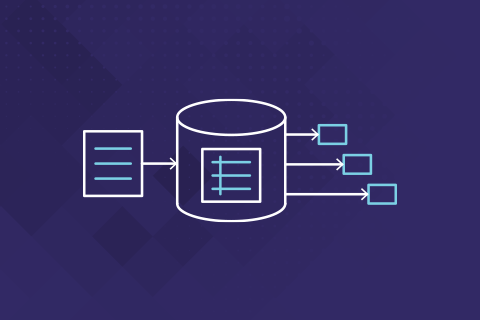
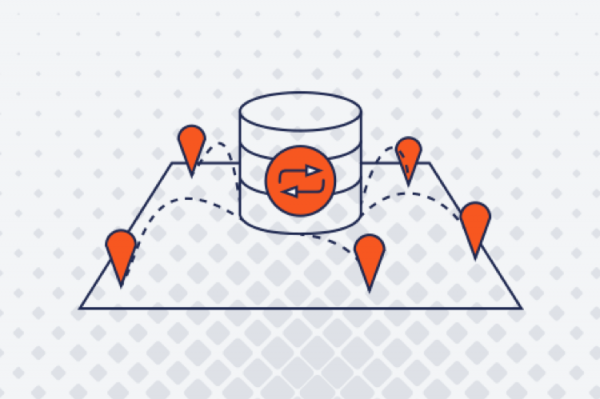
Generate SQL Script in PostgreSQL
DBAs often need to generate SQL statements using SQL queries and then execute them. PostgreSQL has many features that can help. Let’s walk through an example using YugabyteDB, which is Postgres-compatible and provides the same SQL language and catalog views.