Distributed SQL Tips and Tricks – June 29, 2020
June 29, 2020
Welcome to this week’s tips and tricks blog where we recap some distributed SQL questions from around the Internet. We’ll also review upcoming events, new documentation, and blogs that have been published since the last post. Got questions? Make sure to ask them on our YugabyteDB Slack channel, Forum, GitHub, or Stackoverflow. Ok, let’s dive right in:
Regular expression queries (or pattern matching queries)
YugabyteDB inherits PostgreSQL upper layer, therefore it includes most PostgreSQL functionalities in a distributed cluster. One of them is REGEXP queries. PostgreSQL and thus YugabyteDB support three separate approaches to pattern matching: the SQL LIKE operator, the SIMILAR TO operator, and POSIX-style regular expressions. Some examples below:
yugabyte=# SELECT 'abc' LIKE 'c%'; -- false yugabyte=# SELECT 'abc' LIKE 'a%'; -- true yugabyte=# SELECT 'abc' SIMILAR TO '%(b|d)%'; -- true yugabyte=# SELECT 'abc' SIMILAR TO '(b|c)%'; -- false yugabyte=# SELECT 'abc' ~ '^(b|c)'; -- false yugabyte=# SELECT 'abc' ~ '^a'; -- true
Check out the PostgreSQL docs for all examples and usages.
Getting the current timestamp in YSQL
Recently a user was getting incorrect results when inserting the current timestamp generated on the server into a column with datatype (plain) timestamp. The timestamp was generated using the now() function which returns a value whose data type is timestamptz—see below.
YugabyteDB inherits from PostgreSQL two types for timestamps: timestampz (short for timestamp with time zone) and timestamp (short for timestamp without time zone).
Both types store a bare timestamp value using the same on-disk representation. The crucial difference is due precisely to the accompanying data type metadata. It’s this that determines what happens both when you set a value and when you get a value. When you set and get a plain “timestamp” field (or PL/pgSQL variable) nothing at all happens. It’s up to you to interpret the values according to your own convention. But when you set a “timestamp with time zone” field (or PL/pgSQL variable) YSQL (Yugabyte’s SQL API) converts your value (which is understood with respect to the session’s current time zone) into UTC; and when you get it, it converts that stored UTC value to be correct in the session’s present time zone—which time zone might not be the same as it was when the value was stored.
The problem happens when we try to insert the current timestamp returned from now() into a timestamp column. now() returns the current timestamp in the session time zone, which might well not be the one that you chose as the one in which to interpret your plain timestamp values. When it’s inserted in the timestamp column, the time zone is dropped thus inserting a wrong value. An example below:
yugabyte=# create table test(a int primary key, b timestamp without time zone);
yugabyte=# select now(), pg_typeof(now());
now | pg_typeof
-------------------------------+--------------------------
2020-05-06 16:44:03.917735-07 | timestamp with time zone
(1 row)
yugabyte=# insert into test values (1, '2020-05-06 16:44:03.917735-07');
yugabyte=# select * from test;
a | b
---+----------------------------
1 | 2020-05-06 16:44:03.917735
(1 row)
yugabyte=# show timezone;
TimeZone
------------
US/Pacific
We can see that the column “b” discards the time zone. This means that the stored result is wrong in the sense that it does not respect the user’s convention to understand stored plain timestamp values as UTC values. Of course, the stored value does correctly respect the defined semantics of plain timestamp and “now()”—so this is a user programmed bug! The user can remedy this by using (now() at time zone 'utc'):
yugabyte=# insert into test values (2, (now() at time zone 'utc')); yugabyte=# select * from test; a | b ---+---------------------------- 1 | 2020-06-10 19:38:22.859175 (1 row)
How to get query metrics in YSQL?
YugabyteDB has the pg_stat_statements extension from PostgreSQL installed by default. The query execution metrics can be viewed via the “YSQL All Ops” link on the https://yb-tserver-ip:9000/utilz page:
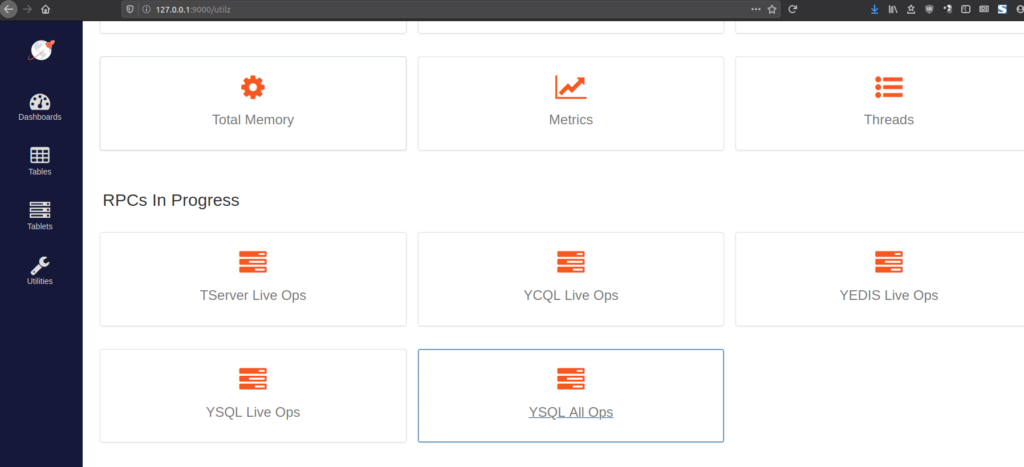
You can also query the data from YSQL:
yugabyte=# CREATE EXTENSION pg_stat_statements;
yugabyte=# select pg_sleep(3);
yugabyte=# SELECT query, calls, total_time, mean_time, stddev_time, rows FROM pg_stat_statements ORDER BY total_time DESC LIMIT 5;
query | calls | total_time | mean_time | stddev_time | rows
-------------------------------------------------------------------------------------------------------------------------+-------+-------------+-------------+-------------+------
select pg_sleep($1) | 1 | 3003.182174 | 3003.182174 | 0 | 1
create extension pg_stat_statements | 1 | 925.11284 | 925.11284 | 0 | 0
For a quick example we’re using pg_sleep(3) function where the query lasts 3 seconds by sleeping. Note that each server returns only its local statistics. We’re currently working for global level query metrics.
What is the best way to check if a row exists?
The best way to check if a row exists is to use:
yugabyte=# CREATE TABLE test(id BIGSERIAL PRIMARY KEY); yugabyte=# INSERT INTO test(id) VALUES (13); yugabyte=# SELECT EXISTS(SELECT 1 FROM test WHERE id=11) AS "exists"; exists -------- f (1 row) yugabyte=# SELECT EXISTS(SELECT 1 FROM test WHERE id=13) AS "exists"; exists -------- t (1 row)
The good thing about using EXISTS is that it always returns a boolean value instead of None (like in some languages such as Python) when just querying for the row:
yugabyte=# SELECT id FROM test WHERE id=11; id ---- (0 rows)
New Documentation, Blogs, Tutorials, and Videos
New Blogs
- Polymorphism in SQL part one – anyelement and anyarray
- Polymorphism in SQL part two – variadic functions
- SQL Puzzle: Partial Versus Expression Indexes
- Real-Time Scalable GraphQL and JAMstack with Gatsby, Hasura, and YugabyteDB
- Getting Started with Distributed SQL on Red Hat OpenShift with YugabyteDB Operator
- Oracle vs PostgreSQL: First Glance – Testing YugabyteDB’s Compatibility
- Part 1: Deploying a Distributed SQL Backend for Apache Airflow on Google Cloud
- Part 2: Airflow DAGs for Migrating PostgreSQL Data to Distributed SQL
- Highly Available Prometheus Metrics for Distributed SQL with Thanos on GKE
New Videos
- Getting Started with YugabyteDB and GraphQL on Kubernetes
- Evaluating CockroachDB vs YugabyteDB
- Developing Cloud Native Spring Microservices with Distributed SQL, Cluster-Aware JDBC Drivers, R2DBC, and Istio
New and Updated Docs
- We’re continually adding to and updating the documentation to give you the information you need to make the most out of YugabyteDB. We had so many new and updated docs for you, that we wrote a blog post to cover recent content added, and changes made, to the YugabyteDB documentation – What’s New and Improved in YugabyteDB Docs
Upcoming Events
- Jun 30 @ 2pm CDT [3pm EDT] – Taming Cross-Region Latency in Geo-Distributed SQL Databases talk at the Open Source Summit North America
- July 15 @ 10am PDT [1pm EDT] – YugabyteDB Community Q&A, Topic: PostgreSQL Compatibility; get a short demo then open Q&A
- Aug 17 – 20 – KubeCon + CloudNativeCon Europe 2020 Virtual
Get Started
Ready to start exploring YugabyteDB features? Getting up and running locally on your laptop is fast. Visit our quickstart page to get started.

 When Node Is Lost and Then Brought Back Into Cluster?")
