Distributed SQL Tips and Tricks – Feb 21, 2020
February 21, 2020
Welcome to this week’s tips and tricks blog where we recap some distributed SQL questions from around the Internet. We’ll also review upcoming events, new documentation, and blogs that have been published since the last post. Got questions? Make sure to ask them on our YugabyteDB Slack channel, Forum, GitHub, or Stackoverflow. Ok, let’s dive right in:
When should I use JSON vs JSONB data types?
Because YugabyteDB reuses PostgreSQL’s query layer, it provides two column types to store JSON values: json & jsonb. Both data types accept json strings but have different implementations. The json type is stored as a JSON string, while jsonb is parsed and stored as a binary implementation. jsonb adds extra overhead when inserting, but lowers the overhead when reading. This is because the json type has to be deserialized each time it is queried.
It should also be noted that the jsonb implementation strips whitespace, removes duplicate object keys by keeping only the last value, and does not preserve the order of object keys. We generally recommend using jsonb unless your app has specialized assumptions.
For more information on how to work with JSON documents in YugabyteDB check out the Docs.
Can JSONB fields be indexed in YSQL?
Yes, JSON fields can be indexed in YSQL, YugabyteDB’s Postgresql-compatible API. This is accomplished with the use of “expression indexes”. Expression indexes can be used with any indexable data type and expression that YSQL supports.
Below is an example using expression indexes with the jsonb data type:
yugabyte=# CREATE TABLE users(id INT PRIMARY KEY, profile JSONB);
CREATE TABLE
yugabyte=# CREATE INDEX email_index ON users (((profile->>'email')::text));
CREATE INDEX
yugabyte=# INSERT INTO users(id, profile) VALUES (1, '{"name": "john", "email": "john@xyz.com"}');
INSERT 0 1
yugabyte=# INSERT INTO users(id, profile) VALUES (2, '{"name": "jone", "email": "jane@xyz.com"}');
INSERT 0 1
yugabyte=# SELECT * FROM users WHERE (profile->>'email')::text = 'jane@xyz.com';
id | profile
----+-------------------------------------------
2 | {"name": "jone", "email": "jane@xyz.com"}
(1 row)
The above query uses the email_index index to quickly find the row, and we can use EXPLAIN to confirm the same.
yugabyte=# EXPLAIN SELECT * FROM users WHERE (profile->>'email')::text = 'jane@xyz.com';
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using email_index on users (cost=0.00..4.12 rows=1 width=36)
Index Cond: ((profile ->> 'email'::text) = 'jane@xyz.com'::text)
(2 rows)
How can I limit the time a client will wait for long running queries?
Because YugabyteDB is PostgreSQL compatible, this process is identical. To set the timeout to 30 secs for the duration of the client’s connection use:
set statement_timeout to 30000;
If the 30 seconds elapses before the query completes, you’ll see:
ERROR: canceling statement due to statement timeout
To find out what the value is set at, execute the following:
show statement_timeout; statement_timeout ------------------- 30s (1 row)
How are the shard leaders distributed across nodes in YugabyteDB?
And for multi-region installations, the follow on question was: Does YugabyteDB have something along the lines of Google Cloud Spanner’s notion of a “default leader” region for performance reasons. For instance, Spanner recommends, “Place the bulk of your read and write workloads in the default leader region.”
Tablet (shard) leaders in YugabyteDB are distributed as evenly as possible across yb-tserver nodes. This helps spread read/write workloads because tablet leaders are consulted for reads and writes.
Currently we expose tablet leader/followers on the yb-master UI. We can see the overall tablet counts on https://<any-yb-master-ip>:7000/tablet-servers.
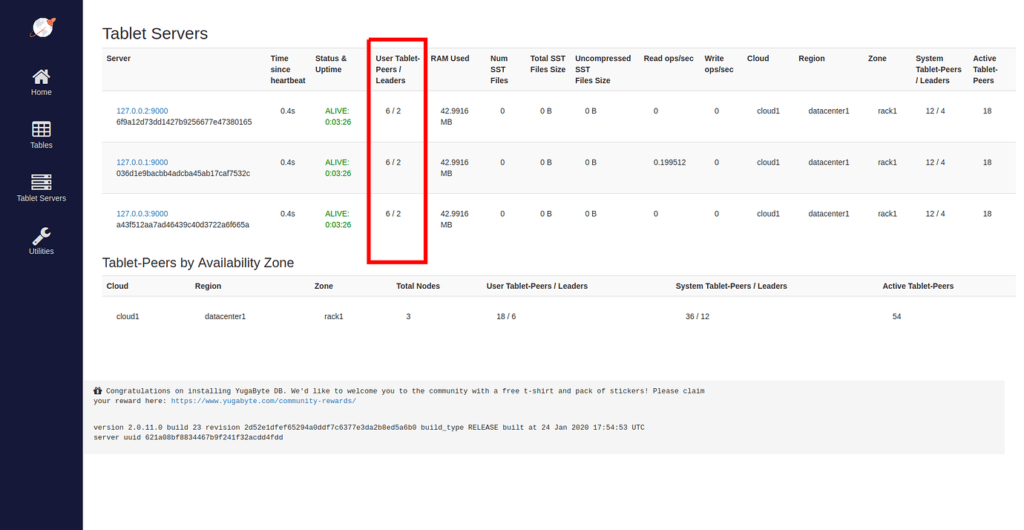
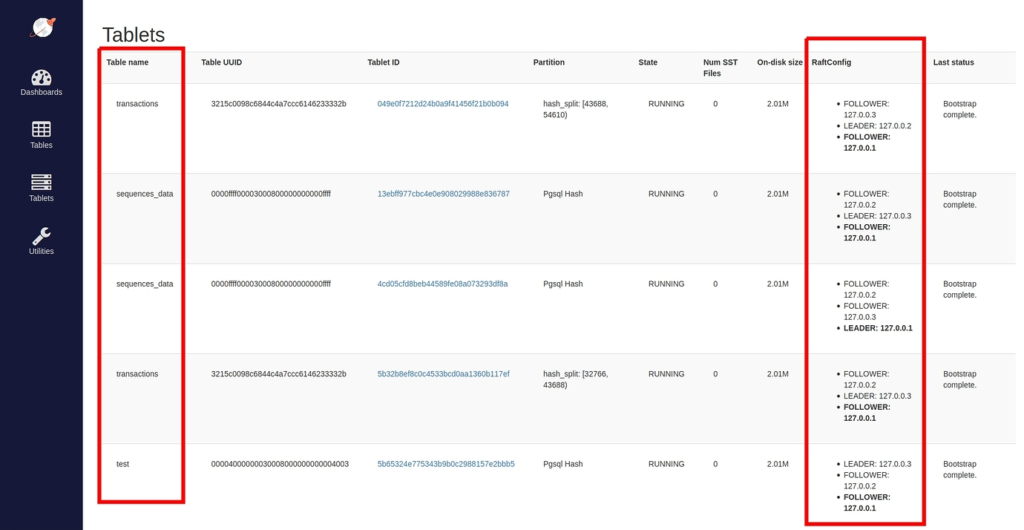
While tablet specific leaders/followers for each table are displayed on the UI in the https://<any-tserver-ip>:9000/tablets URL of each yb-tserver.
Yes, like Google Cloud Spanner, YugabyteDB supports the ability to specify a “default leader” region or a preferred set of zone/regions(s) for the leaders. This can be done with the set_preferred_zones command in the yb-admin cli. As long as nodes are alive and healthy all tablet leaders will reside in that region/zone.
New Documentation, Blogs, Tutorials, and Videos
New Blogs
- Developing Reactive Microservices with Spring Data and Distributed SQL
- Natural versus Surrogate Primary Keys in a Distributed SQL Database
- Distributed SQL vs. NewSQL
New Videos
- How to Get Started with Distributed SQL on Google Kubernetes Engine
- Developing Microservices with the Google Hipster Demo, Istio, and a Distributed SQL Database
- Developing Cloud-Native Spring Microservices with a Distributed SQL Backend
New and Updated Docs
- Benchmark YugabyteDB (reorganized)
- TPC-C (YSQL)
- YCSB (YSQL and YCQL)
- Key-value workload (YCQL)
- Large datasets (YCQL)
- Scaling queries (YSQL and YCQL)
- Jepsen testing (YSQL)
Upcoming Conferences
- Postgres Conference, March 23-27, 2020, New York
- KubeCon + CloudNativeCon Europe, March 30 – April 2, 2020, Amsterdam
- Google Cloud Next, April 6-8, 2020, San Francisco
- Red Hat Summit, April 27-29, 2020, San Francisco
Get Started
Ready to start exploring YugabyteDB features? Getting up and running locally on your laptop is fast. Visit our quickstart page to get started.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


