Rise of Globally Distributed SQL Databases – Redefining Transactional Stores for Cloud Native Era
January 16, 2019
At last month’s KubeCon + CloudNativeCon in Seattle, the single biggest change from previous container-related conferences was the excitement among the end user companies around their adoption of Kubernetes and the associated cloud native infrastructure ecosystem. The CNCF End User Community page today lists 50+ enterprises and 21+ case studies including those from industry bellwethers such as Capital One, Netflix, Nordstrom and Pinterest. There is a common adoption pattern among all these case studies — cloud native infrastructure is no longer limited to the stateless microservices and is rapidly evolving to cater to the needs of business-critical “stateful” databases at these companies. Our previous post “Docker, Kubernetes and the Rise of Cloud Native Databases” details some of the trends that are driving these changes.
When it comes to databases, the famed relational database (aka RDBMS) has ruled the roost for almost four decades now. And SQL has been the lingua franca the relational database world. As infrastructure is changing from “cloud hosted” to “cloud native”, it is worth analyzing how the SQL/relational database market is changing to meet the demands imposed by the new cloud native infrastructure layer. The rise of globally distributed SQL is easily the most revolutionary change to SQL since ACID transactions were added in the 1980s. This post dives deeper into the evolution of SQL databases from the monolithic era to the globally-distributed, cloud native era. Specifically, we use horizontal write scalability, self-healing fault tolerance, multi-shard transactions and zero-data-loss/low-latency multi-region deployments as the four major criteria to evaluate three classes of SQL databases.
Monolithic SQL
SQL has been forever synonymous with “Relational” and “Transactional”, which means support for multi-key access patterns such as JOINs, foreign keys and ACID transactions. Until recently, SQL databases have been monolithic in architecture and hence run on a single write node backed by specialized, high cost hardware that in turn leads to several day-2 issues. Adding more automation in terms of replication, fast failover, backup/recovery or running inside Kubernetes does not change the fact that a single write node is constrained by processing power and hence cannot serve high-throughput transactional apps with low latency.
Expensive, Vertical Write Scaling
Monolithic SQL databases require painful vertical hardware scaling as the application’s write volume increases. This means find a bigger machine with more compute, more memory and more disk space and then manually migrating the database instance to this new machine. 
Vertical Scaling in Action (Source)
Simple sharding, where data is partitioned across independent databases, can be thought of as a band-aid enhancement that is usually added to achieve horizontal write scaling. However, the application code now becomes responsible for identifying which instance owns which shards. At smaller scale, this approach works ok for verticals such as SaaS where the data is naturally amenable to sharding across customers/users. However, at larger scale, the resulting complexity can bring business to a standstill since re-sharding and moving hot shards to instances with more processing power can completely consume engineering capacity.
Poor Fault Tolerance
Adding high availability to a monolithic SQL database entails adding a new independent database instance and then copying the data over via either async or sync replication.
- Asynchronous replication (previously referred to as master-slave replication) is the most common form of replication and involves replicating committed data from leader to follower periodically. There will be some data loss when the leader fails and the follower hasn’t yet received some of the committed writes. Availability is also not 100% since there is usually a downtime involved in failing over to the follower.
- Synchronous replication guarantees zero data loss using atomic write operations that are implemented via protocols such as 2-phase commit. However, such a system becomes unavailable whenever one of the two instances is down or there is a network problem leading to loss of connectivity between the two instances.
Data Loss in Multi-Region Deployments
Monolithic SQL databases mandate multi-master replication in the context of a multi-region deployment. In a multi-master system, each master node contains the entire dataset and hence handles writes for all the data without any need for distributed transactions. Changes on one master are replicated to other masters asynchronously for read scaling and disaster recovery. Such an active/active deployment has the perceived benefit of write scaling but that benefit is voided in reality because of conflict-ridden concurrent writes on same rows at different masters. Such conflicts are resolved without explicit knowledge of the app using non-deterministic heuristics such as Last-Write-Wins (LWW) and Conflict-Free Replicated Data Types (CRDT). As we will see in the next sections, the net result is customer data loss and poor engineering productivity when compared to globally distributed SQL databases.
Open Source Examples
PostgreSQL
First released as an academic project out of UC Berkeley, PostgreSQL has had an exciting journey especially since a SQL interpreter was added in 1995. Today PostgreSQL has a strong reputation for reliability, feature robustness and performance. And given that it is released under a very permissive open source license, many developers do not think twice before building their simple apps on top of PostgreSQL. However, as highlighted in the previous section, PostgreSQL still suffers from the fundamental limitations of monolithic SQL.
MySQL
Released under the restrictive GPL license, MySQL is another open source RDBMS that shot to fame in the late 1990s by virtue of its inclusion in the LAMP (Linux, Apache Web Server, MySQL DB and PHP) stack. Sun Microsystems acquired MySQL AB, the Swedish company behind the DB, in 2008 for $1 Billion. Given Sun’s acquisition by Oracle in 2010, MySQL today is part of the Oracle database portfolio. MariaDB is a commercially-supported fork of MySQL that has also gained traction since the Oracle ownership began. Web-scale companies such as Facebook and Uber that started mid-to-late 2000s run a large number of sharded MySQL master-slave clusters because their transactional data volume is too high to be served by a single MySQL node. These companies have the engineering expertise to develop and run such complex infrastructure. Traditional enterprises seeing high data growth unfortunately do not have the luxury of a web-scale giant to solve the problem with tons of engineering time.
Proprietary Examples
Amazon Aurora
While there are plenty of hosted RDBMS solutions (including Amazon’s own RDS), Amazon Aurora is a proprietary monolithic SQL service that’s worth covering in depth given its unique architecture. Generally available since July 2015, Aurora is built on a custom storage engine that automatically replicates 6 copies of data across 3 availability zones for high availability. From an API standpoint, Aurora is wire compatible with both PostgreSQL and MySQL. As described in “Amazon Aurora under the hood: quorums and correlated failure”, Aurora’s quorum write approach based on the 6 replicas allows for significantly better availability and durability than traditional master-slave replication. However, there is no escaping the fact that at any moment of time, only a single instance can process write requests for all the data that needs to be ingested and served by the database. If writes become slow, the only solution is to vertically scale the underlying hardware. This approach is untenable for enterprises building internet-scale, transactional microservices.
Distributed SQL 1.0 – NewSQL
The challenges associated with monolithic SQL have been well understood for more than a decade. In fact, the NoSQL database revolution started in mid-to-late 2000s to address these challenges. NoSQL solved the problem of horizontal write scaling but abandoned SQL and its multi-key access patterns including transactions and JOINs. Around the same time NoSQL was starting, a new class of databases also started with the aim of adding horizontal write scaling to SQL databases. Matt Aslett from the 451 Research Group coined the term “NewSQL” in 2011 to categorize these first generation of distributed SQL databases. However, these NewSQL databases also suffered from a few fundamental issues and as a result never really rose to challenge the dominance of traditional SQL and NoSQL databases.
Cost-Effective, Horizontal Write Scaling
Given that manual sharding with application-level shard management was a big problem in the monolithic SQL world, many NewSQL databases added a transparent sharding layer to existing databases. 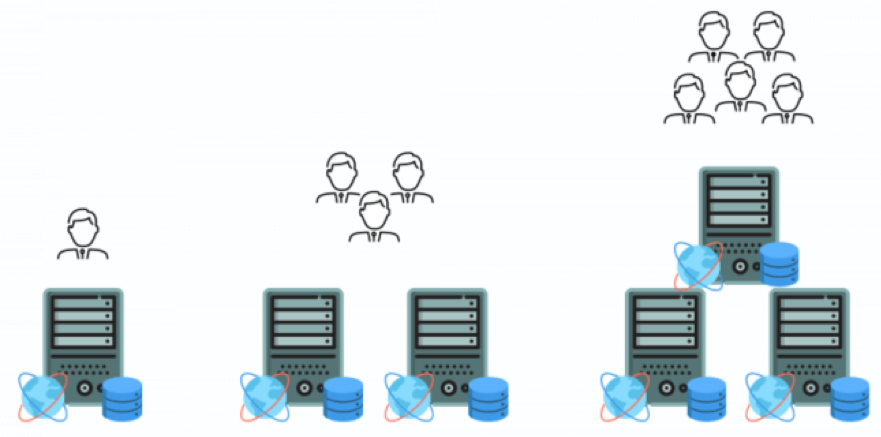
Horizontal Scaling in Action (Source)
The idea is to distribute the incoming data across all nodes in the cluster as evenly as possible and add/remove nodes in response to performance needs.
Poor Fault Tolerance
Even though NewSQL databases automated sharding, they did nothing as far as high availability is concerned. Replication continued to remain the same as previously found in monolithic SQL databases. As these databases started running in shared infrastructure of the public cloud, failures became more frequent. This meant previously rare manual failovers and data loss events now became more frequent. Users realized that the replication architecture of the monolithic SQL era is not going to provide durability and availability in the modern cloud era.
No Multi-Shard ACID Transactions
The fundamental issue with the NewSQL approach is that each shard is essentially full instance of a monolithic SQL database that is itself unaware of any other shard. This means critical features such as cross-shard transactions can never be supported and the application’s SQL logic has to be intricately aware of the current data-to-shard mapping.
High Latency in Multi-Zone, Multi-Region Deployments
Multi-zone deployments are table stakes these days given the need to run nodes in different failure domains of a single data center or region. Even multi-region deployments are becoming commonplace in enterprise architectures as they serve two vital needs:
- Automatic tolerance against region-level failures through immediate failover.
- Low-latency reads by moving data closer to geo-distributed users.
Unfortunately, NewSQL databases are either best suited to run in a single zone (because of need for highly reliable network) or are susceptible to high latency in multi-region deployments (because of the need to coordinate transactions against a single coordinator).
Open Source Examples
CitusData
Packaged as an extension to the monolithic PostgreSQL DB, Citus essentially adds linear write scalability to PostgreSQL deployments through transparent sharding. The installation begins with say n nodes of PostgreSQL with each node also having the Citus extension. Thereafter only 1 of these n nodes becomes the Citus coordinator node and the remaining n-1 nodes become the Citus worker nodes. Applications interact only with the coordinator node and are unaware of the existence of the worker nodes. Aside from the obvious performance and availability bottleneck of a single coordinator responsible for all application requests, the replication architecture to ensure continued availability under failures is still master-slave (based on Postgres standard streaming replication).
Vitess
Vitess is very similar to Citus at the core but is instead meant for MySQL. It adds a shard management system on top of MySQL instances where each MySQL instance acts as a shard of the overall database. It keeps track of which shard is located in what instance in etcd, a separate strongly consistent key-value store. Unlike Citus’s single coordinator node approach, Vitess uses a pool of stateless servers to route queries to the appropriate shard based on the mapping stored in etcd. Each of the instances use standard MySQL master-slave replication to account for high availability.
Proprietary Examples
Clustrix
Clustrix, started in 2006, was one of the earliest attempts at building a scale-out SQL database. Unfortunately, it had a tortuous history before getting acquired by MariaDB in 2018. The first product that shipped was a database hardware appliance in 2010 that could be deployed only in a single private datacenter. The appliance used specialized hardware and could not get adoption beyond a dozen deployments. With public cloud and commodity hardware gaining steam, Clustrix pivoted to a MySQL-compatible software-only solution in 2014. However, it continued to rely on a very reliable network for sharding, replication and failover operations. This meant adoption in the public cloud era lagged especially in the context of multi-region deployments. Databases designed to withstand cloud’s inherent unreliability and unpredictable latencies have outshined legacy databases such as Clustrix.
NuoDB
Started in 2008, NuoDB is another proprietary NewSQL database that has struggled to gain traction. Built on a complicated architecture of many moving parts (Brokers, Transaction Engines and Storage Managers), NuoDB claims to be an elastic, ANSI-SQL compliant database that does not require any form of sharding or replication altogether. This essentially means that fault tolerance guarantees have to be handled either at the storage layer (which is impossible in the shared-nothing public cloud) or at the application layer (by ensuring that the multiple copies of the same database are run on multiple hosts). Neither of these options are practical in the cloud native era we live in today.
Distributed SQL 2.0 – Globally Distributed SQL
2012 proved to be a landmark year in the history of database architectures. The most notable database design came from Google in the form of the Spanner paper published at the OSDI conference. Spanner is Google’s globally-distributed RDBMS that powers much of its business-critical properties such as AdWords, Apps, GMail and more. Google had been building Spanner starting 2007 first as a transactional key-value store and then as a SQL database. The shift to SQL as the only database language accelerated as Google engineers realized that SQL has all the right constructs for agile app development especially in the cloud native era where infrastructure is a lot more dynamic and failure-prone than the highly reliable private datacenters of the past.
Cost-Effective, Horizontal Write Scaling
Database sharding is completely automatic in the Spanner architecture. Additionally, shards become auto balanced across all available nodes as new nodes are added or existing nodes are removed. Microservices needing massive write scalability can now rely on the database directly as opposed to adding additional infrastructure such as an in-memory cache (that offloads read requests from the database thereby freeing it up for serving write requests).
Self-Healing Fault Tolerance
A key difference between Spanner and the legacy NewSQL databases we reviewed in the previous section is Spanner’s use of per-shard distributed consensus to ensure each shard (and not simply each instance) remains highly available in the presence of failures. Infrastructure failures always affect only a subset of data (only those shards whose leaders get partitioned away) and never the entire cluster. And, given the ability of the remaining shard replicas to auto-elect a new leader in seconds, the cluster exhibits self-healing characteristics when subjected to failures. The application remains transparent to these cluster config changes and continues to work normally without outages or slowdowns.
Full Spectrum of ACID Compliance
Unlike the NewSQL databases, the full spectrum of ACID transactions is supported in the Spanner architecture. Single-key operations are by default strongly consistent and transactional (the technical term is linearizable). Single-shard transactions by definition are leadered at a single shard and hence can be committed without the use of a distributed transaction manager. Multi-shard transactions involve a 2-Phase Commit using a distributed transaction manager that also tracks clock skews across the nodes. The key here is that all transaction types are transparent to the developer who simply uses regular SQL constructs to interact with the database.
Zero Data Loss & Low Latency Multi-Zone, Multi-Region Deployments
The benefit of a globally-consistent database architecture is that microservices needing absolutely correct data in multi-zone and multi-region write scenarios can finally rely on the database directly. Conflicts and data loss observed in typical multi-master deployments of the past do not occur. Features such as table-level and row-level geo-partitioning ensure that data relevant to the local region remains leadered in the same region. This ensures that the strongly consistent read path never incurs cross-region/WAN latency. Note that TiDB is an exception to this approach, see details in the section below.
Open Source Examples
The Spanner architecture has inspired multiple open source databases including Yugabyte DB as discussed in the next section.
CockroachDB
CockroachDB, a PostgreSQL-compatible distributed database built on RocksDB, is inspired by Google Spanner as far as sharding, replication and multi-shard transactions are concerned.
TiDB
TiDB, a MySQL-compatible distributed database built on TiKV, takes design inspiration from Google Spanner and Apache HBase. While its sharding and replication architecture are similar to that of Spanner, it follows a very different design for multi-shard transactions. As described in “Implementing Distributed Transactions the Google Way: Percolator vs. Spanner”, TiDB uses Google Percolator as the inspiration for its multi-shard transaction design. This choice essentially makes TiDB unfit for multi-region deployments since majority of transactions in a random-access OLTP workload will now experience high WAN latency for getting a timestamp from the global timestamp oracle running in a different region.
Proprietary Examples
Google Cloud Spanner
Google made a subset of the Spanner system publicly available in 2017 on the Google Cloud Platform as a proprietary managed service called Google Cloud Spanner. Cloud Spanner has all the good properties of the Spanner design but also comes with significant database vendor lock-in risk, especially for enterprises looking to leverage the multi-cloud world we live in today. In such a multi-cloud world, microservices and the corresponding databases are all running in Kubernetes and the deployment can be moved to a new cloud partially or completely with zero downtime as and when needed.
Yugabyte DB as a Cloud Native, Globally Distributed SQL Database
That SQL will become globally distributed is one of the founding theses behind Yugabyte DB when we started the project 3 years back. Business-critical microservices will no longer have to compromise between zero data loss and internet-scale growth. Yugabyte DB is a fully open-source, cloud-native, distributed SQL database built on top a common distributed document store called DocDB. DocDB’s sharding, replication and multi-shard transactions architecture are inspired by Google Spanner. YSQL, Yugabyte DB’s PostgreSQL-compatible distributed SQL API, leverages the core strengths of DocDB and adds its own ability to serve high-performance SQL queries.
Microservices willing to trade away fully-relational access patterns (such as JOINs and foreign keys) in favor of even higher throughput and lower latency semi-relational access patterns can leverage the Yugabyte Cloud QL API. Since application architects are not forced to complicate their data architecture by bringing in a new database for every small variance in performance or data modeling needs, the resulting architecture lends itself extremely well to high developer agility (i.e. build apps fast with the data model of choice) as well as high operational simplicity (i.e. run apps with less moving parts).
Summary

The distributed SQL market can be summarized as per the figure above. The NewSQL movement was a good attempt at solving some of the core issues in monolithic SQL such as manual sharding. However, the lack of true fault tolerance and multi-shard transactions meant that NewSQL remained a band-aid and never achieved mass adoption. Google Spanner-inspired globally distributed SQL databases such as Yugabyte DB are solving every core issue of the past and hence are laying the foundation for highly reliable and highly resilient data infrastructure in the cloud native era. Application architects responsible for launching business-critical microservices using cloud-native principles today have to no longer suffer from the limitations of legacy databases.
What’s Next?
- Compare Yugabyte DB in depth to databases like Google Cloud Spanner, Cockroach DB and Amazon Aurora.
- Get started with Yugabyte DB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


