Docker, Kubernetes and the Rise of Cloud Native Databases
June 11, 2018
Containerized Stateful Services Are Here
Results from the 2018 Kubernetes Application Usage Survey should put to rest concerns enterprise users have had around the viability of Docker containers and Kubernetes orchestration for running stateful services such as databases and message queues. Its exciting to see that nearly 40% of respondents are running databases (SQL and/or NoSQL) using Kubernetes. This number will continue to grow in the months ahead.
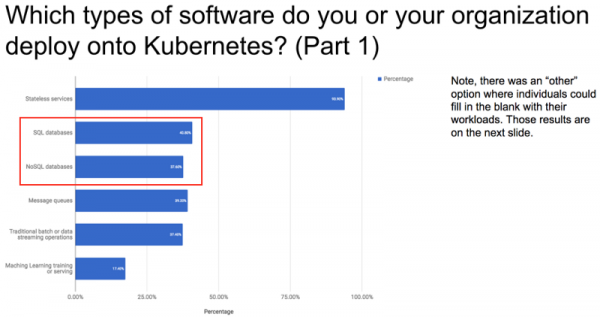
SQL and NoSQL Databases on Kubernetes
The above trend has been in the making for quite some time. Enterprise dev and operations teams have been getting increasingly comfortable in running stateful services in non-production environments over the last couple of years. As we have seen before in the case of AWS public cloud, infrastructure that gets widely adopted in non-production environments has a habit of also showing up in production environments, especially as the technology foundation matures. Maturity in persistent volumes and stateful workload APIs has created a similar situation for containerized stateful services.
The 2018 Docker Usage Report by Sysdig gives insights into the exact SQL and NoSQL databases getting adopted. The monolithic SQL database category is led by PostgreSQL while the distributed NoSQL category is led by MongoDB, Redis and Elasticsearch. However, none of these databases were architected for the inherent unreliability and dynamic nature of containers, a problem that gets exacerbated in public cloud platforms. Significant custom scripting and/or 3rd party tools are used to handle key aspects such as replication, failover and backups. However, it should be noted that adding ACID transactions to NoSQL databases to make them reliable or adding linear write scalability to SQL databases to make them scalable are core architecture problems that cannot be solved through any external tooling.

12 Most Popular Containers (Source: 2018 Docker Usage Report)
Container Orchestration Wars Are Over

Irrespective of whether the service is stateful or stateless, containerized services have to be run under the watchful eye of a container orchestrator. Much has been written about the container orchestration wars especially between the top 3 contenders namely Kubernetes, Docker Swarm and Apache Mesos. These wars are now over and the 4yr old Kubernetes has been crowned the de facto king. Docker, the company behind the Docker runtime, added Kubernetes as a pluggable orchestration engine to its Docker CE and EE products late 2017. Docker Swarm continues to remain the default engine for Docker products. A similar announcement came from Mesosphere in the context of its Apache Mesos-based DC/OS products with Marathon remaining as its default container orchestration engine.
Do the above developments mean that Docker Swarm and Apache Mesos are no longer relevant for enterprise users? That is certainly not the case. Sysdig’s 2018 Docker Usage Report gives us the necessary insights. Docker Swarm’s usage has been growing steadily since its launch thanks to its incredibly low barrier to entry (as the default engine for Docker CE) albeit for smaller cluster sizes. Apache Mesos is no longer growing at a high rate but it continues to have much larger clusters under management than both Kubernetes and Docker Swarm. This is understandable given its roots as a Big Data orchestration engine that was more general purpose than Hadoop’s YARN.
Hello Container Management Wars!
In the last year, Docker and Mesosphere have positioned their commercial products as broad container management offerings that go beyond Kubernetes-based orchestration. These management products typically address mid-to-large enterprise needs such as security & compliance, application-aware automation and multi-tenancy.

In fact, container management has become the new war front for enterprise dollars — RedHat OpenShift, Pivotal Kubernetes Service, Rancher are also in the same market aiming to capitalize on the trend towards multi-cloud deployments powered by the portability offered by containers. At the same time, the big 3 cloud platforms (AWS, Google Cloud and Microsoft Azure) are doubling down on their managed Kubernetes offerings to ensure their underlying IaaS gets the majority share in the new multi-cloud era.
Rise of Cloud Native Databases
Defining Cloud Native
With databases getting containerized, container orchestration getting standardized (to Kubernetes), and container management wars heating up, the question to ask is “Are there databases available today that can better exploit cloud native infrastructure such as containers and Kubernetes?” The answer is yes.
Let’s start with the Cloud Native Computing Foundation (CNCF) definition for Cloud Native technologies.
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach. These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
One important principle that is not explicitly stated in the above definition is that of global distribution. Adrian Cockroft, VP Cloud Architecture Strategy at AWS, rightly points out in Mapping Your Stack that the ability to become instantly global is core to cloud native technologies. This is because the modern cloud is inherently global across multiple regions and not simply a way to rent hardware in a single region.

Cloud Native Databases
If we apply the above definition to the current CNCF Landscape (see below), only a few databases stand out. Note that the landscape includes analytics-focused data warehouses which we will exclude from our analysis of operational databases.

Database and Data Warehouse Landscape (Source: CNCF)
Apply the additional criteria of open source and ACID compliance and the choices are now limited to only 5 databases— Vitess, CockroachDB, FoundationDB, TiDB and YugabyteDB. No surprise that all of these have come into the limelight only in the last 2 years exactly when cloud native application development and infrastructure deployment has taken off.
The following is a quick look at how these databases differ from each other.

Summary
These are exciting times for infrastructure software especially those necessary to power agile applications. Microservices running on stateless containers orchestrated by Kubernetes and Docker Swarm have become commonplace. Users now want stateful containers to be orchestrated and managed using the same set of technologies. Operational databases storing mission-critical data are arguably the most important among all stateful workloads. A new breed of cloud native databases are rising to meet the user demand with scalability, resilience, observability, manageability and portability built into the core architecture more so than the legacy databases of the past. YugabyteDB aims to lead this pack with its unique approach of enabling multi-API, multi-model application development on top of a single transactional, high performance, globally distributed storage engine. Start a local YugabyteDB cluster on Docker or Kubernetes (on minikube) to see for yourself.


