Spanning the Globe without Google Spanner
April 16, 2020
Open Source Geo-Distributed Relational Database on Multi-Cluster Kubernetes
Google Spanner, conceived in 2007 for internal use in Google AdWords, has been rightly considered a marvel of modern software engineering. This is because it is the world’s first horizontally-scalable relational database that can be stretched not only across multiple nodes in a single data center but also across multiple geo-distributed data centers, without compromising ACID transactional guarantees. In 2012, Google introduced Spanner to the outside world by publishing the details of its core architecture in an academic research paper. A follow-on paper in 2017 provided a deep dive into the SQL query processing layer. These two papers combined highlight how Spanner solves some of the thorniest issues in building a geo-replicated globally-consistent RDBMS. At the top of the list is the use of TrueTime, Google’s proprietary high-precision global atomic clock, for executing distributed transactions and atomic schema changes across multiple shards where each shard could be located in a distant data center. Such transactions adhere to `external consistency`, the strictest isolation level possible. Next comes the use of per-shard distributed consensus (based on Paxos) for ensuring single-row linearizability.
Google made Spanner available for public use in 2017 as a managed database service on Google Cloud. However, users interested in adopting Spanner have to weigh the benefits of a fully-managed service with the proprietary and expensive nature of the service. This brings open source geo-distributed SQL databases like YugabyteDB into consideration. YugabyteDB’s sharding, replication, and distributed ACID transactions design principles are inspired by the Google Spanner architecture. However, it does not require any specialized infrastructure components like Spanner’s TrueTime atomic clock. Distributed transactions instead rely on an intelligent tracking of max clock skew across different nodes of a cluster. This allows YugabyteDB to run natively on any commodity infrastructure on any public or private cloud. Additionally, YugabyteDB relies on the easier-to-understand Raft protocol (instead of Paxos) for its per-shard distributed consensus implementation.
Open Source Geo-Distributed SQL on Kubernetes
Kubernetes, an open source technology that also originated at Google, has rapidly grown over the last few years to become the de facto infrastructure standard for application deployment, using containers as the foundation. Containerized deployments with Kubernetes allow developers and operations engineers to pick the best-of-breed cloud platform for their application as opposed to the one-cloud-fits-all value proposition of proprietary managed services like Google Cloud Spanner. So the natural question is — what if we could have a Spanner-like globally-consistent multi-region deployment of YugabyteDB on Google Kubernetes Engine (GKE)? We can then simply replace GKE with other Kubernetes distributions and managed services (including Amazon EKS and Azure Kubernetes Service) to realize the benefits of geo-distributed SQL on the cloud of our choice. We can even deploy a single database cluster across multiple cloud platforms if needed. As highlighted in 9 Techniques to Build Cloud-Native, Geo-Distributed SQL Apps with Low Latency, the deployment combinations are seemingly endless, thus allowing users to pick and choose the combinations that best fit their business needs. For the purpose of this post, we will focus on the Single Cloud, Multi-Region deployment as shown in the figure below.
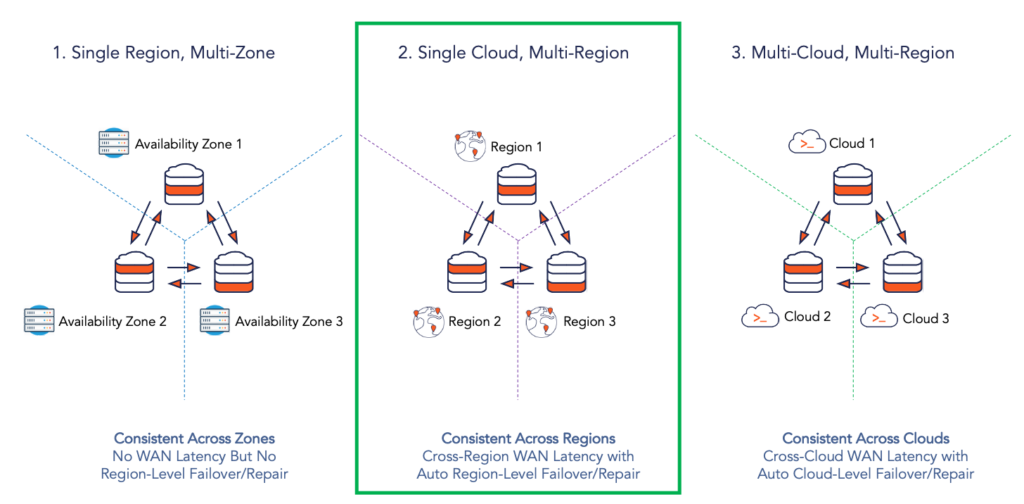
Note that Kubernetes is not a mandatory requirement here since open source geo-distributed SQL databases can be deployed equally well even on regular cloud VM instances. However, the significant DevOps tooling necessary for VMs for each cloud platform can become a barrier to the promise of picking the best-of-breed cloud platform for a given application. With managed Kubernetes, this DevOps challenge is mitigated to a great extent. While administering Kubernetes clusters itself is cloud platform specific, managing application deployments on Kubernetes is cloud agnostic given Kubernetes’ standard deployment constructs and tooling.
Architecting Multi-Region Kubernetes Deployments
Deploying multi-region applications on Kubernetes is a non-trivial endeavor given some of the core design principles behind Kubernetes. The first question is — why can’t we deploy a single Kubernetes cluster across multiple regions? While the Kubernetes worker nodes can be theoretically placed across multiple regions, the issue lies in how the single Kubernetes master node is deployed. Since network partitions across regions will be common in a single multi-region cluster, the Kubernetes master node will often get cut off from Kubernetes worker nodes in other regions. These worker nodes can no longer receive commands from the master, and hence are no longer available for scheduling/orchestration. Additionally, the master will treat these worker nodes as lost and reschedule the missing pods on the available worker nodes. This results in lost capacity in all regions disconnected from the master and insufficient capacity in the region connected to the master.
The next obvious question is — what if we run one replica of the master node in each region (alongside a replica of the etcd metadata store)? We have to ensure there is always a single `leader` master node so that there is a single source of truth for the cluster. Note that the number of regions has to be odd in this case for etcd’s Raft distributed consensus to work properly. This is the recommended approach for making Kubernetes masters highly available in a single cluster deployed across multiple zones of a single region. However, this approach is not recommended for a multi-region deployment. Even though the metadata changes can be persisted fast enough using a quorum of etcd replicas, the cross-region latency problem can get magnified when Kubernetes master initiates cluster-wide administration operations based on this persisted data.
Given these cross-region networking challenges, the consensus in the Kubernetes community today is that a single cluster should be limited to deployment in a single region only. Multi-region deployments have to be solved using multiple clusters, where each cluster is scoped to a single region only. SIG-Multicluster is a dedicated Special Interest Group in the Kubernetes community focused on solving common challenges related to the management of many Kubernetes clusters, across multiple cloud providers and applications deployed across many clusters. Kubefed is a sub-project in SIG-Multicluster currently in alpha that has the most promise in this regard. It is a successor to the original Federation v1 specification introduced in Kubernetes 1.3.
Spanner-like Geo-Distributed SQL on Multi-Region, Multi-Cluster GKE
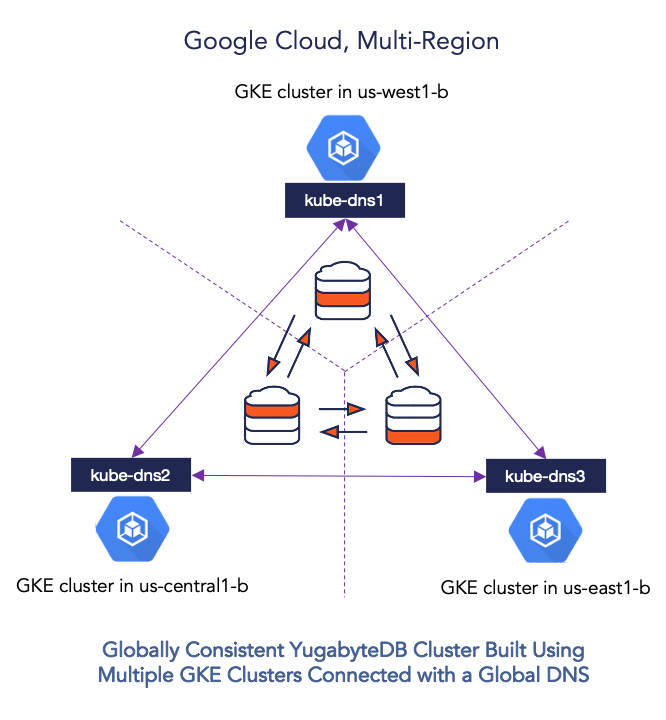
While there isn’t a single standard to connect multiple heterogeneous Kubernetes clusters, connecting multiple homogeneous Kubernetes clusters on a single cloud platform is certainly possible. For example, we can connect 3 Google Kubernetes Engine clusters by updating the kube-dns service on each of them to access the kube-dns service on other clusters for namespace-scoped requests. We can even make such a configuration secure from unauthorized access by using the global access option of Google Cloud internal load balancers instead of publicly-accessible external load balancers.
The instructions in this section describe a multi-cluster GKE deployment, leveraging the global DNS approach noted above, for running a multi-region YugabyteDB distributed SQL database cluster. This configuration is shown in the figure below. Detailed instructions including prerequisites for the scenario described here are available in YugabyteDB Documentation. The end result is a Spanner-like globally-consistent multi-region distributed SQL cluster on Google Cloud.
1. Create 3 GKE clusters in 3 regions
Following commands create 3 Kubernetes clusters in 3 different regions (us-west1, us-central1, us-east1), with 1 node in each cluster. Note that global access on load balancers is currently a beta feature and is available only on GKE clusters created using the rapid release channel.
Create clusters
$ gcloud beta container clusters create yugabytedb1 \
--machine-type=n1-standard-8 \
--num-nodes 1 \
--zone us-west1-b \
--release-channel rapid
$ gcloud beta container clusters create yugabytedb2 \
--machine-type=n1-standard-8 \
--num-nodes 1 \
--zone us-central1-b \
--release-channel rapid
$ gcloud beta container clusters create yugabytedb3 \
--machine-type=n1-standard-8 \
--num-nodes 1 \
--zone us-east1-b \
--release-channel rapid
Create a storage class per zone
We need to ensure that the storage classes used by the pods in a given zone are always pinned to that zone only. Detailed instructions on how to do so are available here.
2. Setup global DNS
Create load balancer configuration for kube-dns
The yaml file shown below adds an internal LoadBalancer, which by definition is not exposed outside the Google Cloud region it was created in, to Kubernetes’s built-in kube‑dns deployment. By default, the kube-dns deployment is accessed only by a ClusterIP and not a load balancer. Additionally, we allow this load balancer to be globally accessible so that each such load balancer is now visible to the 2 other load balancers in the other 2 regions. Note that using external load balancers for this purpose is possible but is not recommended from a security best practices standpoint. This is because the DNS information for all the clusters would now be available for access on the public Internet.
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/load-balancer-type: "Internal"
networking.gke.io/internal-load-balancer-allow-global-access: "true"
labels:
k8s-app: kube-dns
name: kube-dns-lb
namespace: kube-system
spec:
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
selector:
k8s-app: kube-dns
sessionAffinity: None
type: LoadBalancer
Apply the configuration to every cluster
Download the yb-multiregion-k8s-setup.py script from the YugabyteDB GitHub repo that will help you automate the setting up of the load balancers.
wget https://raw.githubusercontent.com/yugabyte/yugabyte-db/master/cloud/kubernetes/yb-multiregion-k8s-setup.py
The script starts out by creating a new namespace in each of the 3 clusters. Thereafter, it creates 3 internal load balancers for kube-dns in the 3 clusters. After the load balancers are created, it configures them using Kubernetes ConfigMap in such a way that they forward DNS requests for zone-scoped namespaces to the relevant Kubernetes cluster’s DNS server. Finally it deletes the kube-dns pods so that Kubernetes can bring them back up automatically with the new configuration.
Open the script and edit the `contexts` and `regions` sections to reflect your own configuration. And then run it as shown below.
python yb-multiregion-k8s-setup.py
We now have 3 GKE clusters that essentially have a global DNS service as long as services use zone-scoped namespaces to access each other. Now we are ready to install a single YugabyteDB cluster that spans these 3 GKE clusters.
3. Create a YugabyteDB cluster spanning 3 GKE clusters
Add YugabyteDB Helm charts repository
helm repo add yugabytedb https://charts.yugabyte.com helm repo update helm search repo yugabytedb/yugabyte
Create override files
We have to create an override file for each GKE cluster so that the YugabyteDB Helm chart can correctly bring up one third of the nodes in each cluster. The example file for the us‑west1 GKE cluster is shown below. You can find the files for the other two clusters here.
isMultiAz: True
AZ: us-west1-b
masterAddresses: "yb-master-0.yb-masters.yb-demo-us-west1-b.svc.cluster.local:7100, yb-master-0.yb-masters.yb-demo-us-central1-b.svc.cluster.local:7100, yb-master-0.yb-masters.yb-demo-us-east1-b.svc.cluster.local:7100"
storage:
master:
storageClass: "standard-us-west1-b"
tserver:
storageClass: "standard-us-west1-b"
replicas:
master: 1
tserver: 1
totalMasters: 3
gflags:
master:
placement_cloud: "gke"
placement_region: "us-west1"
placement_zone: "us-west1-b"
leader_failure_max_missed_heartbeat_periods: 10
tserver:
placement_cloud: "gke"
placement_region: "us-west1"
placement_zone: "us-west1-b"
leader_failure_max_missed_heartbeat_periods: 10
Note that we also set the leader_failure_max_missed_heartbeat_periods option to 10. This option specifies the maximum heartbeat periods that the leader can fail to heartbeat before the leader is considered to be failed. Since the data is geo-replicated across data centers, RPC latencies are expected to be higher. We use this flag to increase the failure detection interval in such a higher RPC latency deployment. Note that the total failure timeout is now 5 seconds since it is computed by multiplying raft_heartbeat_interval_ms (default of 500ms) with leader_failure_max_missed_heartbeat_periods (current value of 10).
Install YugabyteDB
Now create the overall YugabyteDB cluster in such a way that one third of the nodes are hosted in each Kubernetes cluster.
$ helm install yb-demo-us-west1-b yugabytedb/yugabyte \ --namespace yb-demo-us-west1-b \ -f overrides-us-west1-b.yaml \ --kube-context gke_yugabyte_us-west1-b_yugabytedb1 --wait $ helm install yb-demo-us-central1-b yugabytedb/yugabyte \ --namespace yb-demo-us-central1-b \ -f overrides-us-central1-b.yaml \ --kube-context gke_yugabyte_us-central1-b_yugabytedb2 --wait $ helm install yb-demo-us-east1-b yugabytedb/yugabyte \ --namespace yb-demo-us-east1-b \ -f overrides-us-east1-b.yaml \ --kube-context gke_yugabyte_us-east1-b_yugabytedb3 --wait
4. Configure region-aware replica placement
Default replica placement policy treats every yb-tserver as equal irrespective of its placement_cloud, placement_region, and placement_zone settings. Run the following command to make the replica placement region/cluster aware so that one replica is placed on each region/cluster.
kubectl exec -it -n yb-demo-us-west1-b --context gke_yugabyte_us-west1-b_yugabytedb1 yb-master-0 bash \ -- -c "/home/yugabyte/master/bin/yb-admin --master_addresses yb-master-0.yb-masters.yb-demo-us-west1-b.svc.cluster.local:7100,yb-master-0.yb-masters.yb-demo-us-central1-b.svc.cluster.local:7100,yb-master-0.yb-masters.yb-demo-us-east1-b.svc.cluster.local:7100 modify_placement_info gke.us-west1.us-west1-b,gke.us-central1.us-central1-b,gke.us-east1.us-east1-b 3"
We can even make one region the default leader for all the shards in the YugabyteDB cluster. This can act as an important performance optimization where cross-leader communication happens internally to a single region, thus keeping transaction latency low. Multi-region deployments of Google Cloud Spanner also start out with a default leader region for exactly the same reason.
kubectl exec -it -n yb-demo-us-west1-b --context gke_yugabyte_us-west1-b_yugabytedb1 yb-master-0 bash \ -- -c "/home/yugabyte/master/bin/yb-admin --master_addresses yb-master-0.yb-masters.yb-demo-us-west1-b.svc.cluster.local:7100,yb-master-0.yb-masters.yb-demo-us-central1-b.svc.cluster.local:7100,yb-master-0.yb-masters.yb-demo-us-east1-b.svc.cluster.local:7100 set_preferred_zones gke.us-west1.us-west1-b"
5. Connect clients
Now we can connect clients such as ysqlsh, the Yugabyte SQL shell, to the database. Let us connect to the nodes connected in the us-west1 region.
kubectl exec -n yb-demo-us-west1-b --context gke_yugabyte_us-west1-b_yugabytedb1 -it yb-tserver-0 /home/yugabyte/bin/ysqlsh -- -h yb-tserver-0.yb-tservers.yb-demo-us-west1-b
You can run YSQL queries using the sample e-commerce schema that ships with YugabyteDB.
6. Test DB cluster resilience in face of region failures
It’s time to test the resilience of the DB cluster when subjected to the complete failure of one region. We will simulate such a failure by setting the replica count of the YugabyteDB StatefulSets to 0 for the us-central1 region.
kubectl scale statefulset yb-tserver --replicas=0 -n yb-demo-us-central1-b --context gke_yugabyte_us-central1-b_yugabytedb2 kubectl scale statefulset yb-master --replicas=0 -n yb-demo-us-central1-b --context gke_yugabyte_us-central1-b_yugabytedb2
If we re-run the queries from Step 5 after connecting to the nodes in the us-west1 region, we will see that there is absolutely no impact to the availability of the cluster and the data stored therein. However, there is higher latency for some of the transactions since the farthest us-east1 region now has to be involved in the write path. In other words, the database cluster is fully protected against region failures but may temporarily experience higher latency. This is a much better place to be than a complete outage of the business-critical database service. The post Understanding How YugabyteDB Runs on Kubernetes details how YugabyteDB self-heals the replicas when subjected to the failure of a fault domain (the cloud region in this case) by auto-electing a new leader for each of the impacted shards in the remaining fault domains. The cluster goes back to its original configuration as soon as the nodes in the lost region become available again.
Summary
Google Spanner has been the gold standard for powering globally-distributed and/or horizontally-scalable relational apps. A cost-effective, multi-cloud alternative to Spanner helps users derive the same benefits as that of Spanner but on the cloud and infrastructure of their choice. YugabyteDB is such an alternative. It is a Spanner-inspired, geo-distributed, PostgreSQL-compatible SQL database that is not only fully open source but is also easy to operate via Kubernetes. Deploying YugabyteDB on a managed Kubernetes service like GKE strikes that perfect balance of a managed infrastructure service (that keeps operator burden low) coupled with an open cloud native SQL database (that enables picking the best cloud platform for a given application).
While YugabyteDB can be deployed in single zone and multi-zone Kubernetes clusters with extreme ease, multi-region Kubernetes deployments require additional considerations. This has less to do with YugabyteDB and more to do with the fact that multi-region Kubernetes is essentially a multi-cluster Kubernetes problem because of Kubernetes’ underlying architecture. One solution to this problem is highlighted in this tutorial where we connect multiple GKE clusters using a global DNS that can route namespace-scoped pod/service requests in one GKE cluster correctly to other GKE clusters. Running a globally-consistent YugabyteDB cluster becomes simple thereafter.


