My Yugabyte Journey into Distributed SQL Databases
January 21, 2022
This post was written by Nim Wijetunga, a Yugabyte intern during fall 2021. Nim’s currently a software engineering student at the University of Waterloo in Waterloo, Ontario, Canada.
My journey into distributed databases began in early 2021. I was an intern at Snowflake and was part of the core FoundationDB (FDB) team. FDB is an open source distributed key-value store. Snowflake and Apple are currently the largest contributors (and maintainers) of FDB. For my internship I mainly worked on CDC (Change Data Capture) mechanisms. I immediately found an interest in distributed databases because of the plethora of interesting problems to solve. As a result, I joined Yugabyte for my final internship.
The application process was fairly simple. It consisted of a coding challenge followed by two technical interviews with engineers. There was also a final meeting with Bogdan-Alexandru Matican, the Director of Engineering for the Distributed Storage and Transactions team. During the process, I got to learn about many of the interesting problems Yugabyte would be tackling in the near future. The idea of getting to work with the Yugabyte team on YugabyteDB, an open source distributed SQL database, seemed very enticing. It was an easy decision to accept the offer!
Part 1: Onboarding and getting started
Before I knew it, I was getting ready to start my internship at Yugabyte. Since the internship was remote, a couple of my friends and I decided to live in Vancouver, British Columbia for the fall term. Yugabyte was more than happy to accommodate.
On my first day I met my mentor, Rob Sami, who I would be working closely with over the next four months. Over the next week, I began a few starter tasks which spanned across different areas of the core database. These tasks were helpful in getting me acquainted with different areas of our storage system, including (but not limited to): our data sharding layer, networking interface, consensus protocol (Raft), and testing infrastructure. During my first few weeks, I had a lot of support from Rob and other engineers across the team. It made the onboarding process onto the YugabyteDB codebase very smooth. Fast forward a couple of weeks, and I was now acquainted with certain areas of the database and ready for more complicated tasks.
Tablet splitting in my first six weeks
At the beginning, most of my contributions related to automatic tablet splitting, a relatively new feature of YugabyteDB. In YugabyteDB, a tablet represents sharded data for a user table. A given tablet can have 1 (or more) replicas (peers) with a single tablet being the “leader-peer”. Furthermore, the data in a tablet compacts or uncompacts Sorted Sequence Table (SST) files.
Tablet splitting is the process of breaking up a relatively large tablet into two smaller tablets of roughly equal size. After a tablet split occurs, compaction generally happens on each newly created child tablet. Previously, when a parent tablet split into two child tablets, YugabyteDB would mark the split complete, even though SST file compaction hadn’t finished on all peers for a given child leader-peer. The below figure illustrates the before and after.
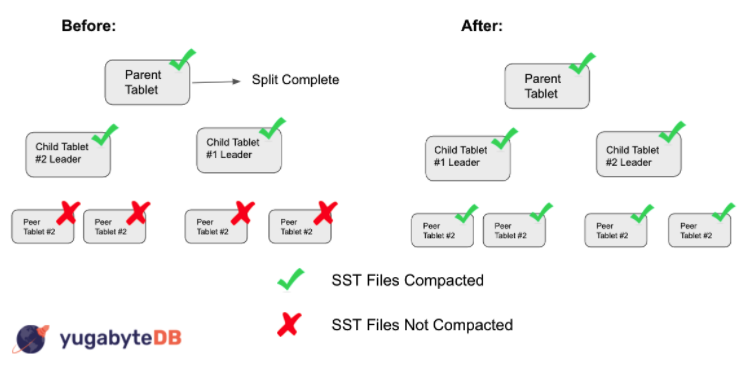
Before, YugabyteDB marked a split as complete even though the given child tablet leaders had uncompacted peers. Now, as seen in after, YugabyteDB waits for all peers to compact SST files and then marks the split as complete.
In the event that there were many requested splits, this was problematic because YugabyteDB would process new split requests based on the number of split requests still outstanding. Incorrectly marking a split as complete could end up saturating the system in these instances. My task was to fix this issue by ensuring that a split is only complete once all peers for each leader-peer have compacted their data (as shown in the above figure). As a result, tablet splitting does not over saturate the system.
Part 2: Diving deep into challenging problems
With experience gained, I was ready to tackle a much more challenging problem. It touched a core part of our consensus algorithm. Consensus is a fundamental problem in fault-tolerant distributed systems and involves multiple servers agreeing on values. YugabyteDB implements Raft to achieve consensus between distributed tablet leaders and followers. Let’s highlight one aspect of the algorithm called heartbeating.
In a YugabyteDB cluster, a single tablet leader-peer can have one or more follower-peers spanning across one or more different YB-TServers. The YB-TServers in a YugabyteDB cluster span across availability zones, across regions, and across cloud providers. According to Raft, the leader-peer must heartbeat each follower frequently to maintain leadership and prevent followers from starting elections. Check out the below figure for a visual representation.
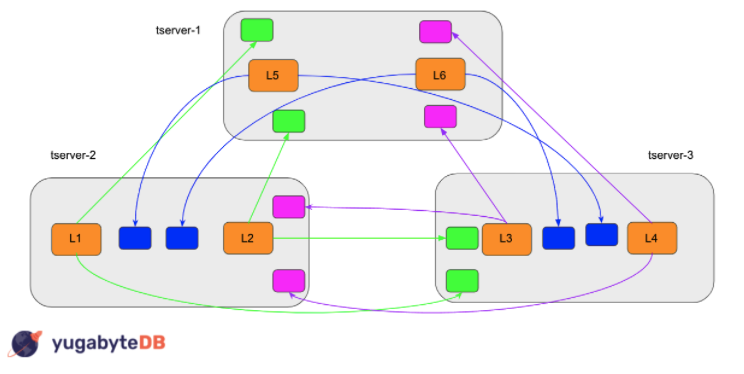
Each tablet leader node (L1, L2, L3, etc..) has 2 followers (peers) on different YB-TServers. Each node must heartbeat these peers once every second to prevent unnecessary elections. For a cluster with 6 tablet leaders, this results in 6 tablets * 1 request/s * 2 peers = 12 requests/s. And for a cluster with 4,000 tablet leaders (with replication factor = 3), we have 4,000 * 1 * 2 = 8,000 request/s (which is a lot of network calls!)
There is a significant CPU cost as we scale Raft to thousands of tablets (i.e., in the case of automatic tablet splitting mentioned above). For example, we determined that an idle cluster (i.e., a cluster that is only doing heartbeats) with 4,000 tablet leaders can consume a significant percentage of CPU. Through perf analysis on sample clusters, we determined that a large chunk of this CPU consumption was the result of how tablets were sending heartbeats: context switching when sending and receiving Remote Procedure Calls (RPC) and serializing and deserializing protobufs.
Into the woods with Multi-Raft
In order to fix this problem, we decided to use a “Multi-Raft” approach that batches heartbeat requests between YB-Tservers. The below figure illustrates Multi-Raft.

With Multi-Raft, YugabyteDB batches all the heartbeat network calls between different YB-Tservers. A batch releases at a certain cadence, usually every 100ms. For a 4,000 tablet leader cluster with a batching interval of 100ms, YugabyteDB sends out—on average—60 requests/s. Before Mult-Raft, a similar YugabyteDB cluster sent out 8,000 requests/s.
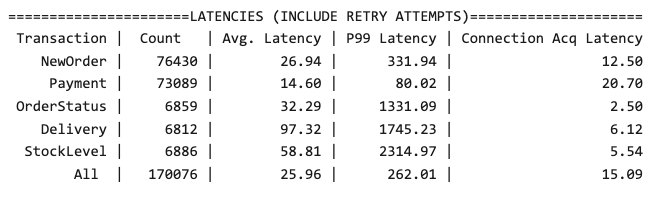
Adding this new layer on top of our existing Raft protocol allowed us to shave off a significant portion of the cluster CPU usage. Referring to our example from before, for 4,000 tablet leaders (with a batching interval of 100ms), we decreased CPU usage by upwards of 15%! To measure performance and validate that Multi-Raft did not cause any performance regressions, we ran the popular OLTP benchmark, TPC-C, on two YugabyteDB clusters: one without Multi-Raft, and one with Multi-Raft, as illustrated in the below figures.
TPC-C latencies before implementing Multi-Raft
TPC-C latencies after implementing Multi-Raft
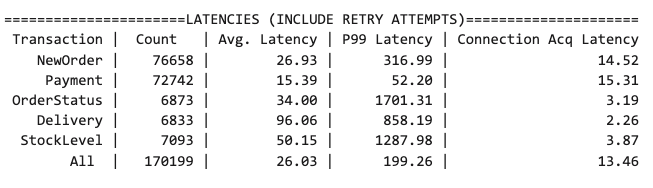
As you can see, the before and after results are statistically indistinguishable (which means no performance regressions!)
All good things must come to an end
I can’t help but reflect on my four months here at Yugabyte. I really enjoyed working on the Multi-Raft project not only because of the end result, but also because of the process: from investigating bottlenecks (using perf), to designing a solution and getting buy-in from senior engineers and management, to programming and testing the solution. My internship at Yugabyte has allowed me to combine theoretical knowledge that I learned at the University of Waterloo with real-life applications.
While the projects I worked on were very interesting, my internship wouldn’t have been as enjoyable if it weren’t for the team. Thank you Rob and Bogdan for your guidance—and for answering my many Slack messages! And, thank you to the rest of the engineering team for working closely with me on all of my projects. Despite being remote, it was a great internship experience. I especially enjoyed the intern events such as professional chocolate tasting lessons and guest lectures by company executives. These events allowed me to meet the other interns and interact with Yugabyte employees in other departments!
Overall, I really enjoyed my time at Yugabyte. This experience has definitely solidified my interest in distributed systems and databases! I am happy to answer any questions you may have on LinkedIn.
Want to join a dynamic company in growth mode? We are currently hiring for a number of open positions across Yugabyte. Discover your next opportunity today!


