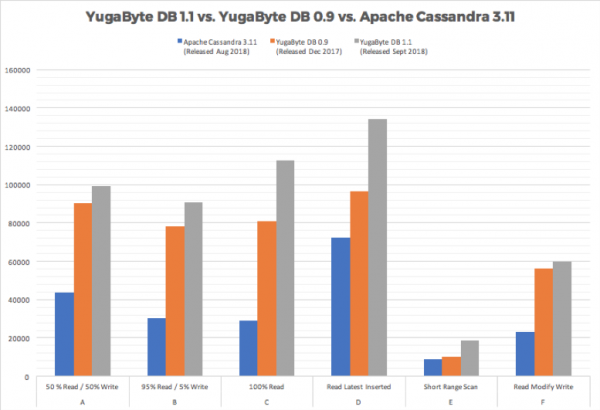
YSQL Architecture: Implementing Distributed SQL in YugabyteDB
In this post, we will look at the architecture of YSQL, the PostgreSQL-compatible distributed SQL API in YugabyteDB. We will also touch on the current state of the project and the next steps in progress. Here is a quick overview:
- YugabyteDB has a common distributed storage engine that powers both SQL and NoSQL
- For supporting NoSQL apps, YugabyteDB is designed for low latency, sub-millisecond reads and massive write scalability. It can handle millions of requests and many TBs of data per node with linear scalability and high resilience.
…