotted line manager. The graph is represented by recording both the nodes and the edges in dedicated tables. So the edges can have properties like “is dotted line”. Maybe, for some reason, the organization staffs its “big overall boss” role with more than one person (like is the case with “n1” and “n4”). In other words, the directed acyclic graph can represent each of these departures from a strict organization hierarchy. The approach described in the section Finding the paths in a directed acyclic graph in the YSQL documentation shows how to traverse such a graph.
About the WITH clause
The WITH clause lets you name one or several so-called common table expressions. This latter term is a term of art, and doesn’t reflect the spellings of SQL keywords. It is normally abbreviated to CTE, and I’ll use this acronym throughout this blog post series. It helps to look at the syntax diagrams in the YSQL documentation in the section WITH clause—SQL syntax and semantics, copied here:
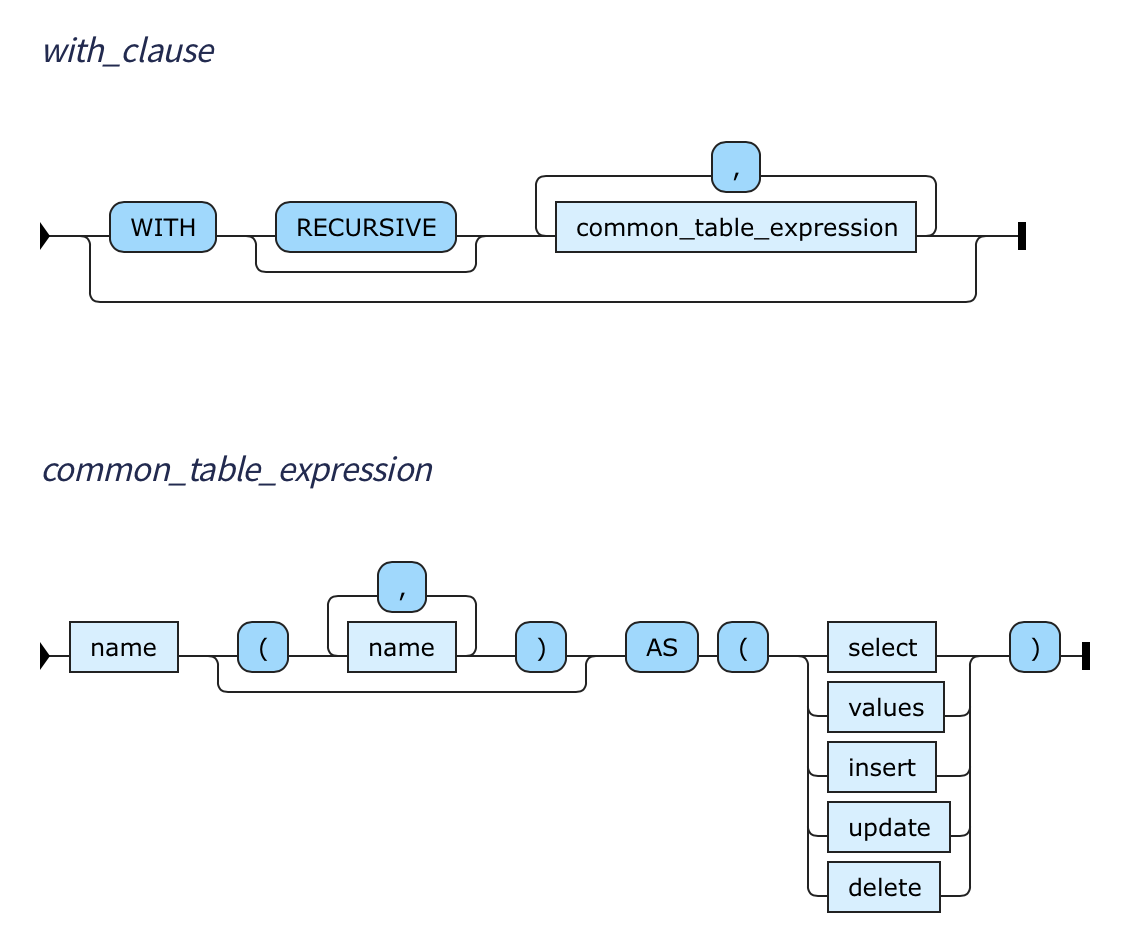
Briefly, a CTE names a SQL [sub]statement which may be any of these kinds: SELECT, VALUES, INSERT, UPDATE, or DELETE. And the WITH clause is legal at the start of any of these kinds of statement: SELECT, INSERT, UPDATE, or DELETE. (VALUES is missing from the second list.) The diagrams say that there are two kinds of CTE: the ordinary kind and the recursive kind. They also convey a rule: if you want to define a recursive CTE, then it must be the first in the WITH clause—and that a WITH clause that does this can define no other recursive CTEs. This restriction is rarely painful in practice. But if it proves to be so, you can work around it straightforwardly by defining the entire SQL statement that starts with a recursive CTE as a next-level CTE in a surrounding WITH clause. This approach (WITH clauses within WITH clauses) is illustrated in the YSQL documentation section Example where a CTE defined in the WITH clause itself has a WITH clause.
Note: You often hear the term “recursive WITH clause” in place of “recursive CTE”. (I spelled it out here so that readers might find this blog post using Internet search.) To say it bluntly, this usage is quite simply an erroneous abuse of the terms of art. However, the mistake is widespread (as an Internet search will show you) and seems never to lead to misunderstanding.
The recursive CTE brings surprisingly powerful functionality. And, in the way that SQL is famous for, it brings this declaratively and remarkably tersely.
Create and populate the “emps” table
You can copy and paste the code from the documentation, here, into ysqlsh (or into psql if you’re using PostgreSQL) to create a table of employees that records each employee’s manager using a self-referential foreign key. Use this query to see what you got:
select name, mgr_name from emps order by 2 nulls first, 1;
This is the result:
name | mgr_name --------+---------- mary | joan | bill alfie | fred dick | fred doris | fred alice | john bill | john edgar | john fred | mary george | mary john | mary susan | mary
I added the blank lines by hand to make the results easier to read.
This use of a self-referential foreign key is the standard way to represent a hierarchy in a SQL database. Because this is a stylized example, it’s enough that the table has just a “name” column, serving as the primary key, and a “mgr_name” with a foreign key constraint to the “name” column.
List the employees top-down with their immediate managers in breadth first order
Copy and paste the code from the documentation, here, to produce the list. Here is the result:
depth | mgr_name | name -------+----------+-------- 1 | - | mary 2 | mary | fred 2 | mary | george 2 | mary | john 2 | mary | susan 3 | fred | alfie 3 | fred | dick 3 | fred | doris 3 | john | alice 3 | john | bill 3 | john | edgar 4 | bill | joan
Once again, I added the blank lines by hand to make the results easier to read.
You’ll see the general form of the recursive CTE when you look at the code. Briefly, it has a so-called non-recursive term followed by a so-called recursive term. You should combine the results from each using UNION ALL when you’re sure that they share no identical rows; otherwise, eliminate these with a bare UNION. UNION ALL is preferred when you can use it because it’s quicker than a bare UNION. The non-recursive term is executed just once. And then the recursive term is executed repeatedly until it produces no results. Before each next repetition, the self-reference (here to the “hierarchy_of_emps” recursive CTE) is populated with the results of the previous evaluation of the recursive term. And on completion of the present execution of the recursive term, its results are “union all” added (into a growing hidden in-memory structure) to the cumulative results to date. The population of this hidden in-memory structure, when the repetition stops, is the final result of the recursive CTE. It is then available for later CTEs in the WITH clause, or the overall statement’s final substatement, to reference.
In ordinary prose, the non-recursive term starts from the ultimate manager (i.e. the employee whose “mgr_name” column, uniquely, is NULL) and finds all their direct reports. Then, the first repetition of the recursive term starts with the ultimate manager’s direct reports and, for each, finds their direct reports. And so it goes on: each repetition of the recursive term goes one level deeper down the hierarchy—often producing more results each time than the previous time reflecting the fact that a manager usually has more than one report. At each step, the path upwards from a just-added employee all the way to the very top of the tree is available (if only you care to write the logic to maintain this path in the SQL that defines the recursive term). Eventually, each repetition of the recursive term starts to produce more and more individual contributors and correspondingly fewer and fewer managers—so that each repetition now produces fewer results than the previous one. It all stops when the repetition produces only individual contributors because, of course, the next repetition looks for the direct reports of these individual contributors—and there aren’t any.
If you find this a bit hard to grasp, you can study the Semantics subsection in the Recursive CTE section of the YSQL documentation. It uses pseudocode to explain what I explained in loose prose here. And then it uses PL/pgSQL to implement the pseudocode.
Spoiler alert: you have to use what I called the “pseudocode implementation”, and not an out-of-the-box recursive CTE, to solve the Bacon Numbers problem on realistic volumes of IMDb data. Else, the ever-growing size of the hidden in-memory structure where the final result set is built brings your computer (at least if it’s a laptop) to a graceless crash. (The growth rate, with each successive repetition of the recursive term, approaches exponential.) Part Two explains all this.
List the path top-down from the ultimate manager to each employee in breadth first order
The term of art “path” means the chain of employees starting with the ultimate manager and continuing down through successive under-managers until it reaches an individual contributor. It is conveniently represented, here, as a text[] array of scalar text values. The formulation of the recursive CTE that produces the output shown here has exactly the same shape and logic as the formulation that I described in the previous section. The only difference is that the SELECT list expresses “depth” as the array’s cardinality, “mgr_name” as the penultimate array element, and the present employee as the ultimate element—i.e. “path[cardinality(path)]”.
Copy and paste the code from the documentation, here, to produce the list. Here is the result:
depth | path
-------+-----------------------
1 | {mary}
2 | {mary,fred}
2 | {mary,george}
2 | {mary,john}
2 | {mary,susan}
3 | {mary,fred,alfie}
3 | {mary,fred,dick}
3 | {mary,fred,doris}
3 | {mary,john,alice}
3 | {mary,john,bill}
3 | {mary,john,edgar}
4 | {mary,john,bill,joan}Once again, I added the blank lines by hand to make the results easier to read.
You might prefer to omit the “depth” column and simply infer it by counting the number of employees in the chain by eye.
Compare the results shown here with those shown in the previous section. They both have the same information content listed in the same order. The results here show, in the last-but-one and last array elements, the identical values to the “mgr_name” and “name” columns in the results shown in the previous section. But it’s easier to read the results shown here because you don’t need mentally to construct the path by looking, recursively, for the row that has the “mgr_name” of the row of interest as its “name” until you reach the ultimate manager.
Note: It’s hard to invent examples that show the phenomenal value of YSQL’s “array” functionality (inherited, of course, from PostgreSQL) in stand-alone examples. This is because of the large amount of problem-domain-specific stage-setting that would have to be done. For this reason, when I wrote the YSQL documentation section Array data types and functionality, I mainly used smallish, contrived examples. I strongly recommend that you study that section. With a solid understanding of “array” functionality, you’ll be able to reach for that tool without hesitation when you’re solving a new specific problem. Without that prior understanding, you’re unlikely to spot what you should now study so that you’ll then find the inspiration to solve your present challenge! (That’s why I did woodworking and metalworking classes when I was at school.)
List the path top-down from the ultimate manager to each employee in depth-first order
Copy and paste the code from the documentation, here, to produce the list. (The code uses a view that was created to produce the breadth first order that the previous section described, so make sure that you ran that code before doing this.) Here is the result:
depth | path
-------+-----------------------
1 | {mary}
2 | {mary,fred}
3 | {mary,fred,alfie}
3 | {mary,fred,dick}
3 | {mary,fred,doris}
2 | {mary,george}
2 | {mary,john}
3 | {mary,john,alice}
3 | {mary,john,bill}
4 | {mary,john,bill,joan}
3 | {mary,john,edgar}
2 | {mary,susan}The key to producing the depth-first ordering is, once again, “array” functionality. All the more reason to study this! The listing is a bit quick-and-dirty (just like the one shown in the previous section) because it simply prints out the so-called text-literal form of each successive array value (that represents each successive path) using the implicit ::text typecast on the array values that ysqlsh, and psql, apply under the covers to get a printable value. (You might prefer to self-document your SQL by spelling out the operator explicitly.)
Users often like to see indentation to let them visualize hierarchical depth. This is easy to achieve, and the section that I linked to goes on to show you how, here. This is the result:
mary
fred
alfie
dick
doris
george
john
alice
bill
joan
edgar
susan
You’ve probably seen how the Unix tree command presents the hierarchy that it computes using the long vertical bar, the long horizontal bar, the sideways “T”, and the “L” symbols: │, ─, ├, and └. It’s easy to output an approximation to this, that omits the long vertical bars, with a single SQL statement. The trick is to use the lead() window function to calculate the “next_depth” for each row as well as the “depth”. If the “next_depth” value is equal to the “depth” value: then output the sideways “T”; else output the “L” (at the appropriate indentation level). This is done using a single SQL statement. Even now, after a few decades of using SQL every working day, I’m astonished by the power of declarative SQL. The single statement is here. It’s just thirty five lines—and most of that is because I used new lines liberally to help readability. Beat that with your favorite middle tier procedural programming language! This is the result:
mary └── fred ├── alfie ├── dick └── doris ├── george └── john ├── alice └── bill └── joan └── edgar └── susan
I decided to leave the final prettying-up work, adding vertical bars to recreate the Unix tree format completely faithfully, as an exercise for the reader. Here’s where ordinary “if-then-else” programming is helpful. The starting point would be a PL/pgSQL stored procedure encapsulation. (I did, at least, show you the skeleton procedure, here. You might like to take it to completion. If you do, then please show me your solution at bryn@yugabyte.com. You might even get a Yugabyte T-shirt.)
List the path bottom-up from a chosen employee to the ultimate manager
The essential property of a hierarchy is that each successive upwards step defines exactly one parent (in this example, exactly one manager) by traversing the foreign key reference in the “many” to “one” direction. It’s this property that distinguishes a hierarchy from a more general graph. This means that there is no distinction between breadth-first and depth-first when traversing a hierarchy upwards. Here is the query. It’s presented using the prepare-and-execute paradigm so that you can supply the starting employee of interest as a parameter. Here’s the result when you ask for the upwards chain starting from Joan:
depth | name | mgr_name -------+------+---------- 0 | joan | bill 1 | bill | john 2 | john | mary 3 | mary | -
You might, as I do, prefer this prettier, and more compact, output with the same information content:
joan > bill > john > mary
The code that starts here shows you how to do this.
Conclusion
This post has given you an introduction to the awe-inspiring power of PostgreSQL’s recursive CTE—inherited with complete syntactic and functional fidelity by YugabyteDB’s YSQL. But, so far, I’ve only skimmed the surface. I hope, therefore, that I’ve whetted your appetite for Part Two, Computing Bacon Numbers for actors listed in the IMDb.


