Google Spanner vs. Calvin: Is There a Clear Winner in the Battle for Global Consistency at Scale?
October 11, 2018
Prof. Daniel Abadi, lead inventor of the Calvin transaction management protocol and the PACELC theorem, wrote a thought-provoking post last month titled “NewSQL database systems are failing to guarantee consistency, and I blame Spanner”. The post takes a negative view of software-only Google Spanner derivative databases such as YugabyteDB and CockroachDB that use Spanner-like partitioned consensus for single shard transactions and a two phase commit (2PC) protocol for multi-shard (aka distributed) ACID transactions.
The primary argument is the following: without the hardware component of Spanner (essentially Google’s proprietary GPS-and-atomic-clock powered TrueTime API), these software-only databases are unable to guarantee correctness in distributed transactions when the clock skew on one of the participating nodes jumps beyond the configured maximum skew. When the clock jumps on any nodes, the standard practice in such systems, is to prefer loss of availability on those nodes and thereby ensure the cluster remains in a correct state. On the other hand, Calvin and its derivative database FaunaDB use a global consensus approach for both single shard and distributed transactions and hence are not susceptible to clock skews. The post argues that Calvin’s global consensus approach is strictly better for any application that requires transactional guarantees in distributed databases. As the team behind a Spanner derivative database, we at Yugabyte believe the argument is too simplistic and requires a more critical analysis.
Building distributed systems requires deep understanding and careful implementation of practical trade-offs across multiple approaches. So the right questions to ask in the context of the above debate around Spanner vs. Calvin derivative databases are:
- How is the performance of the database (in terms of throughput and latency) when the clock skew is below the maximum allowed?
- Are huge clock jumps more common in the public cloud or in private datacenters? What is the frequency of such jumps in practice?
- Is there a way to reduce this frequency?
- And finally, what are the application categories that each approach serves well?
Our analysis of these questions shows that the Calvin approach is good when transaction volume is low and/or there is high conflict access to same data in concurrent transactions whereas the Spanner approach is good for general purpose, high volume, concurrent transactions on random or non-conflicting data. Additionally, the lack of dependent transactions support in Calvin makes it unsuitable for building a SQL compatible database. This post details our analysis with the aim of educating application developers and database engineers on the trade-offs involved in choosing a transactional distributed database.
Clock Skew and its Impact on Transactions
Distributed systems inherently run on multiple nodes, each of which has a system clock that is sourced from the local hardware powering the system. Minor variations in the hardware and the environment will lead to the clocks drifting from each other even if they start perfectly synchronized. This drift is commonly referred to as clock skew. Protocols such as Network Time Protocol (NTP) allow the times at each node to be synchronized over the public internet with a common source of truth but there’s still no guarantee that all nodes will see the exact same time since internet network latency is unpredictable.
As highlighted in “A Primer on ACID Transactions: The Basics Every Cloud App Developer Must Know,” implementing the Isolation property of ACID transactions requires some sort of ordering among the various transactions being served by the database. For single-row and single-shard transactions, all the data impacted by the transaction is located in the purview of a single clock and ordering the transactions becomes easy especially if a leader-based distributed consensus protocol such as Paxos or Raft is used. However, for multi-shard transactions where shards can be located on independent nodes, we have no choice but to consider clock skew between the nodes. As we see in the next few sections, Google Spanner and Calvin take two very different approaches to this problem of clock skew tracking.
Google Spanner
As we previously described in “Implementing Distributed Transactions the Google Way: Percolator vs. Spanner,” Spanner is Google’s internal distributed database with support for distributed transactions that can span multiple regions across the globe. It was created specifically to address the limitations of Google Percolator, a single-region-only distributed transactions system. Even though its development started in 2007, Spanner was first introduced to the outside world in 2012 in the form a research paper. A subset of the Spanner system was made publicly available in 2017 on the Google Cloud Platform as a proprietary managed service called Google Cloud Spanner.
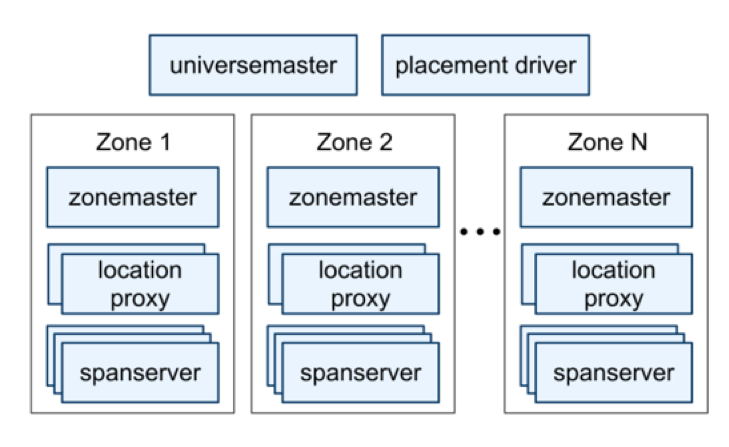
As shown above, a Spanner deployment is called a “universe”. A universe auto shards and auto balances the dataset using a one Paxos group per shard approach on machines located in multiple zones at datacenters spread all over the world. These shards are also replicated for global availability and geographic locality; clients automatically failover between replicas of a shard.
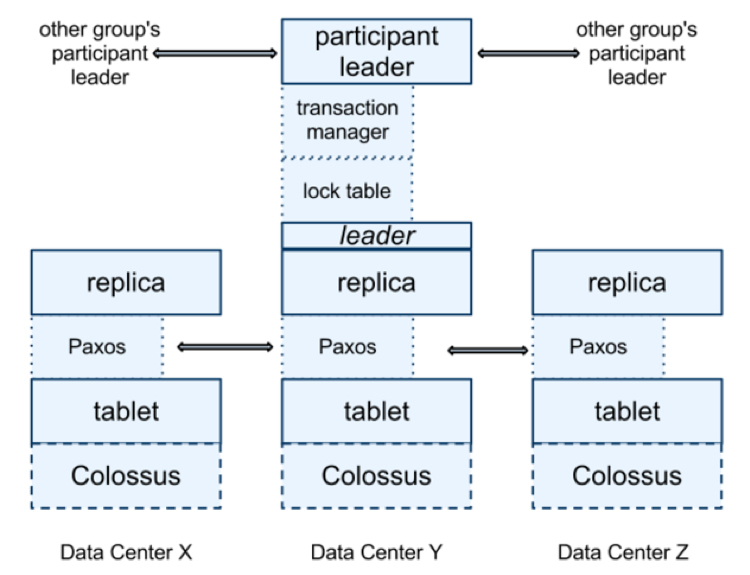
At every replica that is a leader, each spanserver implements a lock table to support two-phase-locking based concurrency control and a transaction manager to support distributed transactions. If a transaction involves only one Paxos group (as is the case in single-row & single-shard transactions), it bypasses the transaction manager since the lock table and Paxos together are enough to do the job here. If a transaction involves more than one Paxos group (as is the case in distributed transactions), those groups’ leaders coordinate to perform 2PC. The state of the transaction manager is also modeled as a persistent Paxos group to ensure continued availability.
The most noteworthy innovation in Spanner is that it achieves External Consistency, an isolation level similar to Strict Serializability. Spanner assigns global commit timestamps to all transactions using the TrueTime API. TrueTime is Google’s highly reliable “wall-clock” time tracking service (with a bounded uncertainty of 7ms) that is built on GPS and atomic clock hardware. It is the first real-world system to provide such a guarantee at global scale.
“YugabyteDB supports the Linearizability consistency in the context of single row updates. Since the C in CAP also refers to single row linearizability (and does not refer to multi-row updates), YugabyteDB is a CP database. For multi-shard/distributed ACID transactions, which by definition involve multiple rows, YugabyteDB supports both Snapshot isolation level (starting v0.9) and Serializable isolation level (starting v1.2.6).
Strict Serializability refers to multi-row transaction behavior that is equivalent to some serial execution, and the serial order corresponds to real time. Note that publications sometimes use the term “Linearizability” to refer to Strict Serializability when the overall context is multi-row transactions. We find this use confusing since the well accepted definition of Strict Serializability (see Peter Bailis and Jepsen) treats it as stricter than both Serializability and Linearizability.”
Calvin
Calvin is a transaction scheduling and data replication protocol created by Prof. Abadi and his students at Yale University. It was also published in 2012 as a research paper, only a few months before the Spanner paper.
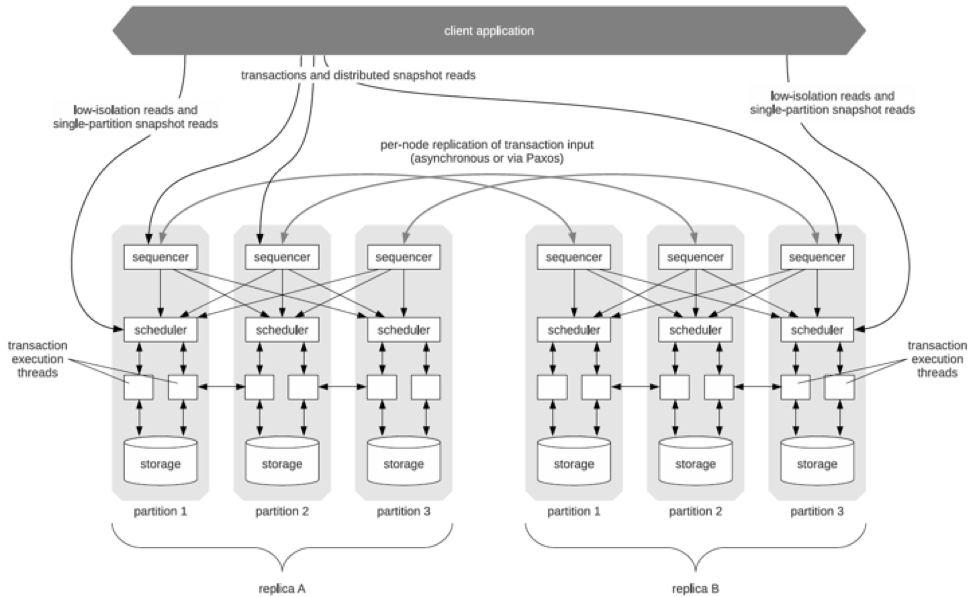
Prof. Abadi has detailed the architectural differences between Calvin and Spanner in his post titled “Distributed consistency at scale: Spanner vs Calvin.” The fundamental difference comes from the fact that Calvin avoids the need for Spanner’s TrueTime-based clock skew tracking by using preprocessing (aka sequencing) to order transactions. As shown in the figure above, the sequencers receive transactional inputs and then batch write them into a global transaction log. The sequence of this log is the order of transactions to which all replicas ensure serial equivalence during their execution. The sequencers therefore also handle the replication and logging of this input sequence (the paper allows either asynchronous or Paxos-based synchronous replication but FaunaDB uses the Raft protocol).
Calvin also avoids the need for Spanner’s 2PC through deterministic execution. The schedulers (shown in the figure above) orchestrate transaction execution using a deterministic locking scheme to guarantee equivalence to the serial order specified by the sequencers while allowing transactions to be executed concurrently by a pool of transaction execution threads.
Since Spanner applies consensus at an individual shard (aka partition) level whereas Calvin applies consensus only at the global sequencer level, Spanner’s approach can be thought of as partitioned consensus and Calvin’s approach can be thought of as global consensus.
Battle of the Derivatives: Spanner vs. Calvin
Now that we understand how Spanner and Calvin work under the hood, let’s review the exact conditions when Spanner derivative databases such as YugabyteDB and CockroachDB beat out FaunaDB, the only Calvin derivative database available today. Note that as an academic project, Calvin has no real-world implementation/usage outside of FaunaDB whereas Spanner has experienced extensive use inside Google for 10+ years and is not limited simply to its derivatives.
Correctness
The Spanner approach assumes a bounded clock skew whereas the Calvin approach does not even depend on clock skew tracking. This means Spanner derivative databases such as YugabyteDB guarantee correctness of multi-shard/distributed transactions only when the clock skew is lower than the maximum configured and usually shut down nodes when the constraint is violated. Note that for single-row and single-shard transactions, both the approaches are equivalent from a correctness standpoint. While the Spanner approach is an extremely effective one in practice, it does not guarantee correctness in theory which by definition requires accounting for every remotely possible condition. Assuming Calvin’s properties are theoretically proven, the Calvin approach seems like a better alternative when theoretical correctness is indeed important.
Another way to interpret the above correctness problem is that a Calvin derivative database such as FaunaDB can support Strict Serializability isolation level for distributed transactions whereas Spanner derivative databases can support only a maximum of Serializability isolation level and that too only under bounded clock skew scenarios.
Transaction Model
Spanner is designed to support the full complexity and richness of SQL as the client API. On the other hand, Calvin has a much more restrictive transaction model that can only support a NoSQL client API. Here are two examples where the richness of transaction modeling matters.
Secondary Indexes
As highlighted in “Speeding Up Queries with Secondary Indexes,” secondary indexes are a fundamental requirement for simplified application development. The Calvin paper states the following:
“Transactions which must perform reads in order to determine their full read/write sets (which we term dependent transactions) are not natively supported in Calvin since Calvin’s deterministic locking protocol requires advance knowledge of all transactions’ read/write sets before transaction execution can begin.”
and
“Particularly common within this class of transactions are those that must perform secondary index lookups in order to identify their full read/write sets.”
Given the above reason, Calvin suffers from repeated transaction restarts if the secondary index is on a column whose value is changing frequently. Spanner’s secondary indexes do not have this limitation and hence can support the full spectrum of secondary index workloads.
Session Transactions
Session transactions are an important feature in the world of SQL databases where the individual operations in a transaction are initiated by a client one after the other. The client can be a human being performing interactive transactions but can also be complex application code that requires pre-processing operations (such as executing if-then-else conditions based on the values read) before making the final update operation, all in a single ACID transaction. Spanner and its derivatives support session transactions while Calvin’s approach disallows such transactions as highlighted below.
This HackerNews post has details around why SQL support is not possible in FaunaDB or any Calvin derivative.
“…it has to do with the way Calvin handles transactions, which are required to declare their read and write sets before executing. These kind of transactions are also called static, and are normally of the type “I have this read/write operation(s) against multiple keys, go and do it” vs dynamic transactions that might depend on read values from the db to figure out what to do next.”
Read Performance
Read Latency
“Distributed consistency at scale: Spanner vs. Calvin” has a good discussion in this regard. It notes the following for read latency:
“Thus, Spanner has better latency than Calvin for read-only transactions submitted by clients that are physically close to the location of the leader servers for the partitions accessed by that transaction.”
The benefit of the Spanner approach is observed in the read path since the read can be served directly off the leader of a shard without consulting any other replica. This is especially helpful in case of write-infrequent, read-intensive, geo-partitioned use cases such as a global user identity service where data for any given region is usually leadered in the same region. Transactional reads in Calvin would still need to go through global consensus in such cases and hence will be of higher latency than Spanner. The latency gets worse for multi-region clusters spanning distant geographies since reads from any region have to be redirected to the region where the current global consensus leader is located.
Read Throughput
Spanner also beats Calvin when it comes to read throughput. Since strongly consistent reads are served by the shard leaders evenly distributed across all nodes in the cluster, there is no central bottleneck in the system and each node can contribute its fair share for serving the read requests. Addition of nodes rebalances the shard leaders across the entire cluster by moving some shard leaders from existing nodes onto the new nodes. This leads to linear scaling of read throughput. On the other hand, the single global leader in Calvin can easily become the central bottleneck in the cluster especially in high volume ingest use cases such as IoT and Time Series.
Write Performance
Workload Type
AWS CTO Werner Vogels notes in his “A Decade of Amazon Dynamo” post that transactional apps can be thought of as 90% single row/single shard updates (aka the majority workload) and 10% multi-shard updates (aka the minority workload). Even if the distribution is not so skewed for every enterprise app, there is no argument to the fact that the majority workload in transactional apps is indeed of the single row/shard type. Let’s review how Spanner and Calvin deal with these workload types.
The Spanner approach clearly distinguishes between single row/shard updates involving a single consensus group (and serves them without any 2PC) vs. a multi-shard update involving multiple consensus groups (and hence uses a 2PC coordinated by a highly available transaction manager). Assuming random row access in the workloads, the Spanner approach allows every node (usually hosting multiple shard leaders) to contribute its fair share to serve the majority workload while ensuring that the minority workload can be served as efficiently as possible (including automatic retries when conflicts are detected). With auto-rebalancing of leaders when nodes are added or removed, this approach lends itself very well to dynamic scaling.
On the other hand, both majority and minority workloads contend for the single leader of the global consensus group in Calvin. The resources on all other nodes remain under-utilized since they are not able to contribute to the incoming write requests. Addition of new nodes does not increase the throughput since there can be only one leader. The net result is that the Spanner approach achieves much higher write throughput than Calvin for applications with random row access.
Calvin can achieve higher write throughput than Spanner for a specific kind of application where the majority workload is essentially distributed transactions with concurrent access to same rows and data volume is low enough to not overwhelm the single global leader. “Distributed consistency at scale: Spanner vs. Calvin” also notes the following.
“Overall, Calvin has higher throughput scalability than Spanner for transactional workloads where concurrent transactions access the same data. This advantage increases with the distance between datacenters.”
Transactional Latency
“Distributed consistency at scale: Spanner vs. Calvin” states the following for write latency:
“Thus, Spanner and Calvin have roughly equivalent latency for single-partition transactions, but Spanner has worse latency than Calvin for multi-partition transactions due to the extra phases in the transaction commit protocol.”
For single row/shard transactions, the Spanner approach is equivalent to that of the Calvin approach. Specifically, YugabyteDB is engineered for low latency in C++ using a deep integration between DocDB (the RocksDB-based custom storage engine) and Raft (the distributed consensus replication protocol).
For distributed (aka multi-partition) transactions, Spanner’s distributed consensus and 2PC approach requires each partition’s writes to be routed through the leader of that shard. This leads to higher write latency for such distributed transactions than that of the Calvin approach where the cost is bounded by a single global leader (of the sequencing layer). The assumption here is that the global consensus latency in Calvin is significant higher than the latency observed in batching writes into the transaction log.
Fault Tolerance
By distributing shard leaders across all nodes, Spanner minimizes the impact of loss of any one node in the cluster irrespective of the reason for the loss (including node crash or network partitions). A node loss leads to a loss of a subset of shard leaders and the replicas of these impacted shards on the remaining nodes now elect new leaders. So, the write unavailability is limited to a subset of data. However, the Calvin approach is very unforgiving for the loss of the node that hosts the global consensus leader. The entire cluster is now unavailable for writes till the new leader election completes and the leader now available at a different node. Even if we take the leader election time as same across the two approaches, the Calvin approach has a significantly higher negative impact.
Clock Skew Mitigation
Public cloud providers are rapidly adding TrueTime-like APIs as services to their platform so that workloads that need them can now use them easily. E.g. the AWS Time Sync Service, introduced late 2017, allows databases such as YugabyteDB to synchronize the clock on their machines to a much higher degree of accuracy than was previously possible. And the best part is that this service is provided at no additional charge and is available in all public AWS regions to all instances running in a VPC. Microsoft Azure has a slightly less-sophisticated VMICTimeSync service that is still more reliable than the basic NTP. And even though Google’s TrueTime API is not available for public use, its leap-smeared NTP service is indeed available as Google Public NTP. This trend will continue as public cloud platforms continue to invest heavily in becoming the preferred destination for user-facing, mission-critical, global applications that need stronger consistency than ever before. By leveraging these TrueTime-like services, Spanner derivative databases are well positioned to increase the boundaries of their practical correctness. On the other hand, on-premises datacenters cannot easily increase the reliability of their NTP sync service. Wild jumps in clocks can be expected while the database is processing distributed transactions. Using a Calvin derivative database would make more sense in this case.
Open Source Core
YugabyteDB and CockroachDB are both distributed under the highly permissive Apache 2.0 open source license. Users can contribute to the database and also create their own custom fixes in their own forks if they so desire. On the other hand, FaunaDB is a fully proprietary database that provides none of the benefits of open source software.
Open APIs
YugabyteDB is a PostgreSQL-compatible distributed SQL database on top of a Spanner-inspired distributed storage engine. Similarly, CockroachDB is wire compatible with PostgreSQL. However, FaunaDB has its own proprietary custom language that slows down application development on day 1 and creates a new vendor lock-in on day 2.
Summary
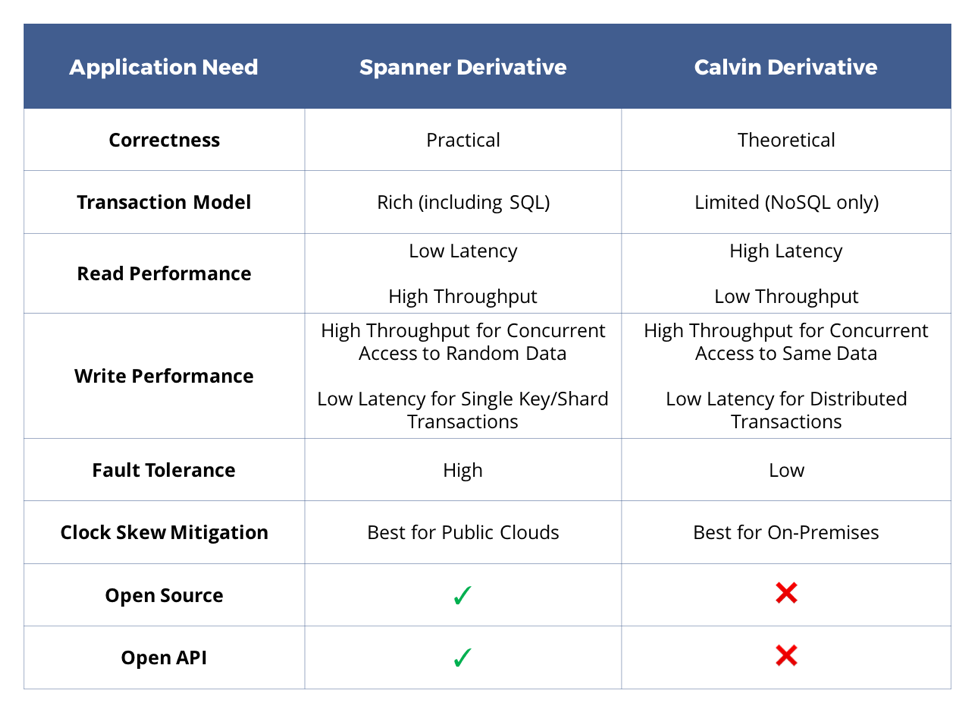
Both Spanner and Calvin are exciting advancements in the area of strongly consistent database design. As summarized in the table above, each approach comes with its own set of trade-offs. Picking a Calvin derivative database makes sense for a distributed-transaction-heavy workload with high concurrent access to the same set of rows. The more important question is how future-proof the database is with regard to changing application needs from say distributed-transaction-heavy to single-row-or-shard-transaction heavy or from on-premises to public cloud. A more detailed comparison with Spanner derivatives such as YugabyteDB becomes inevitable then.
Specifically, YugabyteDB handles both distributed-transaction-heavy workloads (by virtue of its globally distributed transaction manager) and on-premises deployments (with tunable max clock skew) very well. As transactional applications become more geo-distributed and more read-latency-sensitive, application developers can leverage YugabyteDB as the highly elastic system-of-record database that helps them release faster. This is because developers are now free to concentrate on the business layer of the application without getting bogged down with expensive migrations in the database layer.
What’s Next?
- Read our previous post on “Implementing Distributed Transactions the Google Way: Percolator vs. Spanner.”
- Get started with YugabyteDB on the cloud or container of your choice.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


