How to Handle Runaway Queries in a Distributed SQL Database
May 28, 2019
Runaway queries are queries that scan through a large set of data. Such queries consume vast amounts of I/O and CPU resources of the database in the background, even if the results appear as harmless timeouts to the end user or the client application. How do runaway queries get executed in the first place, anyway? Everyone who uses databases has at some point or another entered SELECT * from some_large_table, only to realize they forgot to add a LIMIT n clause. You remedy the situation by quickly hitting “ctrl-c “or wait for the DB to timeout before running the command again, but this time with the LIMIT clause. But has some unseen damage already been done to the database, which is now impacting other clients? In this post we’ll explore how runaway queries are handled in a distributed SQL database like YugabyteDB. We also highlight how YugabyteDB minimizes their side effects on the cluster as a whole.
The Problem: Increased Latency & Reduced Throughput
Some time ago, I was investigating a YugabyteDB cluster that had quite a few ~5 minute periods where there was increased latency and reduced throughput across all queries. I first looked for any cluster-wide events happening such as a network partition or a node failure that could explain the sudden drop in performance, but found none. Upon further investigation, I noticed that around the time the cluster was experiencing performance slowdown, the logs indicated that a SELECT * command without a LIMIT clause was executing.
Using the default command line shell, I ran the same SELECT * command against the cluster and it timed out in 10 seconds. This is good! However, I noticed that the cluster’s throughput (measured by operations/sec) dropped for about 5 minutes afterwards. This is bad! So, ran the same command again, checked the iostat metrics for each node, and saw that only one node had high disk utilization and CPU usage. Upon checking codeiostat metrics again about 5 minutes later, a completely different node experienced a spike in CPU and disk usage. What was going on?
Before explaining how I got to the bottom of this runaway query mystery and the solution we implemented, let’s review the lifecycle of a distributed SQL query, from start to finish.
The Lifecycle of a Distributed SQL Query
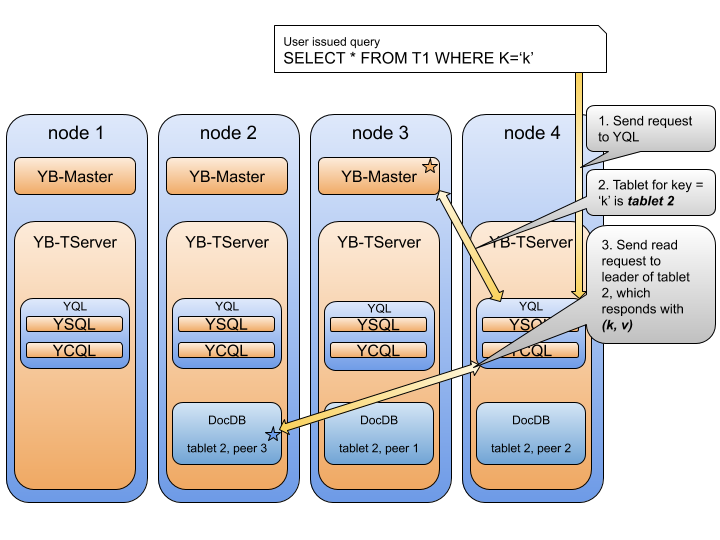
Regardless of the client API, every query follows roughly the same flow inside YugabyteDB.
- The client sends the request to the YugaByte Query Layer (YQL)
- The node hosting the tablet (aka shard) with the appropriate key is identified
- The read request is forwarded to the leader with the tablet
The leader responds to the client with the requested data - Now, let’s breakdown of the various components that a query interacts with and the role they play in the lifecycle of a query.
Client
The client is started with a list of servers, and depending on the client policy, the request is sent to the YugaByte Query Layer (YQL) of one of these servers.
Keys and Partitioning
Primary keys are compound keys consisting of a required partition key and a list of optional range keys. The partition key is hashed into a 16 byte range from [0, 0xFFFF] and sharded into a specific bucket, or tablet, based on the hash value. As an example, if keys are divided into 16 tablets, the first tablet would contain keys with the hash [0, 0x1000), the next tablet from [0x1000, 0x2000), and so on. Each tablet has a replication factor, and each copy of the tablet data is referred to as a tablet peer. These peers together form a Raft quorum in DocDB, YugabyteDB’s underlying distributed document store.
DocDB’s Raft-based Replication
Raft is a consensus protocol used by a variety of distributed systems. In DocDB, Raft is applied at a tablet level. Each tablet’s Raft quorum has a notion of one “leader” node and the rest designated as “followers” responsible for persisting each write in a strongly consistent manner. Strong consistency basically means that committed writes are seen by all future reads. All writes to a tablet go through the Raft leader, who then sends an update request to all the followers in the quorum. A write is considered committed when it has been acknowledged by a majority of peers in the quorum. Since the leader always owns the latest state of the data, the Raft leader can respond to reads without consulting the other peers.
YugaByte Query Layer (YQL)
Once the client communicates with the YQL, it is YQL’s responsibility to forward queries to the tablet leader for a given key. In the case of a SELECT *, the YQL sends requests to all the tablets. To figure out the tablet leader, the YQL has a cached mapping of a hash range to tablet. So, once the key is hashed and the tablet leader is computed, the YQL sends a request to the appropriate tablet server. Each of these requests has a deadline, after which the YQL either retries or aborts the request on its end.
DocDB’s Document Storage Layer
When the query reaches the tablet server holding the tablet in question, it is propagated down to DocDB’s document storage layer that’s built on a custom version of RocksDB. Entries in this storage layer are sorted by primary key. When the query hits this layer, the relevant documents are loaded into memory for scanning, where an iterator filters through the data and builds a response to send back to the YQL.
Back to YQL
Once the data gets back the YQL, one of two things are done. If the query is a single key request, the response is forwarded back to the client. If the query involves multiple tablets, the YQL waits for all the tablets to respond and sends back an aggregated response.
A Runaway Query Example
Now, let’s imagine we had all the historical prices of all the stocks ever listed on the New York Stock Exchange inside a YugabyteDB cluster. If we were to execute a query that returned all the historical prices of all stocks in the NYSE for the past year, this request would run for a long time on all tablet servers before completing. So, while the client would time out after 10 seconds, there was no deadline being propagated to tablet servers. This resulted in the tablet servers wastefully utilizing disk and CPU to build a response for a query that had already timed out. Now, what happens when a new clients issue queries that access data on that tablet server chugging away on the runaway query? Those requests are going to experience increased latencies and reduced throughput because the runaway query is monopolizing all the resources until it completes.
The Solution: Propagating Timeouts to DocDB

Before timeout improvement, CPU Usage of tablet server handling large scan.
To fix this problem, we propagated the YQL timeout to the DocDB through a Remote Procedure Call (RPC), where it is converted to a deadline. From there, it is passed down to the iterator, which builds the response using repeated calls to a Seek API in order to retrieve each next value in the document. At every 1k calls to Seek, we add a check against this deadline, and in the case of a timeout, stop the iterator and return a timeout error response. With this addition, the YQL and DocDB have matching deadlines on the order of a few seconds to prevent the impact of runaway queries. Users can now also increase timeout to accommodate long-running range queries if needed.

Fig 2: After timeout improvement, CPU Usage of tablet server handling large scan.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


