Introducing YugabyteDB 2.7: The Most Comprehensive Coverage of Kubernetes Environments for Microservices
May 5, 2021
YugabyteDB is the distributed SQL database of choice for building mission-critical microservices that deliver new customer experiences, improve operations, and drive innovation. We aim to make your experience of deploying and running YugabyteDB on any infrastructure seamless, be it Kubernetes, VMs, or bare metal across private, public, and hybrid cloud environments.
With our latest release, YugabyteDB 2.7, we have added updates to give developers the scalability and resilience they need from systems of record for their microservices. The release also includes capabilities that empower operations teams to deploy and run YugabyteDB across regions and clouds in enterprise Kubernetes environments for resilience.
Let us start with a quick rundown of what’s new in this release before going into the details.
With YugabyteDB 2.7, application developers can:
- Get fine-grained control over how tables are distributed and replicated across zones, regions, and clouds using YSQL tablespaces that extend PostgreSQL tablespaces to a cloud native distributed SQL deployment.
- Rollback unintended changes and restore YugabyteDB databases to a specific point in time in the past with minimal impact to the cluster using point in time recovery (PITR).
- Write messages from Kafka Topics to YugabyteDB for IoT, streaming applications, and change data capture (CDC) use cases using the YugabyteDB Sink Connector for Apache Kafka with benchmarked performance of 110,000 messages per second ingestion rate.
- Enable encryption in transit using TLS to get confidence that your communication is secure while maintaining lightning fast responses between nodes and applications. Benchmarks demonstrate minimal database performance impact (<5%) from turning on encryption in transit.
- Use new multi-node deployment and management capabilities in the powerful open source command line tool — yugabyted — to explore what YugabyteDB offers.
YugabyteDB 2.7 enables DevOps teams to:
- Deploy Yugabyte universes in Red Hat OpenShift Kubernetes environments using Yugabyte Platform from the Red Hat Marketplace.
- Confidently run stateful microservices using the first distributed SQL database solution to be validated to run on all three of the following: VMware Tanzu Kubernetes Grid (TKG), VMware Tanzu Kubernetes Grid Integrated Edition, and VMware vSphere with Tanzu. Yugabyte Platform is available in the Tanzu Solutions Hub.
- Use YugabyteDB with CAST AI to deploy and manage applications and database clusters in Kubernetes environments across multiple clouds. You can run multi-cloud multi-zone deployments at the same level of performance as a single-cloud multi-zone deployment.
- Deploy and use the Yugabyte Platform console in HA mode for mission-critical environments while meeting service level agreements and business continuity requirements.
Achieve Fine-Grained Control Over Geographic Data Placement Using Tablespaces
YugabyteDB extends the concept of PostgreSQL tablespaces for a distributed database behind microservices. PostgreSQL tablespaces allow administrators to specify where on a disk specific tables and indexes should reside based on how users want to store and access the data. Control over data placement enables fine-grained performance tuning, for example, by placing heavily accessed smaller tables and indexes in SSD.
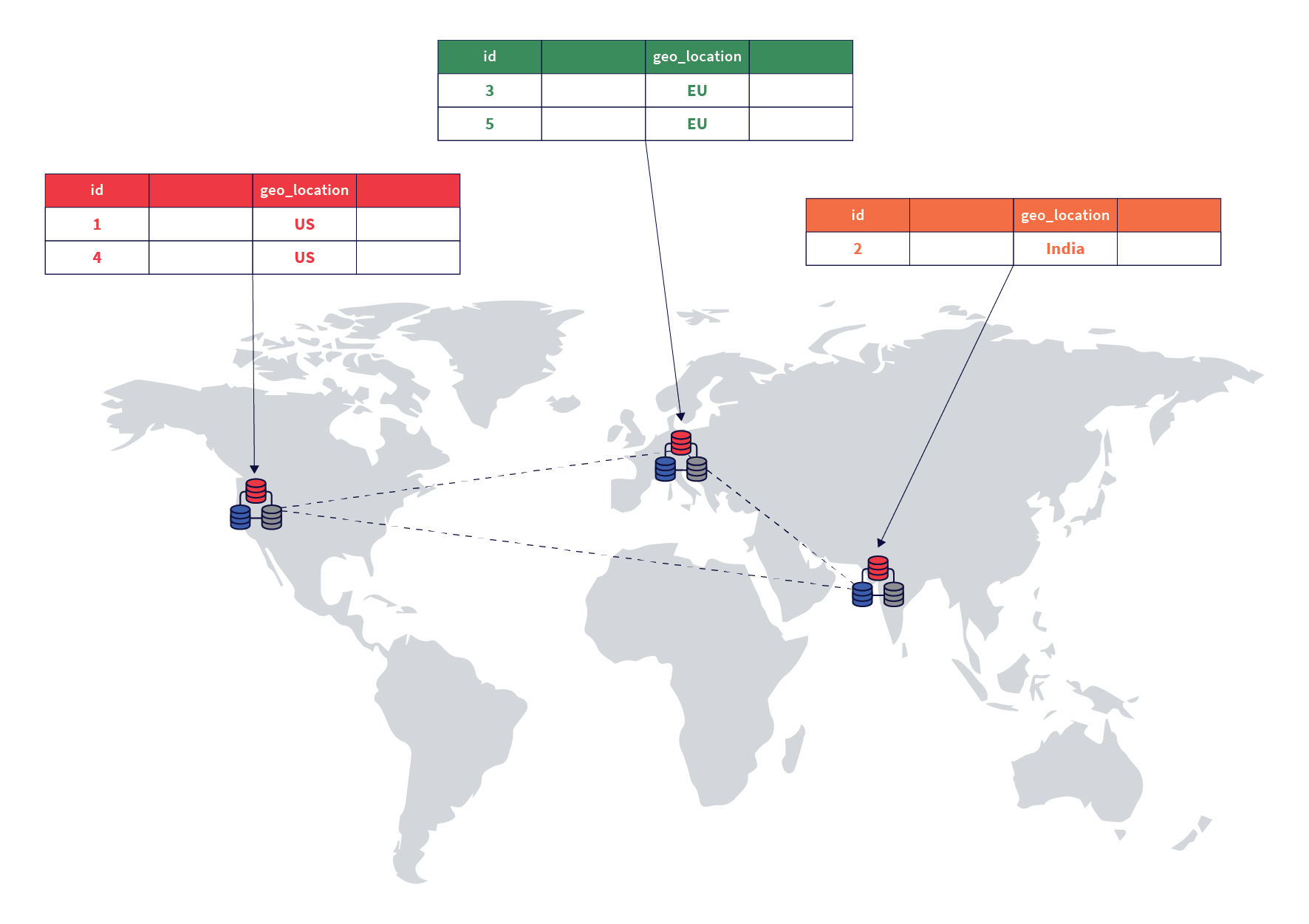
Figure 1: Admins and developers can use YSQL Tablespaces in conjunction with table partitions and/or duplicate indexes to pin data to specific regions to enhance user experience and compliance
YSQL Tablespaces repurpose this concept for a geo-distributed deployment by allowing developers to specify the number of replicas for a table or index, and how they can be distributed across a set of cloud/region/zones. Replicating and pinning tables in specific regions can lower read latency, improve resilience, and achieve compliance with data residency laws. For example, developers and admins can create duplicate indexes on the same column of a table and place these indexes close to users in different regions for fast access. Similarly, admins can partition a master table and associate the partitions with different tablespaces to pin the data geographically.
Recover YugabyteDB to Any Point in Time
YugabyteDB now offers point in time recovery (PITR), allowing a database to be restored to a specific point in time in the past. This time can be relative, such as “three hours ago”, or an absolute timestamp. PITR is a core database feature for business continuity and disaster recovery (BC/DR), offering protection against data corruption, app or operator errors, disaster scenarios, and other unintended database changes or losses. PITR enables granular data protection with a low recovery point objective (RPO) and minimal impact on the cluster.
Build Scalable Microservices with YugabyteDB Sink Connector for Apache Kafka
Back in January 2020, we announced the YugabyteDB Sink Connector for Apache Kafka, which delivers data in a specific Kafka topic to a YugabyteDB instance. This is a critical integration for developers building IoT and streaming applications. It is also useful for CDC use cases in a microservices architecture where changes in the YugabyteDB instance of one microservice is consumed and stored in the YugabyteDB instance of another microservice.
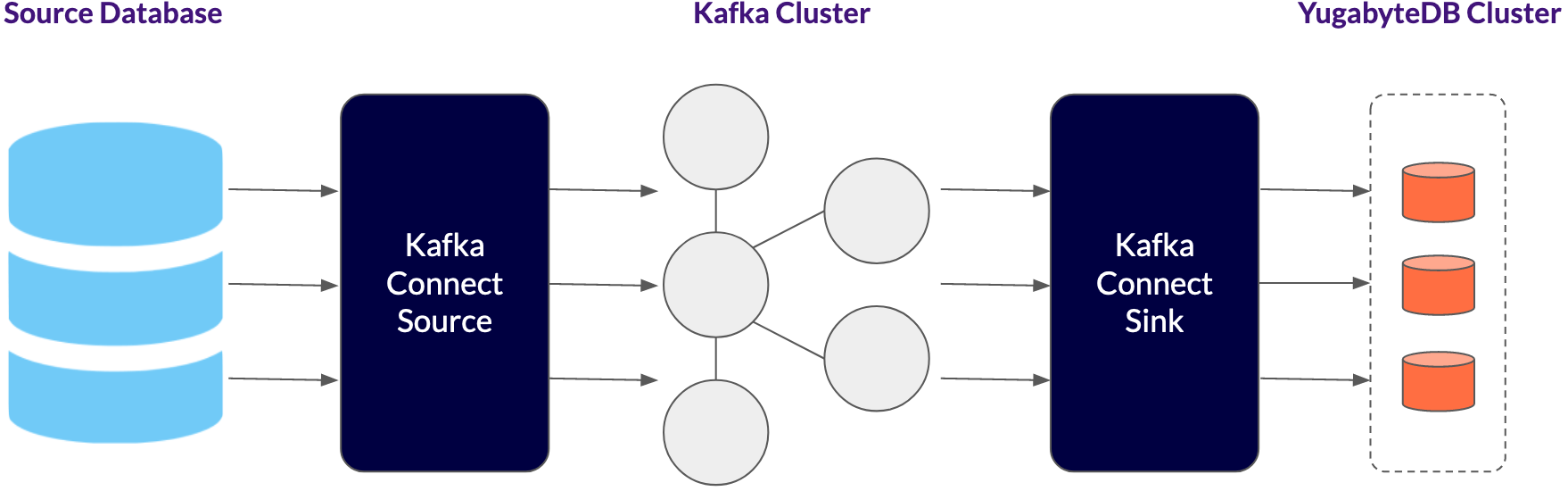
Figure 2: The YugabyteDB Sink Connector for Apache Kafka provides a resilient, scalable way to transfer data from a Kafka topic to a YugabyteDB cluster
In addition to resilience, the YugabyteDB Sink Connector for Apache Kafka needs to have high throughput that scales linearly. A key advantage of using YugabyteDB Sink is that multiple Kafka Connect workers can connect to different YB-TServer processes. This balances load among multiple nodes for higher throughput, and improves resilience and availability in case a node goes down. To measure the performance of the integration, the YugabyteDB engineering team ran benchmarks on a three node RF3 YugabyteDB cluster. By scaling the number of worker nodes, we were able to achieve an ingestion rate of 110,000 messages per second (each message was about 60 bytes). In a follow-up blog, we will go over the details of the integration and the benchmark tests.
Encrypt Data in Transit Between Apps and Nodes With No Performance Impact
YugabyteDB supports TLS/SSL (Transport Layer Security/Secure Sockets Layer) to encrypt all network traffic between clients and server nodes as well as server to server communication for distributed query processing and data replication between nodes of a cluster. When TLS encryption is enabled, one of the major concerns application developers have is how it will affect either of those two paths — client-to-server and server-to-server — and introduce latencies. So we decided to test the performance impact by running TPC-C benchmarks. We found that enabling TLS does not have a large impact on the overall performance. Here’s a summary:
- Throughput drops by < 5%, which is marginal.
- Average latency increases by 15%. However, note that there can be up to a 10% variance between any two runs in the cloud.
- CPU increases by roughly 6% when enabling TLS, again within the margin of error in the cloud.
In effect, there is no significant impact to performance with TLS enabled unless you have a very high connection count where latency can increase a bit. Interested to learn more? Read the detailed blog on the TPC-C testing and analysis with TLS by senior data engineer Taylor Mull.
Confidently Deploy YugabyteDB in Kubernetes Environments of Your Choice
YugabyteDB is ideal for mission-critical Kubernetes environments, whether you are using Kubernetes platforms like Red Hat OpenShift or VMware Tanzu, cloud services like Amazon EKS, Google Kubernetes Engine (GKE), Azure Kubernetes Services (AKS), or other OSS compliant Kubernetes platforms. For organizations that want to use YugabyteDB in enterprise cloud native environments at scale, the Yugabyte Platform offering delivers a streamlined operational experience. Yugabyte Platform enables you to efficiently deploy and manage a private DBaaS in any Kubernetes environment with intelligent infrastructure operations and automated day 2 operations of the database, delivering resilience and high availability.
We announced last year that YugabyteDB is certified for Tanzu Kubernetes environments and is available in the Tanzu Marketplace. Since then we have further simplified how customers deploy YugabyteDB in their Tanzu environments using Yugabyte Platform. YugabyteDB is the first distributed SQL database offering to be validated to run on all three of the following: VMware Tanzu Kubernetes Grid (TKG), VMware Tanzu Kubernetes Grid Integrated Edition, and VMware vSphere with Tanzu. The Partner Ready for VMware Tanzu validations provide customers with peace of mind, knowing that they can confidently run their YugabyteDB workloads on VMware Tanzu.
Yugabyte Platform is available on the VMware Tanzu Solutions Hub. You can deploy and run your microservices and database clusters on VMware Tanzu across any cloud without lock-in. To deploy a Yugabyte cluster in VMware Tanzu environments, follow these few simple steps:
- Install Yugabyte Platform software in Kubernetes using a Helm chart.
- In the Yugabyte Platform UI, select the VMware Tanzu provider and configure it.
- Once the provider has been configured, you can start provisioning Yugabyte Universes in various configurations (including single zone, multi-zone, and multi-cluster/multi-cloud). Provision Yugabyte Universes in VMware Tanzu.
We also announced in June last year that the YugabyteDB operator was certified on Red Hat OpenShift. We have now further simplified how customers can deploy YugabyteDB in Red Hat OpenShift environments using the Yugabyte Platform console. Yugabyte Platform is now certified on Red Hat OpenShift and available on the Red Hat Marketplace, enabling enterprise customers to discover, try, purchase, deploy, and manage certified container-based software across environments—public and private, cloud and on-premise.
Deploy YugabyteDB in Multi-Cloud Kubernetes Clusters with No Performance Compromise
You can deploy YugabyteDB clusters in any cloud or data center anywhere, on VMs and containers. This flexibility frees organizations from lock-in, allowing them to pick infrastructure that aligns with their business and application needs. However, for some topologies such as deploying a single YugabyteDB cluster across multiple Kubernetes clusters, infrastructure configuration can get complex.
CAST AI and YugabyteDB radically simplify how you deploy, scale, and manage your applications and database clusters on Kubernetes in any configuration you choose. Whether you want to deploy a single database cluster across different availability zones in the same region of a cloud for resilience or across different regions in different clouds for extra availability, CAST AI allows you to do either with equal ease. Infrastructure automation and abstraction allow you to stop worrying about VMs, networks, storage, firewalls, and load balancers.
What is the performance impact of running YugabyteDB clusters across multiple clouds? To measure this, the CAST AI team ran TPC-C benchmarks two different scenarios:
1. Single cloud: Regional GKE k8s cluster with 9x GCE N2d-standard-8 distributed in 3 Availability Zones. VPC network in Google’s US-East-4 region
2. Dual-cloud: AWS EC2 3x c5a.2xlarge, GCP GCE 6x n2d-standard-8. A network between cloud providers setup with a Wireguard based full mesh VPN that encrypts traffic end-to-end (also inside the same VPC).
Tests showed the performance impact of running YugabyteDB clusters across different clouds to be minimal – 3,774 transactions per minute (tpmC) with dual cloud vs 3,769 transactions per minute in the single cloud configuration. Interested to learn more? CAST AI has a tutorial that takes you through every step of building the above solution in about 10 minutes from scratch.
Run the Yugabyte Platform Console with High Availability
Yugabyte Platform includes a powerful graphical user interface for managing fleets of database clusters deployed across zones, regions, and clouds from one place. Our enterprise customers rely on the Yugabyte Platform console to deliver YugabyteDB as a private DBaaS through streamlined operations and consolidated monitoring.
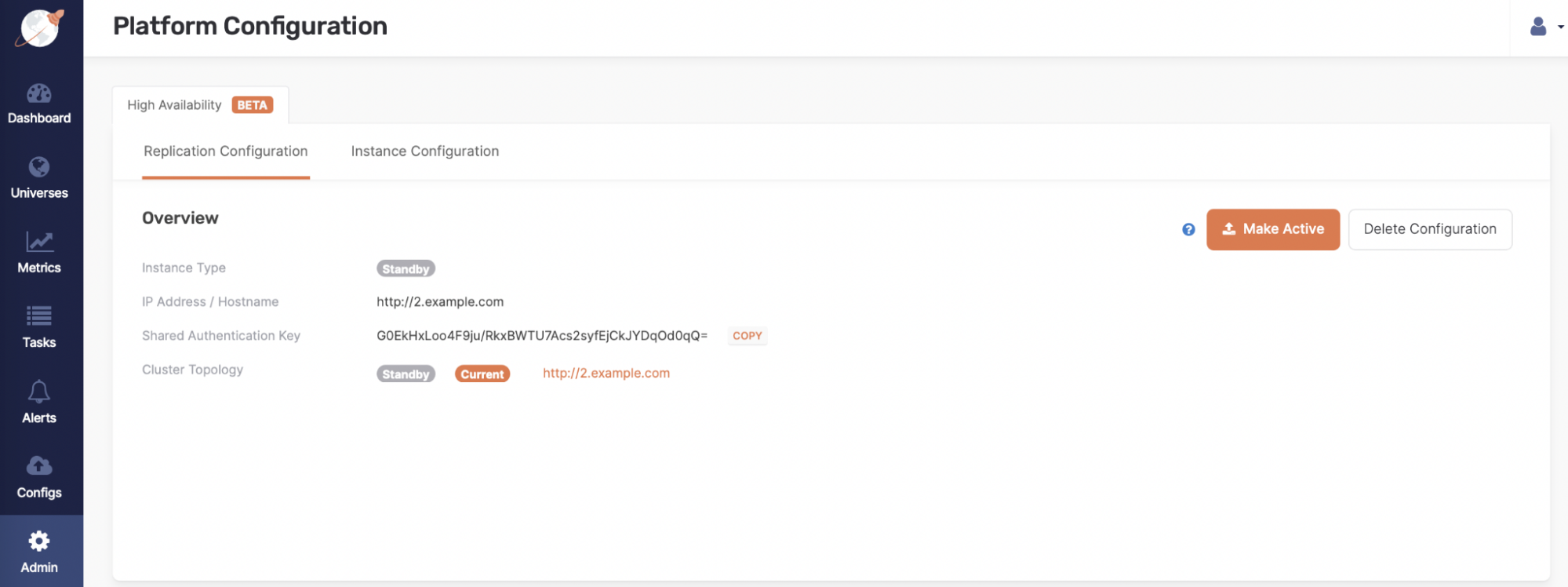
Figure 3: The Yugabyte Platform console can now be deployed in HA mode
Recognizing the critical role that Yugabyte Platform plays in simplifying infrastructure and database operations, YugabyteDB now offers a high availability mode for the Yugabyte Platform console, ensuring that the console is available in the event of zone or region failures. In HA mode, the Yugabyte Platform console consists of a primary/active console which automatically replicates state data asynchronously to one or more standby consoles in other zones or regions. In the event that the primary console goes down, admins can easily switch to a secondary console. It’s important to note that the Yugabyte Platform console is not in the critical path of database access. YugabyteDB clusters have been designed for resilience and high availability, ensuring 24×7 access to data.
The Yugabyte Platform installer simplifies the deployment of the Yugabyte Platform console in HA mode.
Manage Multi-Node Clusters with yugabyted
YugabyteDB 2.7 greatly expands the capabilities of the open source cluster management CLI tool, yugabyted, allowing admins to deploy a database cluster with multiple nodes across several host machines in seconds. yugabyted now simplifies cluster-related tasks such as adding and removing hosts/nodes and restarting clusters.
To understand why this is important, let us look at what a YugabyteDB cluster looks like. A YugabyteDB cluster consists of two sets of servers, YB-TServer and YB-Master. YB-TServer, or the YugabyteDB Tablet Server, hosts and serves user data, and deals with all the user queries. YB-Master holds system metadata, coordinates system-wide operations, and initiates maintenance operations such as load balancing. These two sets of servers each form distributed services.
Decoupling the metadata service from the transaction service allows each to be configured and tuned independently to achieve better performance and resilience than if they were together in a single service. But these benefits come with a tradeoff – they make it more challenging to deploy a YugabyteDB cluster quickly across multiple servers because you now have to deploy two sets of services. yugabyted tames the complexity of starting multiple services across hosts with a simple daemon that allows admins to specify the desired topology and configuration as parameters.
Coming Up: Product Roadmap
At Yugabyte, we strive to be fully transparent and to that end we publish our roadmap on GitHub. The following are some notable callouts of features you can expect in upcoming releases. Note that the current roadmap is subject to change, as we finalize our planning for next releases.
A number of core database and Yugabyte Platform features are on the roadmap, here a few key features that are being worked on for the upcoming releases:
- Support for GIN indexes
- Enhanced support for pessimistic locking
- Enhanced support for online schema migrations including support for popular migration frameworks such as Liquibase, Flyway, and other ORM migration frameworks.
- Support for Internationalization and Collation in YSQL
- YSQL Smart JDBC Driver that is cluster and topology aware and can automatically route queries to the appropriate node(s), perform load balancing, and discover newly added or removed nodes
- A variety of new enterprise features and enhancements are coming to Yugabyte Platform including:
- Improved Health Checks and Alerting framework
- YB Platform API SDK to enable automation of Day 2 operations of the database( ex. Cluster Scale Up/Down) using your favorite CI/CD tools
What’s Next
We’re very happy to be able to release all of these enterprise-grade features in the newest version of our flagship product – YugabyteDB 2.7. We invite you to learn more and try it out:
- Install YugabyteDB 2.7 in just a few minutes
- Register for the “What’s New in YugabyteDB 2.7” webinar on May 26 at 9am PT with Amey Banarse, VP of Product, and Suda Srinivasan, VP of Strategy and Solutions
- Join us in Slack for interactions with broader YugabyteDB community and real-time discussions with our engineering teams


