Jepsen Testing on YugabyteDB
September 17, 2018
At YugaByte, our mission is to build a robust, reliable, distributed OLTP database. Needless to say, we take correctness and technical accuracy of our claims very seriously. Therefore, we absolutely love a testing framework like Jepsen which helps verify correctness and are fans of Kyle Kingsbury’s work!
Here is a summary of what we have done so far in regards to Jepsen:
- We have performed our own DIY style Jepsen testing
- The YugabyteDB Jepsen testing repository is open source
- For the current suite of Jepsen tests for YugabyteDB that we have tested in a loop, there are no correctness failures detected by Jepsen.
- We are working on adding even more tests into our Jepsen suite.
- The enhancements we made as a part of our Jepsen testing (such as issues 270 and 271 to enable Jepsen testing on CentOS) have been contributed back
- We plan to work with Kyle in the future for a formal Jepsen verification.
With that out of the way, read on for the more detailed account.
Jepsen – verifying what a DB promises
Distributed databases are notoriously hard to test. Because they span multiple nodes, the tests need to verify the assertions of the database under a lot of failure scenarios such as the failure of any node, network partitions or imperfectly synchronized clocks between nodes and so on.
This is where Jepsen comes in. From the Jepsen website:
Jepsen is an effort to improve the safety of distributed databases, queues, consensus systems, etc.
The Jepsen suite runs a number of test cases against a database while simultaneously subjecting them to a number of nemesis failures (failure scenarios such as those mentioned above). The Jepsen suite then verifies that the database actually holds true to its marketing claims by comparing what was observed by the test suite with what is expected in theory.
It is important to note that while many database vendors will claim to have run and passed Jepsen tests on their own, the Jepsen test framework is only as good as the test suites designed to run on top. Therefore it is important to dive a bit deeper and understand exactly what the tests do and which guarantees of the database have been verified. Currently, the Jepsen suite for YugabyteDB already has coverage for most of the standard tests, and we are working on adding even more tests.
As we mentioned before, Jepsen verifies that a database truly lives up to what it promises to do, so that users can have a strong and verifiable basis upon which they build their applications. This naturally leads to the question of what a database promises.
What does YugabyteDB promise?
The task of enumerating what a database promises can be surprisingly hard, especially given that distributed databases are complex. But fortunately, there are some models that make this possible. Let us look at a few of these in the context of YugabyteDB.
CAP Theorem
In terms of the CAP theorem, YugabyteDB is a consistent and partition-tolerant (CP) database, while ensuring high availability (HA) for most practical situations. Thus, the Jepsen test suite needs to verify strong consistency of data in the presence of partitions and failures. That brings us to the next question – what does strong consistency mean in YugabyteDB?
ACID Transactions
YugabyteDB’s replication protocol is strongly consistent, and this is essential for being an ACID compliant distributed database in the face of failures (such as node death). ACID stands for the following:
- Atomicity – All the work in a transaction must be treated as one atomic unit — either all of it is performed or none of it is.
- Consistency – The database must always be in a consistent internal state after updates. For example, failed writes or partial writes must not be stored in the database.
- Isolation – Determines how and when changes made by a transaction become visible to the others. YugabyteDB currently supports Snapshot Isolation, which detects write-write conflicts.
- Durability – Successful writes must be permanently stored in the database.
Our Jepsen test suite verifies each of the above properties of the database while subjecting it to various failure scenarios.
Failure Testing
The Jepsen framework subjects the tests to a number of failure scenarios, rightfully called nemesis failures. Below are some of the failures that YugabyteDB is routinely run against.
- Single Fault failures kill and restart a randomly chosen database process that is a part of the cluster.
- Random Partition failures introduce network partitions into the cluster that isolates a randomly chosen node from the rest of the nodes in the cluster.
- Majorities Ring Partition failures partition the network such that every node can see a majority of nodes in the cluster, but no node sees the same majority as the others.
- Clock Skew failures cover a range of issues related to the clock synchronization across different machines. There are a number of different clock skews introduced – small (~ 100ms), medium (~ 250ms), large (~ 500ms) and xlarge (~ 1 secs).
We also get asked about how YugabyteDB works in the face of network failures such as:
- Flaky network where some packets get dropped
- Slow network
- Duplication of some network packets
YugabyteDB uses the TCP protocol for inter-process communication. Since TCP guarantees that all bytes received will be identical with bytes sent and in the correct order, these issues just manifest themselves as a higher stream latency to YugabyteDB. Hence, there was no need to introduce network failures in Jepsen when testing YugabyteDB.
YugabyteDB Jepsen Test Suite
The Jepsen tests for YugabyteDB are designed to verify atomicity, consistency, isolation and durability in the face of a various failure scenarios. Since we induce various failures while performing operations against the database, it is natural to expect that some individual operations may fail, but correctness should not be compromised. The expectation on the operations across all of the tests is that they return one of the following based on the result of the operation:
- OK: The operation was successful. For example, a successful update must be persisted in the DB and comply with ACID.
- FAIL: The operation failed. For example, a failed update must not be stored in the DB and behaves the same as the update never having occurred.
- UNKNOWN: The result of the operation is unknown. For example, in the case of an update, there could be a timeout (possibly because of a network partition). The update could either have been applied, or not been applied.
Each test logs every operation it performs along with the result of the operation. At the end of the test, a checker validates that the results are consistent with the sequence of the operations.
The unique key-value inserts test creates a table with one primary key column and one value column. It inserts unique key-values pairs into the table, and verifies durability (by checking if successfully written values can be read back) and consistency (by ensuring failed writes are not present in the database).
The single-key ACID transactions test performs concurrent read, write and read-modify-write (compare and set) operations on a single row in a table. It checks the consistency of the database and the atomicity of these operations by introducing various failures. The distributed ACID transactions test creates a key-value table spanning multiple nodes and performs concurrent multi-row transactions, each of which updates two different keys with the same value. At the end of these tests, a checker validates that the result of the sequence of operations recorded, which is the client observed view of the data, is ACID compliant.
Test Results
A Jepsen test (which is a Clojure program running on a control node) logs into a set of nodes to setup a YugabyteDB cluster and test it. Each VM instance should be accessible from the control node via SSH, and the SSH account must have sudo access. In our case, we ran the Jepsen test on a YugabyteDB cluster that ran on 5 separate VM instances. The test performs various operations in parallel using a set of processes, and records the start and end of each operation in a history. While performing operations, a special nemesis process introduces faults into the system. Finally, Jepsen uses a checker to analyze the test’s history for correctness, and to generate reports, graphs, etc.
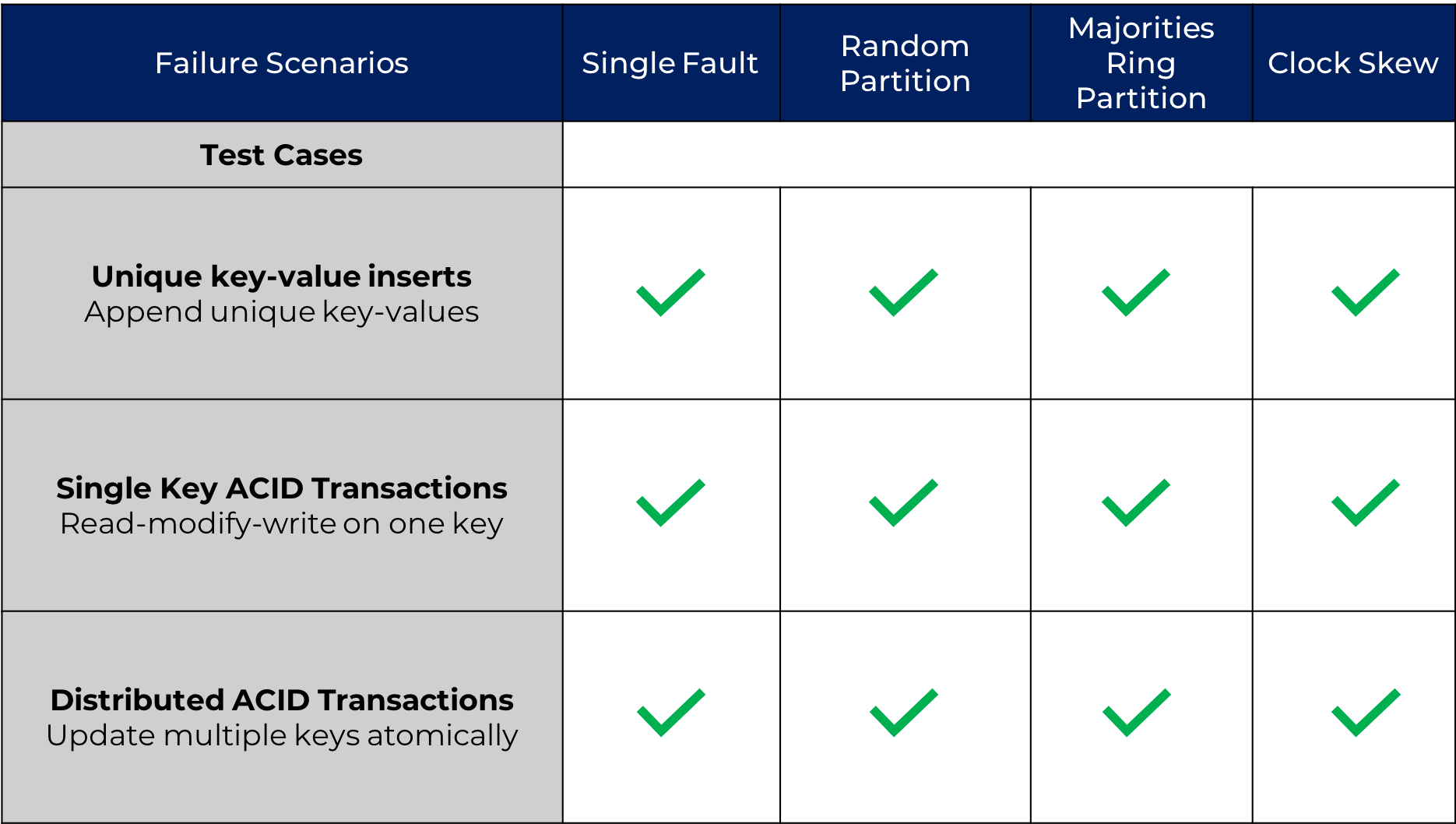
Note:we did not use containers for our Jepsen test. The system clock on containers cannot be changed, which means that tests relying on clock skew would not work. We ran the tests repeatedly in a loop in the presence of the various nemesis failures and were able verify that all they succeeded without any correctness issues. Visually, here is our Jepsen testing status in terms of the test cases and failure scenarios.
Issues found and fixed while testing
When running these intense Jepsen tests, we were able to uncover some interesting issues.
The first issue we uncovered using Jepsen was when reading multiple keys updated as a part of a single transaction, which were sometimes inconsistent. This caused the Jepsen checker in the distributed ACID transactions test to fail. It turned out that when reading keys from different tablets, there was a bug which were each tablet made an independent decision on the read point (timestamp) instead of picking a common read point for a read request.
Another particularly hard to debug issue manifested itself as a linearizability inconsistency. Here is a simplified version of the test:
- Phase 1: update a key value pair repeatedly (while introducing network partitions)
- Phase 2: repeatedly read the value for the key
The value would sometimes mysteriously get updated when reading it as a part of Phase 2, when it clearly should not. Upon investigating more (a lot more in fact), we found that the client driver was retrying failed operations – which is incorrect for non-idempotent operations like increments, and could violate linearizability even if the operations are idempotent.
It turns out there was a mismatch between the Cassandra driver documentation (which said, failed operations would not be retried) and the open-source implementation of the Cassandra driver (which was performing retries for failed operations). In order to allow preserving linearizability for applications that need it, we have now added a policy to not retry operations that failed due to timeouts, as well as filed this Cassandra issue.
What’s Next?
Below are some of the subsequent steps in our Jepsen testing journey:
- Add Jepsen testing to our nightly CI/CD pipeline.
- Add more test scenarios, such as the bank transfer test.
- Engage with Kyle for formal Jepsen testing.
You may also be interested in the following:


