Practical Tradeoffs in Google Cloud Spanner, Azure Cosmos DB and YugabyteDB
January 25, 2018
Updated April 2019.
The famed CAP Theorem has been a source of much debate among distributed systems engineers. Those of us building distributed databases are often asked how we deal with it. In this post, we dive deeper into the consistency-availability tradeoff imposed by CAP which is only applicable during failure conditions. We also highlight the lesser-known-but-equally-important consistency-latency tradeoff imposed by the PACELC Theorem that extends CAP to normal operations. We then analyze how modern cloud native databases such as Google Cloud Spanner, Azure Cosmos DB and YugabyteDB deal with these tradeoffs.

Consistency vs. Availability
Revisiting CAP

Eric Brewer, author of the CAP Theorem, explains in this blog post that:
Distributed systems must choose between Consistency and 100% Availability in the presence of network Partitions.
A deeper dive into the definitions is in order.
Consistency
Every read receives either the most recent write or an error. In other words, all members of the distributed system have a shared understanding of the value of a data element from a read standpoint. This guarantee is also known as linearizability or linearizable consistency.
100% Availability
Every read or update receives a non-error response. Since every operation succeeds without errors, the availability of the system is 100%.
Network Partitions
These are not necessarily restricted to the network per se but refer to the general class of hardware and software failures (including message losses) that force one or more members of a distributed system to deviate from other members of the system.
Given that tolerance to network partitions (i.e. P) is a must-have in any desirable distributed system, such a system can be either a CP system (that chooses Consistency over Availability) or can be an AP system (that chooses Availability over Consistency). The most important caveat here is that no such choice is needed in absence of network partitions — a system can be simultaneously Consistent and Available in the absence of failures. As discussed in the next section, the tradeoff between consistency and latency becomes more important during such normal operations.
Practical Implications
Since AP systems always provide a non-error response to reads and writes, they seem like the obvious choice in user-facing applications. However, there are 2 key concerns to be aware of.
First, application development complexity can be onerous in AP systems. The loss of the ability to clearly reason about the current state of the system makes developers add compensating application logic for safe handling of stale reads (resulting from recent writes not yet available on the serving node) and dirty reads (resulting from the lack of rollback of a failed write on the serving node). Hence the recommendation to choose a CP system whenever possible.
Second, the operational cost of achieving true 100% availability is high in terms of the infrastructure and labor effort necessary. More importantly, user-facing applications have failure points outside of the database that can lead to the application tier getting partitioned away from the database tier. In such cases, having a 100% database availability doesn’t help in achieving 100% application availability. As we will see below, giving up on a mere 0.01% availability leads to more practical and productive ways of building applications.
Consistency vs. Latency
Understanding PACELC

Daniel Abadi, author of the PACELC Theorem, describes PACELC in his original paper as
if there is a partition (P), how does the system trade off availability and consistency (A and C); else (E), when the system is running normally in the absence of partitions, how does the system trade off latency (L) and consistency (C)?
PACELC extends CAP to normal conditions (i.e. when the system has no partitions) where the tradeoff is between latency and consistency. Systems that allow lower latency along with relaxed consistency are classified as EL while systems that have higher latency along with linearizable consistency are classified as EC.
Practical Implications
PACELC gives distributed database designers a more complete framework to reason about the essential tradeoffs and therefore avoid building a more limiting system than necessary in practice.
Comparisons
Note that both CAP and PACELC theorems help us better understand single-row linearizability guarantees in distributed databases. Multi-row operations come under the purview of ACID guarantees (with the Isolation level playing a big role in how to handle conflicting operations) that are not covered by CAP and PACELC.
- From CAP standpoint, Google Cloud Spanner and YugabyteDB are CP databases that provide very high availability.
- From PACELC standpoint, Google Cloud Spanner and YugabyteDB are EL databases that allow lower latency operations by tuning consistency down.
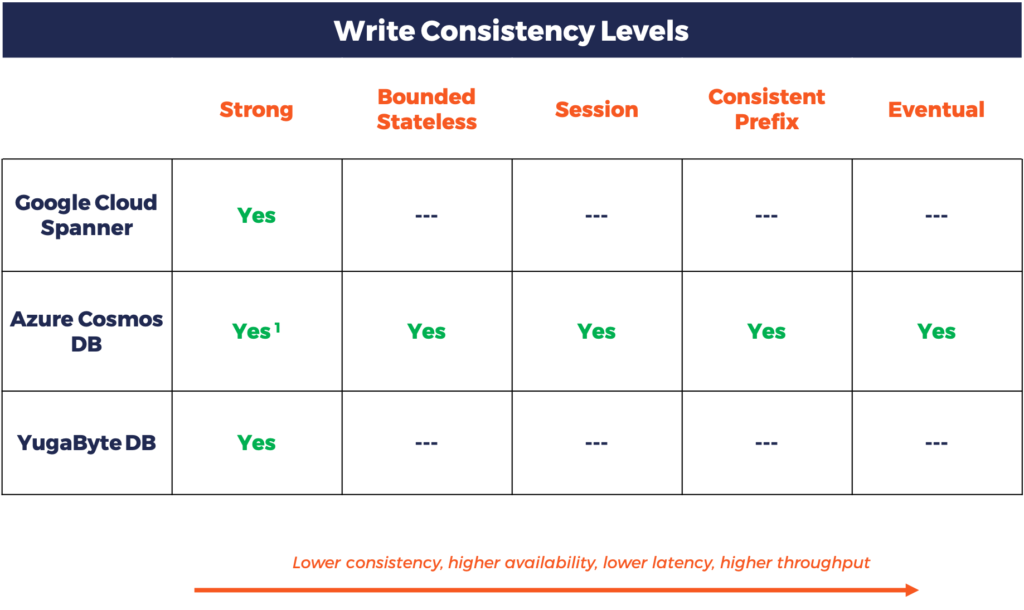
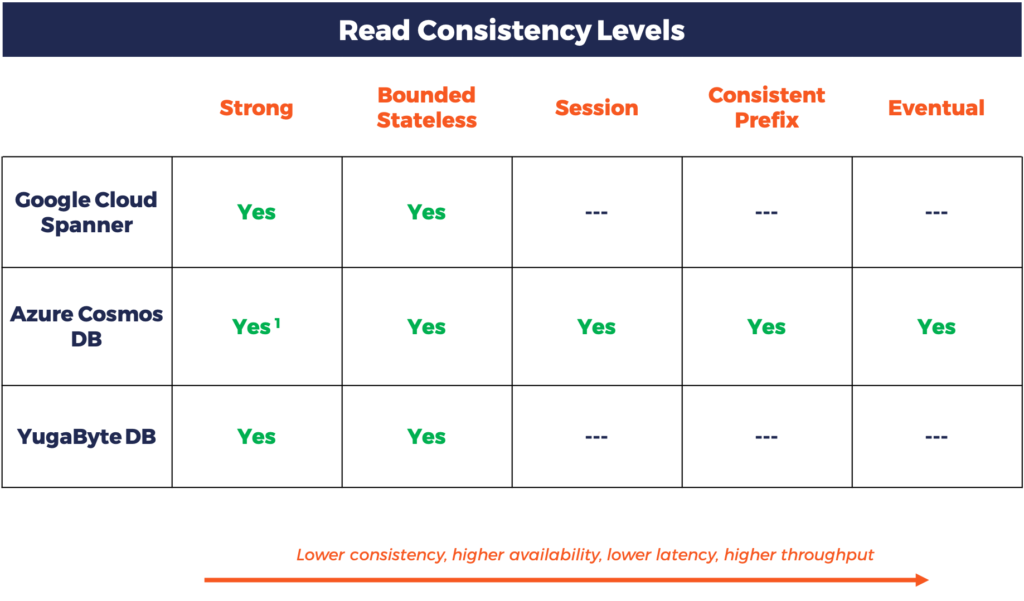
- Azure Cosmos DB can be used in multiple configurations in the CP & PACELC context – Strong, CP/EL (Bounded Stateless), CP/ECL (Session) and AP/EL (Consistent Prefix/Eventual). More details here.
- While both Google Spanner and Azure Cosmos DB are proprietary managed services, YugabyteDB is an open source, cloud native, distributed SQL DB that is available under the Apache 2.0 license.
Google Cloud Spanner

Google Cloud Spanner divides data into chunks called splits, where individual splits can move independently from each other and get assigned to different nodes. It then creates replicas of each split and distributes them among the nodes using Paxos distributed consensus protocol. Within each Paxos replica set, one replica is elected to act as the leader. Leader replicas are responsible for handling writes, while any read-write or read-only replica can serve timeline-consistent (i.e. no-out-of-order) read requests without communicating with the leader.
Since it runs on Google’s proprietary network and hardware infrastructure (including the globally synchronized TrueTime clock), Spanner is able to limit network partitions significantly and even guarantee availability SLAs of 99.999% even in multi-region clusters. In the event of network partitions, the replicas of the impacted splits (whose leaders got cut off from the remaining replicas) form two groups: a majority partition that can still establish a Paxos consensus and one or more minority partitions that cannot establish such a consensus (given the lack of quorum). Read-write replicas in the majority partition elect a new leader while all replicas in the minority partitions become read-only. This leads to high write availability on the majority partition with minimal disruption (which is essentially leader election time) and uninterrupted read availability.
Azure Cosmos DB

Azure Cosmos DB auto partitions data into multiple physical partitions based on the configured throughput. Each partition is then replicated for high availability in the same region using a custom leader-based consensus protocol — a partition’s leader and its followers are called as the replica-set. Replica-sets can also be replicated to other regions using “super replica-sets” known as partition-sets. Developers now choose between five consistency models along the consistency spectrum — strong (linearizable), bounded staleness, session, consistent prefix, and eventual (out-of-order).
YugabyteDB

YugabyteDB’s sharding, replication and transactions architecture is inspired by that of Google Spanner. It auto shards data into a configurable number of tablets and distributes those tablets evenly among the nodes of the cluster. Additionally, each tablet is replicated to other nodes for fault-tolerance using the Raft distributed consensus protocol which is widely considered to be more understandable and practical than Paxos. One replica in every tablet’s replica set is elected as the leader and the other replicas become followers. Writes have to go through the tablet leader while reads can go through on any member of the replica set depending on the read consistency level (default is strong). During network partitions (including node failures), a majority partition and a minority partition similar to that of Google Spanner get created. This same approach is used for both single region as well as globally consistent multi-region deployments. Note that a leader lease mechanism ensures that only a single leader can be present for any given shard at any given point of time. This is key to ensuring that shard leaders can themselves serve strongly consistent reads without using any quorum-based consensus on the read path. In the absence of the hardware-defined TrueTime atomic clock, a combination of Hybrid Logical Clocks (HLC) and clock skew tracking are used to create a software-defined atomic clock that then powers multi-shard ACID transactions.
As a resilient and self-healing system, YugabyteDB ensures that the replicas in the majority partition elect a new leader among themselves in a few seconds and accept new writes immediately thereafter. The design choice here is to give away availability in favor of consistency on failure occurrence while also limiting the loss of availability to only a few seconds till the new tablet leaders get elected. The leader replicas in the minority partition lose their leadership in a few seconds and hence become followers. At this point, the majority partition is available for both reads and writes while minority partitions are available only for timeline-consistent (i.e. no-out-of-order) reads but not for writes. After the failure is corrected, the majority partition and minority partition heal back into a single Raft consensus group and continue normal operations.
YugabyteDB currently offers two consistency levels, strong and bounded staleness, for read operations. It doesn’t support an eventual consistency level for reads. Write operations are always strongly consistent similar to Spanner.
Summary
The consistency and latency tradeoffs for the 3 cloud native databases can be summarized as below.
Write Operations
Read Operations
We at Yugabyte are excited about the work that the Spanner and Cosmos DB teams are doing with respect to building truly global-scale operational databases. However, as enterprises move to an increasingly multi-cloud and hybrid cloud era, we do not believe they should get locked into expensive, proprietary managed services. As can be seen from the comparisons above, YugabyteDB offers strong write consistency and tunable read consistency (with optional read-only replicas for remote regions) in both single region and multi-region deployments. It does so on an open source core with a SQL API that is compatible with PostgreSQL. We believe these are exactly the right ingredients to power cloud native business-critical applications in the enterprise.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


