Technical Deep Dive into YugabyteDB 1.1
September 21, 2018
We announced the general availability of YugabyteDB 1.1 earlier this week. You can download the latest version for your OS or use our default container image as documented in our Quick Start page.
YugabyteDB is an open source database for high performance applications that require ACID transactions and multi-region data distribution. By combining transactional NoSQL and distributed SQL in a single database, YugabyteDB eliminates the need for multiple databases. This helps reduce costs and operational complexity, while at the same time enabling developers to deliver projects faster.
This post gives you a deep dive into the various features of YugabyteDB 1.1 both in the Open Source and Enterprise Editions.
YugabyteDB Open Source
Transactions, Secondary Indexes & Document Data Modeling
After extensive testing both internally and with customers, we are happy to announce the general availability of distributed ACID transactions, secondary indexes and JSON document data types!
Distributed ACID transactions enable use cases which require updating multiple keys in an atomic and consistent manner. An example of such a use-case is performing a “bank transfer” from one account to another, in which the balances in the two accounts have to be updated atomically.
Secondary indexes use distributed ACID transactions internally, and can be used to speed up queries. You can create one or more secondary indexes on various columns of a table. In addition to speeding up queries, secondary indexes also support a unique constraint where the application does not want duplicate values to be inserted into a column.
This release introduces the JSONB document data type to parse, store and query JSON documents natively. This data type enables modeling use-cases requiring a flexible schema. The scale-out and high performance characteristics along with this flexible data type makes YugabyteDB an excellent target database to store data coming from a message bus such as Kafka.
Jepsen Testing
We have also performed extensive Jepsen testing against YugabyteDB, where we verified the correctness of various operations on the database – including distributed ACID transactions, in the presence of various failures such as node restarts, network partitions and clock skew between nodes. Formal certification by Jepsen.io after independent testing is on our near-term roadmap.
Yugabyte SQL (BETA)
YSQL, YugabyteDB’s PostgreSQL-compatible distributed SQL API, is now in BETA. It is a SQL implementation on top of DocDB, YugabyteDB’s Google Spanner-inspired distributed document store. It speaks the PostgreSQL dialect and is wire compatible with PostgreSQL drivers, but runs across multiple nodes. It can be horizontally scaled for write-intensive and/or geo-distributed workloads. Implementation and architecture details can be reviewed here.
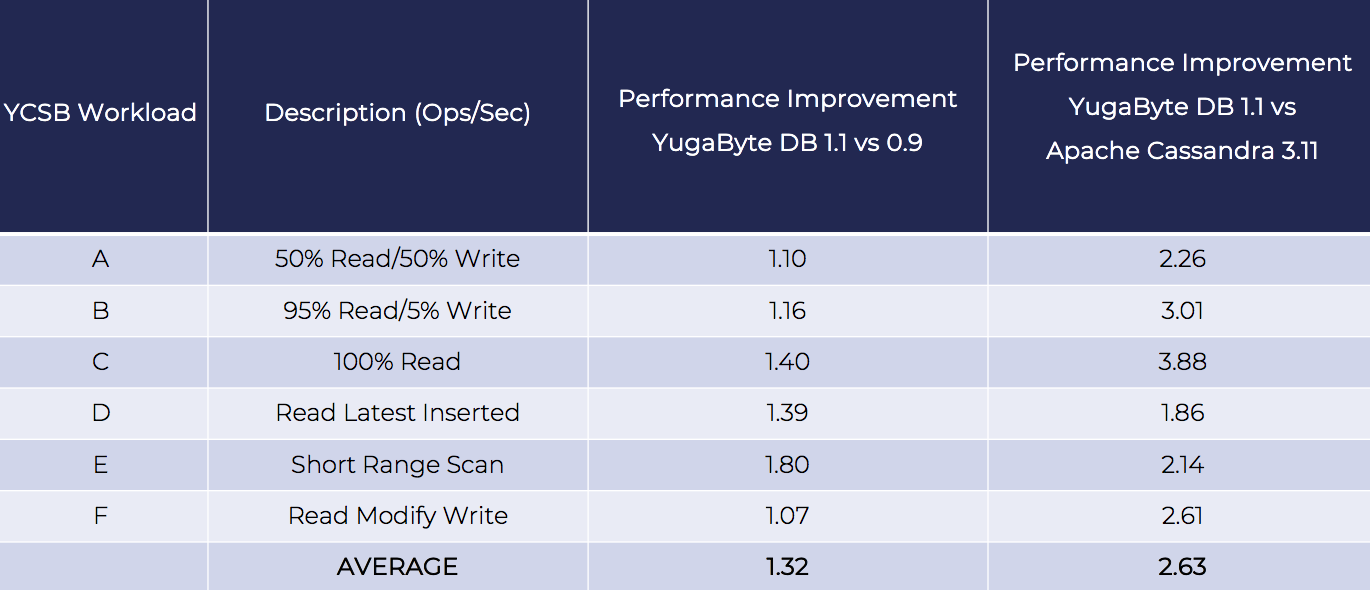
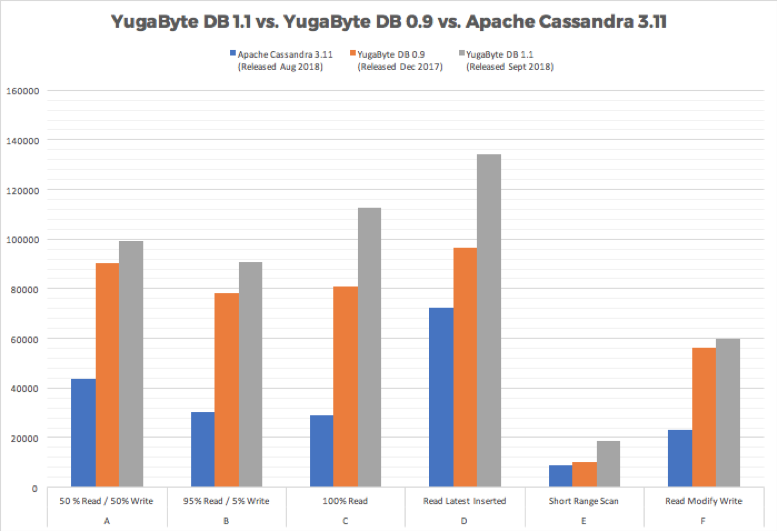
High Performance: 2.5x Faster than Apache Cassandra
We view performance as an ongoing journey, meaning it should keep getting better over time. This is very true even with the current release.
YugabyteDB 1.1 boasts a 30% improvement in performance on average compared to YugabyteDB 0.9 (released Dec 2017) as measured by YCSB operations per second across the various workload types (with 10 Million keys as the data volume). Note that short range scans improved by 80% due to a number of optimizations. Short range scans are critical for a number of workloads our customers use us for, for example:
- Event data which typically has a time component and needs short time range scans.
- Real time analytics where frameworks such as Apache Spark and Presto are used to analyze data.
- Time series data often built with frameworks such as KairosDB.
We also compared the performance of YugabyteDB 1.1 with the latest version of Apache Cassandra 3.11 using the YCSB benchmark. The results are even more exciting — YugabyteDB 1.1 on an average is more than 2.5x faster than Apache Cassandra 3.11. For 100% read workload, YugabyteDB performs almost 4x faster. Note that the YugabyteDB tests were performed using the Cassandra-compatible YCQL API.
Redis-Compatible API Enhancements
YugabyteDB’s Redis-compatible YEDIS API allows it to be deployed as a fault-tolerant, highly-scalable Redis cluster. This release has a few enhancements for the YEDIS API that make it perfect for geo-distributed/multi-region deployments:
- Follower reads from local region which allows the app to read from a follower. It is possible to configure the app to read from a follower in the nearest region, while being unaware of the deployment topology of the database.
- Bounded staleness where the reads from a follower lags behind by at most a time interval (the time interval is configurable).
Security: User Authentication
Security is paramount in any operational database. There is now user authentication support in the Cassandra compatible YCQL API, which if enabled requires all clients connecting to the database to provide a username and password. Authentication support is also added to Redis compatible YEDIS API. Similar to Redis authentication, the user is prompted for a password. YugabyteDB however adds an enhancement which supports multiple passwords to support rolling passwords in an online manner. The end user can now perform a graceful change of password without experiencing any app downtime using the sequence:
- Add a new password in addition to the existing one for a username
- Change the password used by the app tier by pushing a new config/code
- Drop the old password in the db for the username
Scalability: High Density Data Nodes
With increasing transactional data volumes in modern applications, scaling out under high density scenarios is becoming very critical. We performed just such a benchmark – running an 18TB random key-value workload against a 4-node YugabyteDB cluster. Once all the data was loaded, we added a fifth node to the cluster to scale it out with high data density. YugabyteDB database was able to gracefully scale out and rebalance 3.8TB of data seamlessly in just 7 hours. You can read about the details of this experiment in our high data density benchmark blog.
Monitoring: Prometheus Support
You can now monitor YugabyteDB cluster with Prometheus, the de-facto standard for time-series monitoring of cloud native infrastructure. Every YugabyteDB service exposes metrics in the Prometheus format as a queryable endpoint and hence can be monitored by your existing Prometheus Server. The Enterprise Edition comes pre-built this integration along with a number of health checks and diagnostics reporting, making it a turn-key solution.
Cloud Native Orchestration with Kubernetes
YugabyteDB 1.1 can run natively inside any distribution of Kubernetes including the standard open source distribution. You can easily spin up a cluster using the YugabyteDB Helm chart, increase or decrease the number of pods and performing a rolling upgrade of the YugabyteDB version.
Integrations: Spring, Presto and Language Drivers
There have been a number of enhancements in the area of Integrations with other open source frameworks. With Cassandra and Redis compatible APIs, YugabyteDB plugs into Spring Data Cassandra and Spring Data Redis, so you can easily build Spring applications. We are working on native Spring Data drivers for YugabyteDB to make app building even simpler.
YugabyteDB also works with Presto in addition to already working with Apache Spark for real time analytics. We have made enhancements to KairosDB so that it can exploit the full power of YugabyteDB. JanusGraph, a graph database, works with YugabyteDB as well.
Finally, we have expanded our verified client driver support matrix. We now support the C#, Golang and C++ client drivers. They join the existing Java, Python and NodeJS drivers.
YugabyteDB Enterprise Edition
YugabyteDB Enterprise Edition includes all the features of YugabyteDB Open Source as well as multiple features necessary for operationally simple, enterprise-grade deployments.
Enterprise-Grade Security with In-Flight Encryption
Support for TLS encryption over the wire is now available. This features enables secure, SSL-encrypted channel for:
- Node to node communication between the database cluster nodes
- Client to database cluster nodes communication
Distributed Backups & Restore
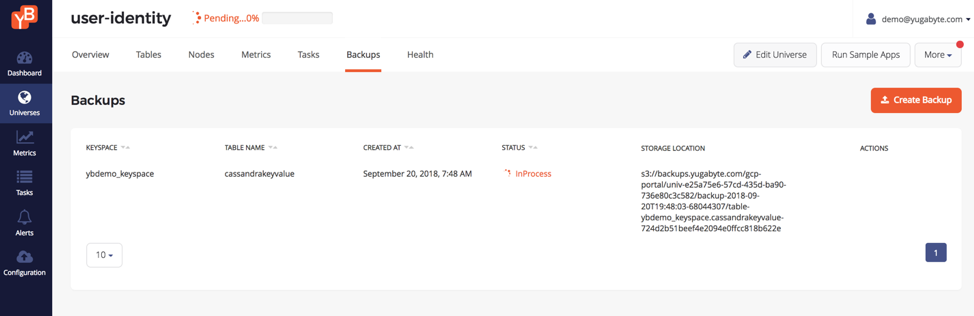
Any YugabyteDB table can be now backed up with AWS S3 and can be restored back into either the same table or an entirely new table. Support for additional cloud providers as backup destinations including on-premises file systems is on the roadmap.
Read Replicas (BETA)
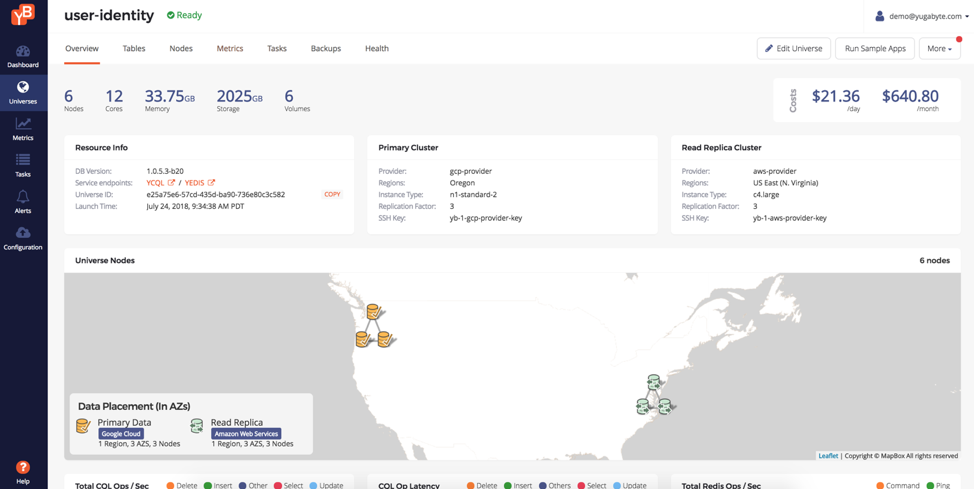
We can now add a read replica in minutes to the primary cluster in YugabyteDB Enterprise. A read replicas does not add write latency overhead since the data is asynchronously replicated from the primary cluster in a controlled manner. As shown in the figure below, this feature allows globally distributed services to simultaneously support low latency, high throughput writes and timeline-consistent, low latency reads. Note that the read replica can be run in a different cloud altogether than the original primary data cluster. For example, the figure below has read replica on Amazon Web Services while the primary data cluster is on Google Cloud.
Fine-Grained Node Status & Actions
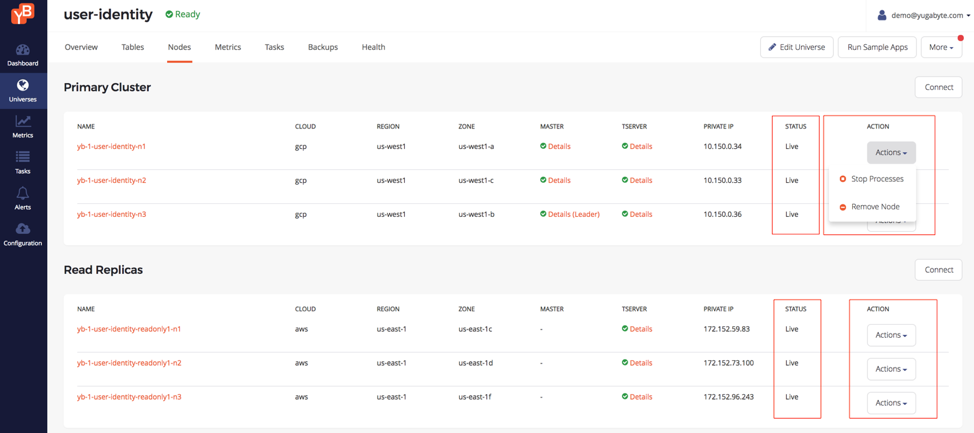
Comprehensive lifecycle management for a database cluster involves ability to perform maintenance operations on a single node when needed. E.g. replacing the instance powering a node in response to the instance going into a cloud-provider directed maintenance window. YugabyteDB Enterprise now supports 5 different node statuses and multiple different node actions to ensure you always have a high performing, highly available cluster.
Cloud Native Orchestration with GKE & PKS
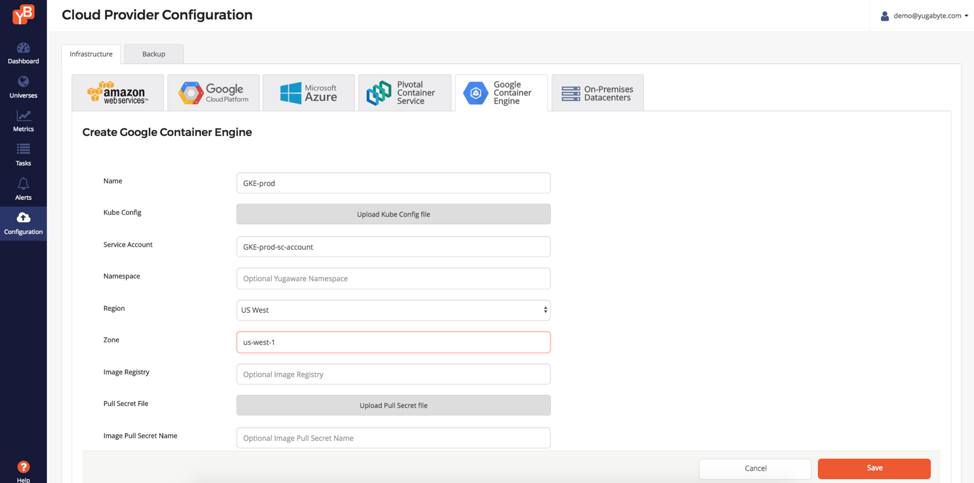
YugabyteDB 1.1 Enterprise Edition has native support for various managed Kubernetes providers such as Google Kubernetes Engine (GKE) and Pivotal Container Service (PKS).
What’s Next?
- Read detailed how-it-works and how-to-use instructions for key YugabyteDB 1.1 new features.
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on the cloud or container of your choice.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


