Getting Started with SQLPad and Distributed SQL on Google Kubernetes Engine
July 29, 2020
SQLPad is an MIT licensed web app written in React and Node.js for writing and running SQL queries and visualizing the results. SQLPad supports PostgreSQL, MySQL, SQL Server, Crate, Vertica, Presto, SAP HANA, Cassandra, Snowflake, Google BigQuery, SQLite, and many more via ODBC. Because YugabyteDB is PostgreSQL compatible, most third-party tools and apps will work “out of the box.” SQLPad is no exception here.
In this blog post we’ll show you how to:
- Install a 3 node YugabyteDB cluster on Google Kubernetes Engine
- Build the sample Northwind database
- Build and configure SQLPad
- Start the required SQLPad processes
- Launch the SQLPad UI and issue a test query to validate the deployment

New to distributed SQL or YugabyteDB? Read on.
What is Distributed SQL?
Distributed SQL databases are becoming popular with organizations interested in moving data infrastructure to the cloud or to cloud native environments. This is often motivated by the desire to reduce TCO or move away from the scaling limitations of monolithic RDBMS like Oracle, MySQL, and SQL Server. The basic characteristics of Distributed SQL are:
- A SQL API for querying and modeling data, with support for traditional RDBMS features like primary keys, foreign keys, indexes, stored procedures and triggers.
- Automatic distributed query execution so that no single node becomes a bottleneck.
- A distributed SQL database should support automatically distributed data storage. This includes indexes which should be automatically distributed (aka sharded) across multiple nodes of the cluster so that no single node becomes a bottleneck for ensuring high performance and high availability.
- Distributed SQL systems should also provide for strongly consistent replication and distributed ACID transactions.
For a deeper discussion about what Distributed SQL is, check out, “What is Distributed SQL?”
What is YugabyteDB?
YugabyteDB is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. YugabyteDB is PostgreSQL wire compatible with support for advanced RDBMS features like stored procedures, triggers, and UDFs.
Step 1: Install YugabyteDB on a GKE Cluster using Helm 3
In this section we are going to install YugabyteDB on the cluster. The complete steps are documented here. We’ll assume you already have a GKE cluster up and running as a starting point.
The first thing to do is to add the charts repository.
$ helm repo add yugabytedb https://charts.yugabyte.com
Now, fetch the updates.
$ helm repo update
Create a namespace. In this case we’ll call it yb-demo.
$ kubectl create namespace yb-demo
Expected output:
namespace/yb-demo created
We are now ready to install YugabyteDB. In the command below we’ll be specifying values for a resource constrained environment.
$ helm install yb-demo yugabytedb/yugabyte \ --set resource.master.requests.cpu=1,resource.master.requests.memory=1Gi,\ resource.tserver.requests.cpu=1,resource.tserver.requests.memory=1Gi,\ enableLoadBalancer=True --namespace yb-demo --wait
To check the status of the cluster, execute the below command:
$ kubectl get services --namespace yb-demo

Note the external-IP for yb-tserver-service which we are going to use to establish a connection between YugabyteDB and SQLPad. From the screenshot above we can see that the IP is 34.72.XX.XX and the YSQL port is 5433.
The next step is to download a sample schema and data. You can find a variety of sample databases that are compatible with YugabyteDB in our Docs. For the purposes of this tutorial we are going to use the Northwind sample database. The Northwind database contains the sales data for a fictitious company called “Northwind Traders,” which imports and exports specialty foods from around the world. The Northwind database is an excellent tutorial schema for a small-business ERP, with customers, orders, inventory, purchasing, suppliers, shipping, employees, and single-entry accounting.
Connect to the yb-tserver-pod by running the following command:
$ kubectl exec -n yb-demo -it yb-tserver-0 /bin/bash
To download the schema and data files, run the following commands:
$ wget https://raw.githubusercontent.com/yugabyte/yugabyte-db/master/sample/northwind_ddl.sql $ wget https://raw.githubusercontent.com/yugabyte/yugabyte-db/master/sample/northwind_data.sql
Note: If the Google Cloud Shell tells you that the wget command does not exist, you can execute:
$ yum install wget -y
To connect to the YSQL service, exit out of the pod shell and run the following command:
$ exit $ kubectl exec -n yb-demo -it yb-tserver-0 -- ysqlsh -h yb-tserver-0.yb-tservers.yb-demo
Create a database and connect to it using the following commands:
yugabyte=# CREATE DATABASE northwind; northwind=# \c northwind;
Create the database objects and load them up with data using the following commands:
northwind=# \i 'northwind_ddl.sql'; northwind=# \i 'northwind_data.sql';
Verify that the tables are created by running the following command:
northwind-# \d
List of relations
Schema | Name | Type | Owner
--------+------------------------+-------+----------
public | categories | table | yugabyte
public | customer_customer_demo | table | yugabyte
public | customer_demographics | table | yugabyte
public | customers | table | yugabyte
public | employee_territories | table | yugabyte
public | employees | table | yugabyte
public | order_details | table | yugabyte
public | orders | table | yugabyte
public | products | table | yugabyte
public | region | table | yugabyte
public | shippers | table | yugabyte
public | suppliers | table | yugabyte
public | territories | table | yugabyte
public | us_states | table | yugabyte
(14 rows)
Verify we have data by issuing a simple SELECT:
northwind=# SELECT count(*) FROM products;
count
-------
77
(1 row)
Step 3: Build and configure SQLPad
We are now ready to install SQLPad. Exit YSQL and return to the main Google Cloud shell.
northwind=# exit
Execute the following commands to install the various dependencies and required versions of software. For more information on what’s required for your particular environment, check out the SQLPad developer guide. Below is what worked for me on a default Google Cloud VM environment:
First, update some dependencies required for compilation, upgrade the version of Node to 12.0 or greater, and install SQLite3.
$ sudo apt-get install build-essential $ sudo apt update $ sudo apt install build-essential checkinstall libssl-dev $ nvm install 14.5.0 $ nvm alias default 14.5.0 $ npm install sqlite3
Next, clone the SQLPad repo.
$ git clone https://github.com/rickbergfalk/sqlpad.git
Now, run the SQLPad build script, set it up as a global module, and start the app.
$ cd sqlpad/ $ ./scripts/build.sh $ cd server $ npm install -g $ node server.js --config ./config.dev.env
You can now access the SQLPad UI at: https://localhost:3010
After setting up your administrator credentials, you should see something like this in your browser.
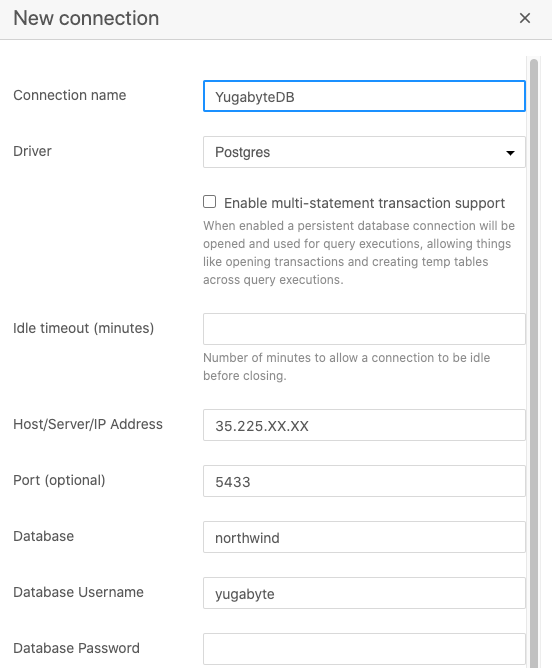
Next, let’s configure the connection to YugabyteDB by selecting “New Connection” in the dropdown above the object explorer. Here’s the basic information we’ll need to set it up, which we discovered in Step 1:
- Driver: Postgres
- Host: 34.72.XX.XX
- Port: 5433
- Database: northwind
- User: yugabyte
- Password: There is no password for the default “yugabyte” user upon initial installation
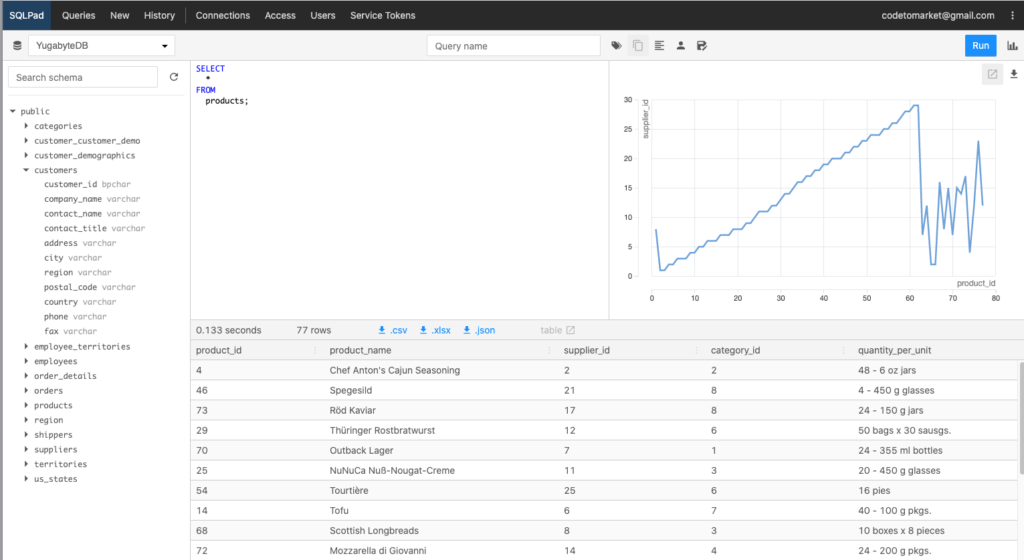
Now that we are connected to the YugabyteDB cluster, you can see all the Northwind database objects in the explorer tree on the left-hand side. Let’s issue a basic query against the Northwind sample database and examine the result set. In this case we are simply going to select all the rows in the products table.
That’s it! You now have a PostgreSQL-compatible, 3 node YugabyteDB cluster running on GKE connected to the SQLPad UI. To learn more about supported third-party PostgreSQL tools that work with YugabyteDB, check out the YugabyteDB Documentation or join our community Slack and hit us up there.


