Relational Data Modeling with Foreign Keys in a Distributed SQL Database
July 2, 2019
Note added on October 31, 2019
A lot has happened since this post was published in July 2019. Back then, the current YugabyteDB version was 1.2.10. And now, it’s 2.0.3. My original text included some caveats and comments like “Until this support is added in a future release…”. Now, no caveats are needed. I therefore revised my text and the companion downloadable code to remove all reference to those earlier, interim, restrictions.
Primary and foreign key constraints are as essential to a relational database as are tables and columns—without these, you cannot implement a design that conforms to the relational model. Their implementation is a technical challenge. For example, when child rows are inserted, their parent rows must be efficiently restricted; and when parent rows are deleted, multi-table transactions are needed. Nevertheless, monolithic SQL databases such as PostgreSQL, MySQL, and so on have supported foreign key constraints since time immemorial. However, the implementation challenges in a distributed SQL database are very much greater because the affected rows might span many table shards spread across many different nodes in the cluster. Ensuring low latency and high throughput in such a distributed database becomes a very important design concern.
YugabyteDB 2.0 delivers production readiness for Yugabyte SQL (YSQL), our high-performance, fully-relational distributed SQL API. Here is the announcement. And, among other features that you expect in a SQL database, it supports foreign key constraints.
This post highlights the need for relational data modeling with foreign keys in business-critical apps as well as provides a complete working example of foreign keys in YSQL. It concludes with a note on why foreign keys have traditionally not been supported in distributed databases prior to the advent of distributed SQL databases like YugabyteDB.
Why Developers Love Foreign Keys
Foreign keys enforce referential integrity constraints that are usually tied directly to the application’s business logic. One such key defines a reference relationship from one or many rows in a table that is constrained, the so-called child table, to exactly one row in a referred-to table, the so-called parent table. The reference source is a list of one or more columns in the child table; and the reference target is a list of exactly corresponding columns in the parent table. A parent row may have one or many child rows. A child row points to its parent row by recording the value of the parent row’s primary key; and a child row cannot exist unless it points to a parent row.
The dependency of child rows upon their parent row implies that the foreign key constraint’s definition must specify the action to be taken when a parent row is deleted. When no column that participates in a data rule can be null, there are only two choices: either to delete all of the child rows together with their parent row; or to resist the attempted delete by causing an error. The same applies for the attempt to update the primary key of a parent row. If you follow the strict school of database design thought that insists that primary key values are immutable, then it’s enough to specify that an attempt to change the value of a parent row’s primary key will cause an error. As a developer, having the database do all the tracking and enforcement that comes with foreign keys, is certainly a welcome relief. The alternative situation of building all this directly into the application logic is simply maintaining a long-term complexity without any data integrity guarantees.
A Simple Use Case
I’ve chosen one of the canonical examples that are used to illustrate proper normalization and that imply the use of foreign key constraints. Picture a retailer that has an inventory of items for sale—implying a table of items—and that takes orders from customers to whom the items are to be delivered—implying a table of orders. The orders table must specify the set of ordered items. Relational database design insists that a set of facts, like an item and all of its associated information, is represented just once. Therefore, a row that records the facts about an order must not explicitly record facts about the ordered items but, rather, must point to these in the items table. Moreover, a single row in one table cannot point directly to many rows in another table because its column values (in a purist approach) must be scalar. This implies, therefore, a table of order lines, where the row for each ordered item points both to the order to which it belongs and to the item that is ordered. Similarly, the row for an order must not explicitly represent the facts about the customer that placed the it because a customer might place many different orders. Rather, there must be a table of customers, and an order row must point to the customer that created the order.
These principles lead to the table design that the picture below shows. The so-called crow’s foot is at the child table. The other end of the line that denotes the foreign key constraint is at the parent table).
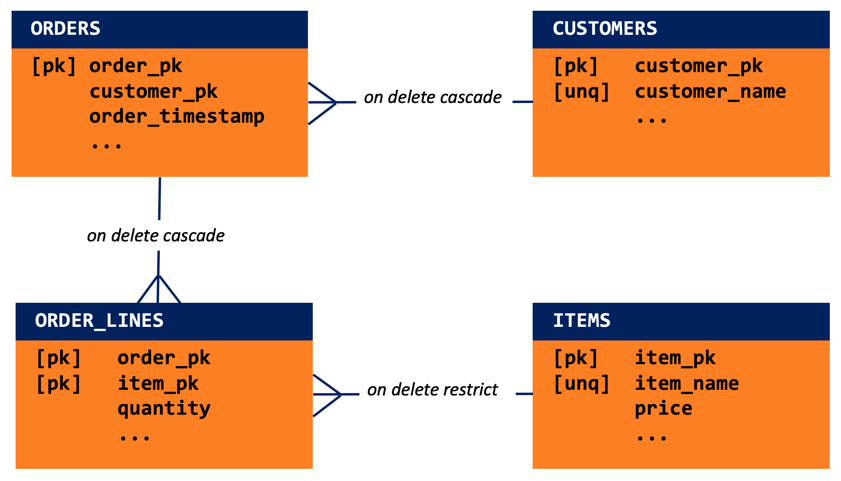
- The customers table uses a numeric surrogate primary key which is automatically generated from a sequence. Because this is not found in the real world that the table models, there must also be a not null, unique business key. The natural choice is the customer’s email address. (Incidentally, this emphasizes the value of a surrogate primary key over a natural primary key: a customer can be uniquely identified by its preferred email address, but might very well change this from time to time. If the value of a natural key is changed, then the new value must be propagated to all rows in all of its child tables.) I’ll use the customer’s name instead of the email address to make the values in the code example easier to read. The ellipsis indicates various other facts, like the customer’s “preferred” status, that the business might want to record. Some of these, like delivery address, might be multi-valued. This would imply a table of addresses. And because several customers might specify the same delivery address, this would imply another so-called intersection table. (The order_lines table is such an intersection table.) It’s easy to see how the proper table design for modern businesses can require very many tables and very many foreign key constraints.
- The items table, too, uses a numeric surrogate primary key which is automatically generated from a sequence. I’ve chosen the item’s name to illustrate the notion of the not null, unique business key. The ellipsis indicates various other facts, like price, quantity in stock, and so on.
- The orders table reflects common practice. Its automatically generated numeric primary key serves as the business key. It uses a foreign key constraint to point to the customer that placed the order. The ellipsis indicates various other facts, like when it was created, its status (“under construction”, “placed”, “in transit”, “fulfilled”) and so on.
- The order_lines table has a foreign key constraint to the orders table and another one to the items table. The primary key is defined on the column list (order_pk, item_pk). The ellipsis indicates various other facts like the quantity of items ordered and the discount to be applied to the ordered item’s list price because a promotion code was used.
The retailer requires that the table design supports various business functions, constrained appropriately by rules. Here are some examples:
- Create a new customer.
- Create a new item.
- Create a new empty order for a specified customer.
- Add an item to an existing order specified by its order number, the item name, and quantity ordered.
- Delete an item. Must fail if it is referenced by existing order lines.
- Calculate the total cost of an order.
- Delete a customer and consequentially delete all its orders with their order lines.
SQL with Foreign Keys in Action
The SQL code presented in this section is available in .sql files and can be run at the prompt of ysqlsh, the YSQL Shell, by using the \i command. You can download a .zip of the .sql files here.
First, follow the first two steps in the Quick Start to install YugabyteDB and create a local cluster. Then connect to ysqlsh by using instructions from the Explore YSQL section.
Now, we are ready to create some tables.
Get a clean start.
drop table if exists order_lines; drop table if exists orders; drop table if exists items; drop table if exists customers;
Notice that the sequence of “drop” executions is critical. You cannot drop a parent table when it has child tables. For the same reason, a parent table must be created before its child tables.
Create the customers table.
create table customers(
customer_pk int
generated always as identity,
customer_name text
constraint customer_name_nn not null
constraint customer_name_unq unique,
constraint customers_pk primary key(customer_pk));I decided to write all the primary key and foreign key constraint definitions at table level where they can be easily seen. Some people prefer column-level constraints, and YugabyteDB supports these. You can establish a foreign key constraint either at create table time or, later, using alter table. My code illustrations for this post establish them only at create table time.
Create the items table.
create table items(
item_pk int
generated always as identity,
item_name text
constraint items_name_nn not null
constraint items_name_unq unique,
price money
constraint price_nn not null,
constraint items_items_pk primary key(item_pk));
Create the orders table.
create table orders(
order_pk int
generated always as identity,
customer_pk int
constraint customer_pk_nn not null,
-- Implicitly coerce all timestamp values to UTC
order_timestamp timestamp
default current_timestamp
constraint order_timestamp_nn not null,
constraint orders_pk primary key(order_pk),
constraint customer_pk_fk foreign key(customer_pk)
references customers(customer_pk)
match full
on delete cascade
on update restrict);
create index orders_customer_pk on orders(customer_pk);
The match full clause says that no value in the foreign key column list may be null. My implementation enforces this rule at a higher level of granularity with not null constraints on all columns that participate in referential integrity constraints.
The on delete cascade clause reflects the business rule that a parent customer may be deleted and, that when this is done, all of its child orders and grandchild order lines must be silently deleted in the same transaction. The on update restrict clause reflects the business rule that primary key values are immutable.
The column list on which a foreign key constraint is defined should have an index to benefit the performance of the restrict and cascade variants of on delete and on update.
Create the order_lines table.
create table order_lines(
order_pk int
constraint order_pk_nn not null,
item_pk int
constraint item_pk_nn not null,
quantity int
constraint quantity_nn not null
constraint quantity_n_neg check (quantity > 0),
constraint order_lines_pk primary key(order_pk, item_pk),
constraint order_pk_fk foreign key(order_pk)
references orders(order_pk)
match full
on delete cascade
on update restrict,
constraint item_pk_fk foreign key(item_pk)
references items(item_pk)
match full
on delete restrict
on update restrict);
create index order_lines_order_pk on order_lines(order_pk);
create index order_lines_item_pk on order_lines(item_pk);
The on delete cascade for the reference to the orders table reflects the business rule that a parent order may be deleted and, that when this is done, all of its child order lines must be silently deleted in the same transaction.
In contrast, the on delete restrict for the reference to the items table reflects the business rule that you cannot delete an item when at least one order line refers to it.
With the tables in place, we can now show the implementation of some illustrative business functions.
Create some customers.
insert into customers(customer_name)
values
('Mary'),
('Alice'),
('Helen'),
('Bill'),
('Dave'),
('John');
Create some items.
insert into items(item_name, price)
values
('after shave', 8.99),
('deodorant', 5.99),
('soap', 2.99),
('toothpaste', 2.99),
('razor blades', 9.99),
('aspirin', 7.99),
('cotton wool', 3.99);
Create a new empty order for customer Helen.
insert into orders(customer_pk) values( (select customer_pk from customers where customer_name = 'Helen')) returning order_pk;
Notice the use of the returning clause. The UI needs to let a user create a new order and immediately add order lines to it without having to note down the order number when it’s first created and then having to enter it time and again for each order line. The application code looks after this by using the returned value of the system-generated order number, and by informing the user what order number was generated when the order is submitted.
Add one order line for the specified quantity of a particular item.
insert into order_lines(order_pk, item_pk, quantity) values( -- this is the value that was noted programmatically -- when the order was created. 1, (select item_pk from items where item_name = 'soap'), 5);
Add several more order lines for the specified quantities of various items.
insert into order_lines(order_pk, item_pk, quantity)
select
1, -- the order number
item_pk,
case item_name
when 'aspirin' then 2
when 'toothpaste' then 1
when 'cotton wool' then 8
end as quantity
from items
where item_name in ('aspirin', 'toothpaste', 'cotton wool');
Create a new empty order for customer Dave and insert several order lines.
insert into orders(customer_pk)
values(
(select customer_pk
from customers
where customer_name = 'Dave'))
returning order_pk;
insert into order_lines(order_pk, item_pk, quantity)
select
2, -- the order number
item_pk,
case item_name
when 'after shave' then 5
when 'deodorant' then 7
when 'soap' then 3
when 'aspirin' then 4
when 'cotton wool' then 5
end as quantity
from items
where item_name in
('after shave', 'deodorant', 'soap', 'aspirin', 'cotton wool');
Create a second new empty order for customer Helen and insert several order lines.
insert into orders(customer_pk)
values(
(select customer_pk
from customers
where customer_name = 'Helen'))
returning order_pk;
insert into order_lines(order_pk, item_pk, quantity)
select
3, -- the order number
item_pk,
case item_name
when 'after shave' then 3
when 'deodorant' then 2
when 'soap' then 5
when 'toothpaste' then 7
when 'aspirin' then 8
when 'cotton wool' then 4
end as quantity
from items
where item_name in
('after shave', 'deodorant', 'soap',
'toothpaste', 'aspirin', 'cotton wool');
Basic two-table inner join: list all the orders.
select c.customer_name as "customer", o.order_pk as "order#", to_char(o.order_timestamp, 'Mon-dd hh24:mi') as "date" from orders o inner join customers c using(customer_pk) order by c.customer_name, o.order_pk;
Here are the results of this query:
customer | order# | date ---------+--------+-------------- Dave | 2 | Jul-02 11:00 Helen | 1 | Jul-02 10:58 Helen | 3 | Jul-02 11:03
List everything with an inner join between all four tables.
select
c.customer_name as "name",
order_pk as "order#",
to_char(o.order_timestamp, 'Mon-dd hh24:mi') as "date",
i.item_name as "item",
i.price,
ol.quantity as "qty"
from order_lines ol inner join orders o using (order_pk)
inner join customers c using (customer_pk)
inner join items i using (item_pk)
order by c.customer_name, order_pk, item_name;Notice that the surrogate primary key columns, with the exception of order_pk, are not included in the select list because they implement the “plumbing” and don’t belong in the business world. Order_pk is icluded because, while it is generated, it does surface into the business world. Here are the results of this query:
name | order# | date | item | price | qty ------+--------+--------------+-------------+-------+----- Dave | 2 | Jul-02 11:00 | after shave | $8.99 | 5 Dave | 2 | Jul-02 11:00 | aspirin | $7.99 | 4 Dave | 2 | Jul-02 11:00 | cotton wool | $3.99 | 5 Dave | 2 | Jul-02 11:00 | deodorant | $5.99 | 7 Dave | 2 | Jul-02 11:00 | soap | $2.99 | 3 Helen | 1 | Jul-02 10:58 | aspirin | $7.99 | 2 Helen | 1 | Jul-02 10:58 | cotton wool | $3.99 | 8 Helen | 1 | Jul-02 10:58 | soap | $2.99 | 5 Helen | 1 | Jul-02 10:58 | toothpaste | $2.99 | 1 Helen | 3 | Jul-02 11:03 | after shave | $8.99 | 3 Helen | 3 | Jul-02 11:03 | aspirin | $7.99 | 8 Helen | 3 | Jul-02 11:03 | cotton wool | $3.99 | 4 Helen | 3 | Jul-02 11:03 | deodorant | $5.99 | 2 Helen | 3 | Jul-02 11:03 | soap | $2.99 | 5 Helen | 3 | Jul-02 11:03 | toothpaste | $2.99 | 7
Notice the duplication of the values for customer_name and order_timestamp. Usually, application code will process these results to present customer_name and order_timestamp once as a header and to list the values for item_name, price and quantity under this. This is a very common pattern, and experience has shown that better performance is delivered this way than by doing two round trips first to get the values for customer_name and order_timestamp and then next to get the order items for this order.
List the items for order #1.
select
c.customer_name as "customer",
to_char(o.order_timestamp, 'Mon-dd hh24:mi') "timestamp",
i.item_name as "item",
i.price,
ol.quantity as "qty"
from order_lines ol inner join orders o using (order_pk)
inner join customers c using (customer_pk)
inner join items i using (item_pk)
where order_pk = 1
order by i.item_name;This uses the same four-table inner join as the previous query, adds a restriction, and removes the columns that the restriction uses from the select list. Here are the results of this query:
customer | timestamp | item | price | qty ---------+--------------+-------------+-------+----- Helen | Jul-02 10:58 | aspirin | $7.99 | 2 Helen | Jul-02 10:58 | cotton wool | $3.99 | 8 Helen | Jul-02 10:58 | soap | $2.99 | 5 Helen | Jul-02 10:58 | toothpaste | $2.99 | 1
Compute the total cost of all orders.
select
c.customer_name as "name",
order_pk as "order#",
to_char(o.order_timestamp, 'Mon-dd hh24:mi') as "date",
sum(i.price*ol.quantity) as "total"
from order_lines ol inner join orders o using (order_pk)
inner join customers c using (customer_pk)
inner join items i using (item_pk)
group by customer_name, order_pk, order_timestamp
order by customer_name, order_pk;Here are the results of this query:
name | order# | date | total ------+--------+--------------+--------- Dave | 2 | Jul-02 11:00 | $147.76 Helen | 1 | Jul-02 10:58 | $65.84 Helen | 3 | Jul-02 11:03 | $154.71
Delete an unreferenced item.
delete from items where item_name = 'razor blades';
Delete a referenced item.
delete from items where item_name = 'aspirin';
The attempt fails with this error: update or delete on table “items” violates foreign key constraint “item_pk_fk” on table “order_lines”.
Cascade delete customer Helen.
delete from customers where customer_name = 'Helen';
This quietly succeeds and removes not only the specified customer by also all of its child orders (with the data created earlier, there is just one) and all of its grandchild order lines (there are two of these). The obvious select * queries confirm this.
Try to create an order line for an order that doesn’t exist.
insert into order_lines(order_pk, item_pk, quantity) values( -- There is no order #42. 42, (select item_pk from items where item_name = 'aspirin'), 2);
The attempt fails with this error: insert or update on table “order_lines” violates foreign key constraint “order_pk_fk”
Why Foreign Keys are Challenging in a Distributed SQL Database
The enforcement of a foreign key constraint requires that appropriate checks, or side-effects, are executed when relevant data changes are made. Here are two examples in the context of the scenario that I described in this post:
- When an order_lines row is inserted, the row in the orders table whose primary key is specified by the value in the foreign key column, order_lines.order_pk, must exist.
- When an orders row is deleted, all of its child order_lines rows must be deleted.
Moreover, such checks and side-effects must be done properly when sessions make competing changes in concurrent transactions whose SQL statement executions interleave.
YugabyteDB supports both the serializable and the snapshot transaction isolation levels. The definition of the serializable level implies that checks and side-effects that enforce foreign key constraints will operate correctly. As you would expect, the implementation of serializable transactions is more elaborate than that of snapshot transactions and is, therefore, less performant. So users prefer to use serializable transactions only for scenarios that might violate special user-specified data rules and they expect that standard data rules like foreign key constraints will be enforced properly at the snapshot level. In other words, they expect a special-case implementation, within the simpler snapshot implementation, of what comes “for free” within the serializable implementation. Standard PostgreSQL, for example, provides exactly this.
Implementing support for both serializable transactions in general, and for the special case of foreign key constraint enforcement in snapshot transactions, is more challenging in a distributed SQL database like YugabyteDB than it is in a monolithic SQL database like PostgreSQL. This is because, in the general case, transactions are distributed—in other words, they span data that is managed on different nodes in the multi-node cluster. Notwithstanding the scale of the challenge, YugabyteDB has supported serializable transactions since Version 1.2.0 (when the YSQL subsystem still had Beta status). But through Version 2.0.2, any operation that might violate a foreign key constraint had to be performed in a serializable transaction. We’re pleased to announce that, from Version 2.0.3, YugabyteDB supports such operations in snapshot transactions.
Read the documentation section Distributed ACID Transactions and the blog post Distributed PostgreSQL on a Google Spanner Architecture – Storage Layer for more information.
Summary
Application developers whose transactional use cases are adequately met by a monolithic database naturally choose a SQL database because of the huge benefits these bring for implementing new business cases quickly without compromising data integrity. And application developers whose use cases demand a distributed database have, during the previous many years, simply been forced to give up SQL and to invent and implement their data model from scratch. This practice brought a consequent need to program all business uses explicitly and, quite often, to redesign and reimplement the NoSQL data model as new cases arrived. They made this painful compromise because the need for large scale data volumes and numbers of concurrently submitted transactions, and automatic fault tolerance, trumped all other concerns.
This post has shown that developers can now meet the requirements that demand a distributed database and yet not compromise to give up the core benefits of relational data modeling. The code examples illustrate a canonical example of a database design within the relational model, and show how a distributed SQL database like YugabyteDB can implement requirements that would take huge amounts of programming in the regime of a home-grown, ad hoc, data model in just a few lines of code.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and Amazon Aurora.
- Get started with YugabyteDB on the cloud or container of your choice.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


