Implementing Distributed Transactions the Google Way: Percolator vs. Spanner
July 23, 2018
Our post 6 Signs You Might be Misunderstanding ACID Transactions in Distributed Databases describes the key challenges involved in building high performance distributed transactions. Multiple open source ACID-compliant distributed databases have started building such transactions by taking inspiration from research papers published by Google. In this post, we dive deeper into Percolator and Spanner, the two Google systems behind those papers, as well as the open source databases they have inspired.

Google Percolator
Percolator is Google’s internal-only system used to make incremental updates to the Google search index. Google published its architecture (shown below) as a research paper in 2010. Percolator achieved a 50% reduction in the delay between page crawling (the first time Google finds a page) and page availability in the search index, in comparison to the MapReduce-based batch processing system it replaced.
Basic Architecture
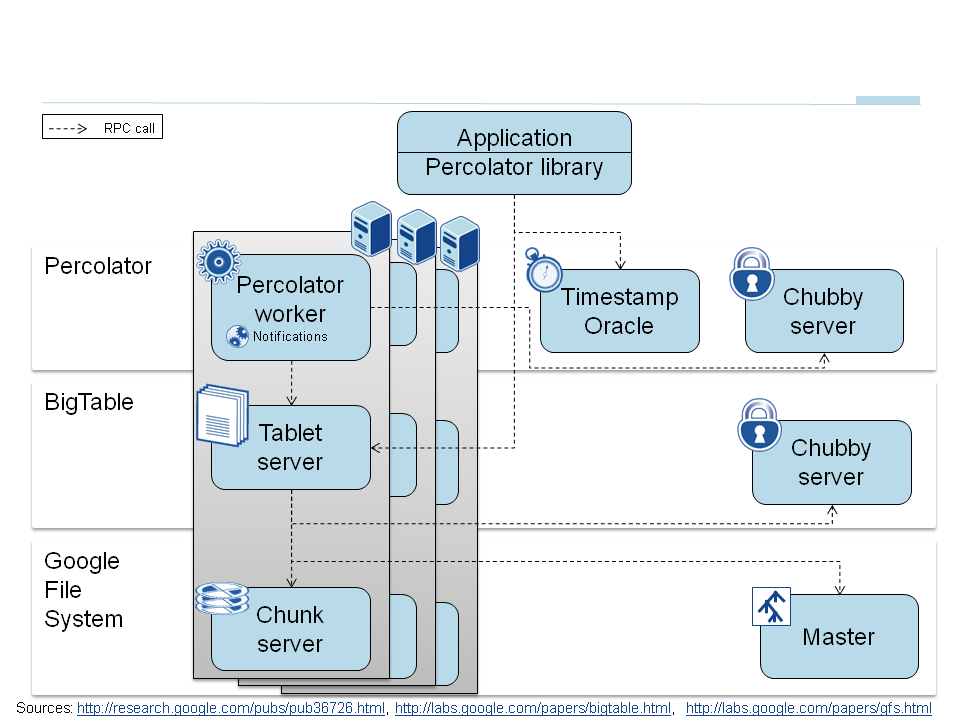
Percolator is designed on top of BigTable, Google’s original wide-column NoSQL store first introduced to the world in 2006. It adds cross-shard ACID transactions using a two-phase commit protocol on top of BigTable’s single row atomicity. This enhancement was necessary because the process of updating an index is now divided into multiple concurrent transactions, each of which has to preserve invariants such as the highest PageRank URL has to be always present in the index and link inversion to anchor text should work across duplicates.
Isolation Levels & Time Tracking
Percolator provides Snapshot Isolation, implemented using MVCC and a monotonically increasing timestamp allocated by a Timestamp Oracle. Every transaction requires contacting this Oracle twice, thus making the scalability and availability of this component a significant concern.
Practical Implications
As highlighted in the Percolator paper itself (see below), it’s design is not suitable for an OLTP database where user-facing transactions have to be processed with low latency.
The design of Percolator was influenced by the requirement to run at massive scales and the lack of a requirement for extremely low latency. Relaxed latency requirements let us take, for example, a lazy approach to cleaning up locks left behind by transactions running on failed machines. This lazy, simple-to-implement approach potentially delays transaction commit by tens of seconds. This delay would not be acceptable in a DBMS running OLTP tasks, but it is tolerable in an incremental processing system building an index of the web. Percolator has no central location for transaction management; in particular, it lacks a global deadlock detector. This increases the latency of conflicting transactions but allows the system to scale to thousands of machines.
Open Source Databases Inspired By Percolator
TiDB / TiKV

TiDB, a MySQL-compatible distributed database, uses Percolator as the inspiration for its distributed transaction design. This choice makes sense given TiDB’s focus on throughput-oriented Hybrid Transactional/Analytical Processing (HTAP) use cases that are not latency sensitive and usually run in a single datacenter. TiKV is the underlying distributed key-value layer.
Google Spanner
Percolator’s primary limitation is the lack of multi-region distributed transactions with low latency. Such transactions are absolutely necessary to power geo-distributed OLTP workloads (think Gmail, Calendar, AdWords, Google Play and more). Google’s answer to this problem is another internal project called Spanner, first introduced to the world in 2012. Spanner started out in 2007 as a transactional NoSQL store with a key-value API and support for cross-shard transactions, external consistency, and transparent failover across datacenters. Since then it has evolved into a globally distributed SQL-based RDBMS that today underpins almost every mission-critical service at Google. A subset of the Spanner system was made publicly available in 2017 on the Google Cloud Platform as a proprietary managed service called Google Cloud Spanner.
Storage & Replication Architecture
Unlike Percolator, Spanner’s architecture is not based on BigTable. It resembles Megastore more closely and uses Colossus as its file system. A Spanner deployment is called a “universe”. A universe auto shards and auto rebalances data across many sets of Paxos state machines located in multiple zones at datacenters spread all over the world. These shards are also replicated for global availability and geographic locality; clients automatically failover between replicas.

A zone has one zonemaster and possibly 1000s of spanservers. The former assigns data to spanservers; the latter serve data to clients.
ACID Transactions with TrueTime
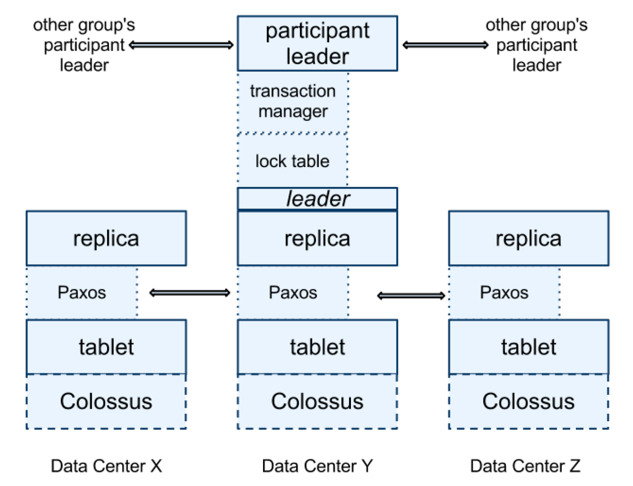
Distributed Transactions in Google Spanner (Source: Spanner Paper)
At every replica that is a leader, each spanserver implements a lock table to support two-phase-locking based concurrency control and a transaction manager to support distributed transactions. If a transaction involves only one Paxos group (as is the case in single row & single shard transactions), it bypasses the transaction manager. The lock table and Paxos together are enough to do the job here. If a transaction involves more than one Paxos group (as is the case in distributed transactions), those groups’ leaders coordinate to perform two-phase commit. The state of the transaction manager is also modeled as a persistent Paxos group to ensure continued availability.
The most noteworthy innovation in Spanner is that it achieves external consistency, an isolation level even stricter than serializability, by assigning global commit timestamps to all transactions using the TrueTime API. TrueTime is Google’s highly reliable “wall-clock” time tracking service (with a bounded uncertainty of 7ms) that is built on GPS and atomic clocks. It is the first system to provide such a guarantee at global scale.
Practical Implications
Some authors have claimed that general two-phase commit is too expensive to support, because of the performance or availability problems that it brings. We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions. Running two-phase commit over Paxos mitigates the availability problems.
As highlighted in the Spanner paper itself (see above), Spanner has a strong point-of-view regarding the performance and availability concerns associated with distributed transactions. These concerns were commonly cited as rationale by NoSQL databases of the time such as Google’s own BigTable and Yahoo’s PNUTS for their own non-transactional designs.
Hybrid Logical Clocks as a TrueTime Alternative
Any non-Google database that wants to have Spanner-like transactions has to live with the fact that TrueTime is proprietary to Google and hence is not available in the commodity infrastructure world of public cloud IaaS or private datacenters. The next best alternative for tracking time is Hybrid Logical Clocks (HLC), first published as an academic research paper in 2014. HLC’s timestamp is a combination of physical time and logical time where physical time is usually based on Network Time Protocol (NTP) and logical time is based on Lamport’s logical clock algorithm.
Open Source Databases Inspired By Spanner
Two Spanner-inspired open source databases that use HLC as the timestamp mechanism are highlighted below.
YugabyteDB

YugabyteDB is a PostgreSQL-compatible distributed SQL database with sharding, replication and transactions architecture similar to that of Spanner. Yes We Can! Distributed ACID Transactions with High Performance details its inner workings especially around the various optimizations made to achieve low latency and high throughput.
CockroachDB

CockroachDB, a PostgreSQL-compatible distributed database, supports global ACID transactions similar to Spanner.
Summary
Google Percolator’s high throughput but latency-intensive approach can work only for single datacenter HTAP apps. However, Google Spanner’s approach of decentralized time tracking is a great solution for both geo-distributed OLTP and single datacenter HTAP apps. Given the unavailability of Spanner’s TrueTime in the traditional enterprise world, open source databases are aiming to provide Spanner-like benefits using HLC. We will review the performance characteristics of such databases in a future post.


