How to Achieve High Availability, Low Latency and GDPR Compliance in a Distributed SQL Database
April 3, 2019
Today’s developers understand that the key requirement to converting and retaining customers is all about delivering fast and responsive experiences, while remaining resilient to failures and compliant with data governance regulations. YugabyteDB is purpose built for geo-distributed applications that require high availability, high performance and regulatory compliance. In this blog, we are going to “look under the hood,” to explore exactly how YugabyteDB distributes data across multiple clouds, regions and availability zones.
YugabyteDB is an open source, Google Spanner-inspired distributed SQL database for powering microservices and applications that require low latency, internet scale, geographic data distribution and extreme resilience to failures.
Global Apps Mandate Global Data Distribution
Let’s say you’re building an e-commerce, travel or gaming application and your business model requires that users be able to access your app from anywhere in the world. You also expect that every user will have an experience that is on par with those who happen to be geographically close to a datacenter, no matter how remote they are. With these business requirements, your database will need to deliver low latency and high availability, plus data distribution across multiple datacenters. Here are a few examples.
Retail and E-Commerce
The E-Commerce business is built on low latency and high availability. Today’s shoppers do not like waiting in queues, they expect responsive online storefronts. Online brands also have to account for large traffic spikes during certain times of the week, month, or year. When an E-Commerce platform cannot manage incoming traffic, the site slows down, inventory and product review lookups come to a crawl and the check-out process bottlenecks. The results? The customer experience suffers, dollars are lost and the brand’s reputation gets dinged. Traditional “brick and mortar” stores already know that they must quickly transform their business models or be left behind. Retailers are constantly looking for better ways to connect with consumers with a more personalized experience to make a sale and build brand loyalty.
Travel and Hospitality
At this point, the internet has democratized travel booking. Without the need for an agent, consumers can now search, compare and book travel online with relative ease, around the clock. Over the last two decades, the “look-to-book” ratios for many airline systems have climbed to somewhere in the region of 1,000:1. With such usage patterns, legacy global distribution systems (GDS) used in the travel industry have been re-platformed with various databases and caches placed between the browser and the system of record, just to keep up with the demand.
Online Gaming
Online gaming is a “hits” business where the expectation on latency is measured in milliseconds. A latency of more than a couple of hundred milliseconds in multi-player games can severely impact the user experience causing lags, time jumps, slow loading, failed creative downloads and continuously buffering content. Game publishers are constantly faced with the challenge of running a platform that delivers low latency consistently around the clock, and around the world. They are always looking for new ways to bring data closer users to squash latency.
High Availability through Geo-Redundancy
It goes without saying, but in the world of distributed systems, failures are inevitable. And when they do happen, it is important to recover fast and mitigate the severity of the failure. Here is an example of Amazon Web Services (AWS) most publicized outages:
- 2017: AWS Outage that Broke the Internet Caused by Mistyped Command
- 2017: Equinix Power Outage One Reason Behind AWS Cloud Disruption
- 2015: Here’s What Caused Sunday’s Amazon Cloud Outage
- 2015: Amazon Data Center Outage Affects Netflix, Heroku, Others
- 2013: Network Issues Cause Amazon Cloud Outage
- 2012: Software Bug, Cascading Failures Caused Amazon Outage
- 2012: Multiple Generator Failures Caused Amazon Outage
- 2012: Amazon Data Center Loses Power During Storm
What the above illustrates is that you cannot outsource 100% of your availability requirements. For business-critical apps, it is always prudent to have contingency plans for diverting traffic to other datacenters/regions if necessary. This can even mean using a different cloud provider like Google Cloud or Microsoft Azure to mitigate business impact resulting from AWS failures.
Low Query Latency with Geo-Distributed Data
In a geo-distributed app, the simplest way to ensure low query latency is to keep data for nearby users in a datacenter close to those users. This data has to be replicated to other geo-redundant datacenters so that the loss of the main datacenter can be tolerated automatically. For normal operations, the reads from the main datacenter should not require any consultation (such as quorum) with the faraway replicas. This will ensure absolute low latency guarantees that drive user satisfaction. However, when failures occur, there may be a temporary increase in latency because user requests will now have to be served by a datacenter that is farther away than the main datacenter.
Regulatory Compliance with Data Localization
Data governance and privacy laws like GDPR are becoming more common and more stringent across the world. Complying with such user data protection laws is increasingly becoming a key driver for restricting data distribution to specific geographies. For example, GDPR mandates data to be stored in particular regions (not leaving the region’s boundaries) and deleted whenever the user exercises his/her right-to-be-forgotten. Business competitors may also insist that their data or processes not be co-located with others, in the same physical servers, zones, or regions.
Global Data Distribution with YugabyteDB
Having established the need for global data distribution, let’s review how YugabyteDB helps us achieve this need. In this tutorial, we will perform the following actions to illustrate how to globally distribute nodes (and data) across different AWS regions.
- Step 1: Create a 3-node cluster with Replication Factor 3 and all nodes running the same region.
- Step 2: Add two new nodes, each in a different region.
- Step 3: Modify the cluster configuration so that the cluster automatically balances data across 3 nodes in 3 regions.
- Step 4: Move YB-Masters, the cluster coordinators, from the 2 old nodes to the 2 new nodes.
- Step 5: Decommission the 2 old nodes.
A YugabyteDB universe (a collection of nodes) can span multiple clouds, regions, and zones. For more detailed information on the difference between a universe, clusters, nodes and how distributed transactions and high availability work in YugabyteDB, check out these blogs.
- Basic Introduction to YugabyteDB Components
- Mapping YugabyteDB Concepts to PostgreSQL and MongoDB
- YugabyteDB High Availability & Transactions for PostgreSQL & MongoDB Developers
Placement information for the nodes can be passed via the command line using dot notation tuples (cloud.region.zone) separated by commas. Since the goal is to explain the concept, we will emulate node placement in AWS using a local cluster rather than create a true multi-node cluster on AWS.
Prerequisite
Install YugabyteDB on your local macOS or Linux workstation.
Step 1 : Create a cluster
Specify where YugaByte should create a cluster and with a replication factor of 3.
$ ./bin/yb-ctl --rf 3 create --placement_info \ "aws.us-west-2.us-west-2a,aws.us-west-2.us-west-2b,aws.us-west-2.us-west-2c"
After the successful execution of the above command, the master summary in the YugabyteDB Admin UI should look like the screenshot below. You’ll see that YB-Master is running on all the 3 nodes in the same region but in 3 availability zones, with the minimum requirement of 3 YB-Masters for reliability.
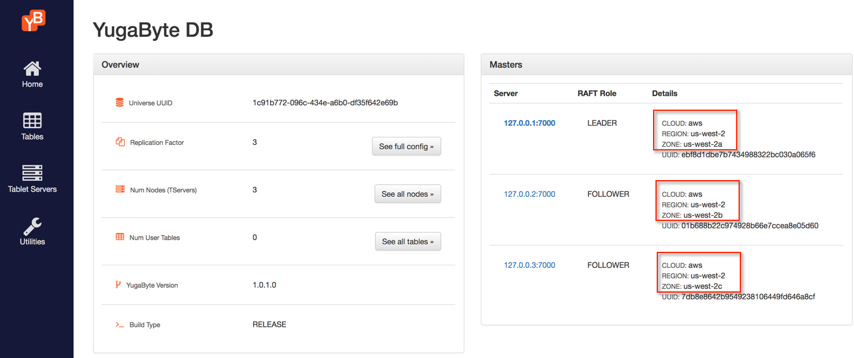
Step 2: Scale cluster across regions
Next, let’s add two more nodes to the cluster and place them in the East and Northeast AWS regions.
$ ./bin/yb-ctl add_node --placement_info "aws.us-east-1.us-east-1a" $ ./bin/yb-ctl add_node --placement_info "aws.ap-northeast-1.ap-northeast-1a"
The tablet summary of the dashboard should look like the screenshot below. You’ll notice that the nodes have been added but no workload has been allocated to these nodes yet.
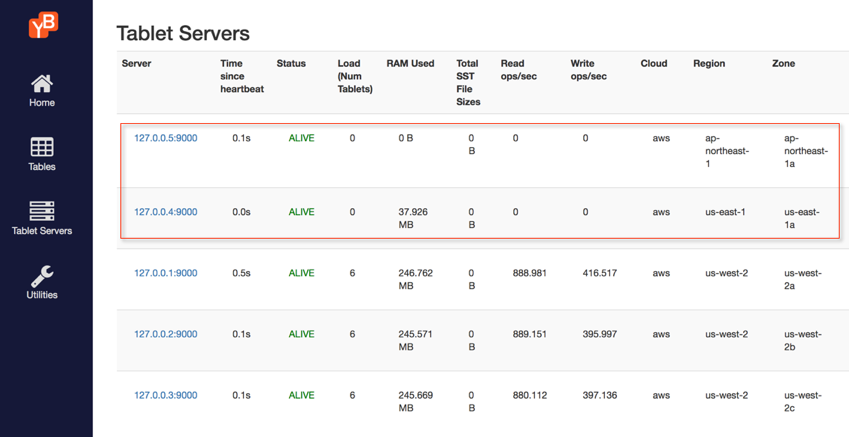
Step 3: Configure the cluster to utilize the new nodes/regions
Next, we’ll tell YB-Master to start placing data in the nodes that are in the new regions, East and Northeast AWS regions respectively.
$ ./bin/yb-admin \ --master_addresses 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \ modify_placement_info \ aws.us-west-2.us-west-2a, \ aws.us-east-1.us-east-1a, \ aws.ap-northeast-1.ap-northeast-1a \ 3
YugabyteDB will now start to move data from 2 nodes in the original region to the 2 newly added nodes in order to rebalance the cluster.

Step 4: Create new YB-Masters in the new regions
The YB-Masters are responsible for keeping system metadata, coordinating system-wide operations such as create/alter drop tables, and initiating maintenance operations such as load-balancing. They are not in the critical IO path of the database. Now that the data is moved, let’s move the YB-Master from the old nodes to the new nodes.
$./bin/yb-ctl add_node --master --placement_info "aws.us-east-1.us-east-1a" $./bin/yb-ctl add_node --master --placement_info "aws.ap-northeast-1.ap-northeast-1a"
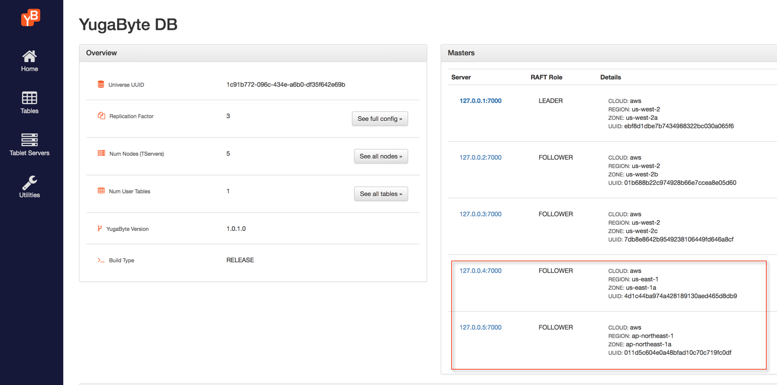
The YB-Master summary in the dashboard should look like the screenshot above with the new nodes now also registering as Masters.
Step 5: Decommission old nodes
The 2 original nodes now are not hosting any data since their YB-TServers are not storing any data. But they are still running the YB-Masters. Before we can decommission these nodes, we have to remove these YB-Masters from the cluster.
$./bin/yb-admin --master_addresses \ 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100,127.0.0.4:7100,127.0.0.5:7100 \ change_master_config REMOVE_SERVER 127.0.0.2 7100
$./bin/yb-admin --master_addresses \ 127.0.0.1:7100,127.0.0.3:7100,127.0.0.4:7100,127.0.0.5:7100 \ change_master_config REMOVE_SERVER 127.0.0.3 7100
The master summary in the dashboard should look like the screenshot below.
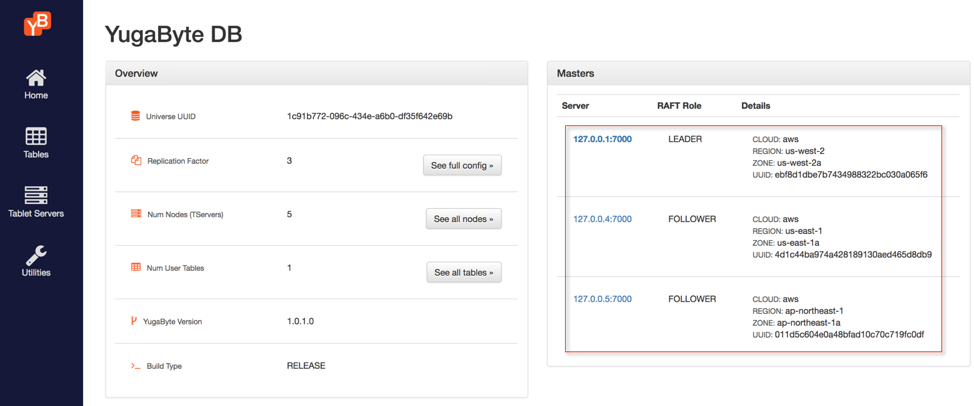
You can now remove the 2 original nodes from YugabyteDB cluster with the following command.
$ ./bin/yb-ctl remove_node 2 $ ./bin/yb-ctl remove_node 3
Comparing Global Data Distribution in Other Databases
MongoDB
In MongoDB, global data distribution can be accomplished by configuring replica set primary and secondary members to be aware of geographic regions and datacenter racks. Depending on the application workload, the administrator can choose from different sharding strategies such as hash, range and zone-based sharding. Zone-based sharding is the main mechanism through which geo-partitioning is achieved. MongoDB also allows tuning of quorum reads and writes, allowing all or only a subset of the replicas to participate. When deploying MongoDB in a multi-region cluster, configuring all these settings can be quite challenging for the user.
PostgreSQL
In PostgreSQL, writes happen to primary, and the logs generated are shipped to the replicas. If the rate of application writes is high, the latency to ship and apply logs is not able to catch up with the application write rate, the replicas can severely lag behind the primary. The log shipping approach can work within a datacenter, but across multiple data centers deployed across public clouds, this approach is not scalable. Many third-party vendors provide replication add-ons to alleviate this pain, but from the administrator perspective, it is one more system to manage in addition to the core RDBMS platform. As of this writing, PostgreSQL does not provide any out-of-the-box solution for global data distribution.
Summary
Globally distributed data architectures were previously used only by the technology giants such as Facebook and Google. However, today such architectures apply to many business-critical enterprise apps such as retail product catalog/checkout, travel booking, gaming leaderboards and multi-tenant SaaS. Extreme resilience to infrastructure failures, low query latency for end users and compliance with data governance regulations are the 3 main drivers for this change. YugabyteDB was built ground-up to help enterprises adopt global data distribution.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


