The Distributed Database Behind Twitter
October 15, 2020
Twitter is one of the world’s favorite places for people and brands to connect online. Powering a global service that helps people share everything from breaking news and entertainment to sports, politics, and everyday interests takes infrastructure that can adapt and evolve over time.
In his talk at the 2020 Distributed SQL Summit, Mehrdad Nurolahzade, engineer on the real-time infrastructure team at Twitter, walks us through the distributed database behind Twitter, including their journey from MySQL to Cassandra, and then from Cassandra to building their own distributed database called Manhattan, ending with a glimpse into the future. Here’s the playback and tl;dr of the presentation.
The Distributed Database Behind Twitter
Mehrdad’s talk starts out describing the early days of Twitter’s architecture, starting in the mid 2000’s: “The architecture at this point is quite simple; it’s basically a monolith, which is internally referred to as the Monorail. It’s Ruby on Rails. … And this is backed by a single MySQL server with a single leader and a single follower.”
Over the years, the rapid rise in popularity of the Twitter website causes engineers to strive for greater scalability. They quickly identify the monolith as a source of pain for scalability. And, at the data layer, engineers attempt to improve the performance of MySQL.
But as the popularity continues to skyrocket, Twitter’s engineering team embarks on an ongoing IT evolution, evaluating and executing enhancements of many kinds to provide greater reliability and speed, including:
- Moving from a monolith to microservices
- Migrating to multiple datacenters
- Using Cassandra for horizontal scalability and other use cases
- Moving from Cassandra to building out Manhattan as its custom in-house distributed database solution
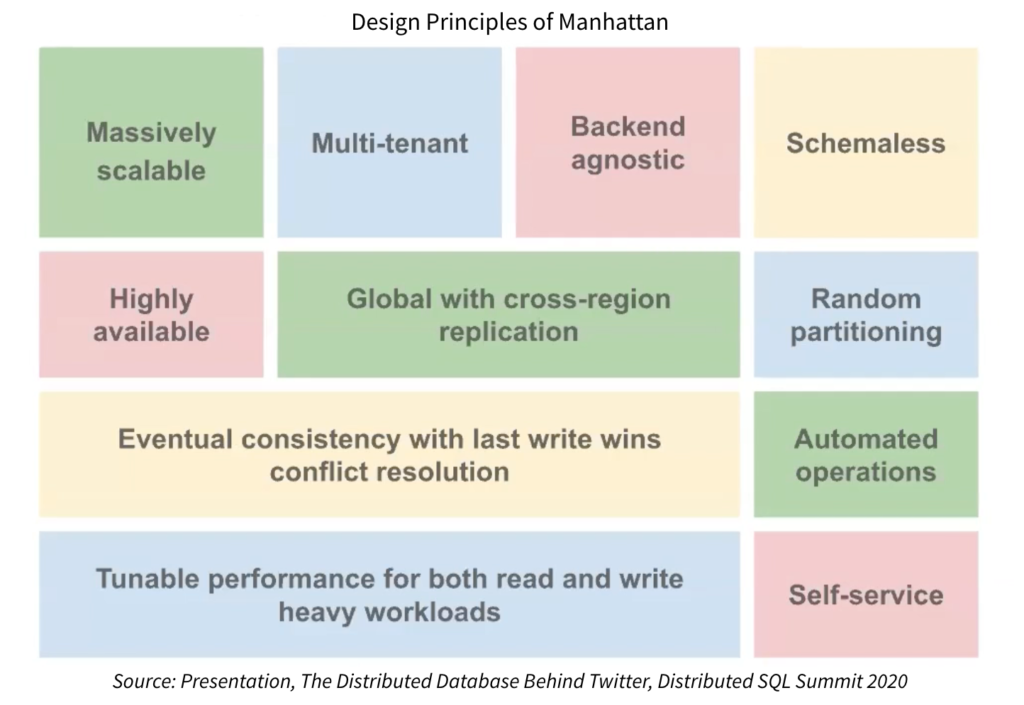
Here’s a glimpse into Manhattan’s scale today:
- 20 production clusters
- more than 1000 databases
- powered by tens of thousands of nodes
- serving many petabytes of data, at a rate of tens of millions of requests per second
However, operations at the size of Manhattan are difficult. To help streamline operations, Twitter built Genie to convert operational knowledge to automation.
Evolution continues today, including a continued focus on compliance, finalizing the migration to RocksDB, moving to Kubernetes, adopting Kafka, and integrating public cloud storage into the import and export pipelines.
Although Manhattan was custom built to meet the need of Twitter’s use cases, and Twitter’s engineering team will continue to build Manhattan, the diversity of use cases in a company of its size can’t be served by a single database.
“Looking at the distributed database landscape, we see that it has significantly evolved since 2012, which [is when] we decided to build Manhattan,” said Mehrdad. Mehrdad added, “at Twitter, we hypothesize that some of these solutions can potentially complement or maybe even replace our internal offerings in the future.”
Want to See More?
Check out all the talks from this year’s Distributed SQL Summit including Pinterest, Mastercard, Comcast, Kroger, and more on our Vimeo channel.


