Transforming the Omnichannel Experience at Kroger
November 20, 2020
At the Distributed SQL Summit, Mahesh Tyagarajan – VP Engineering, Kroger – presented the talk “Technology Strategy and Transformation”. The talk focused around the technology infrastructure, current challenges, and the need faced by Kroger to transform its technology stack.
Kroger is as big as retail gets
Kroger is the largest supermarket in the US, 2nd largest retailer in the US, and the 5th largest in the world, with roughly 3000 stores operating across 42 states. Kroger operates a multi-format, multi-banner strategy, including fuel, jewelry, pharmacies, and grocery stores, along with digital channels. Additionally, Kroger operates on the manufacturing side of the supply chain with 18 dairy plants, 9 bakeries, and 7 grocery plants.
Use cases and pain points
Kroger is faced with a rapidly changing retail environment, including fast-growing digital channels where demand has spiked even further due to COVID-19. Also because there is a mix of physical stores and plants, paired with e-commerce outlets, several different components and modalities converge to make an order come to life. The interplay between digital and physical requires a lot of technology systems that need to come together to create a smooth, streamlined customer experience. As Kroger continues to scale, it is turning to a microservices-based, hybrid cloud architecture to serve customers now and well into the future.
It is not hard to imagine that the challenges that Kroger is facing are likely very similar to ones faced by other well-established retailers worldwide. These include an aging tech stack, too many disparate point solutions, and an increasing number of ways customers can browse, purchase, and have their orders fulfilled.
The time for technical transformation is now

Next, Mahesh walked us through how Kroger is thinking about and executing on their digital transformation strategy.
- A hybrid model that could have workloads on-prem, at the edge in stores and public cloud.
- Adopting microservices and moving to the cloud to better address scalability, availability, reliability, and observability concerns, while benefiting from cost savings.
- Focus on APIs and frameworks to reduce re-writes and operational costs.
Why Kroger chose YugabyteDB
Specifically, in regards to data infrastructure, Mahesh talked about the necessary characteristics they needed from their database technology that YugabyteDB was able to address.
- Support for both SQL and NoSQL workloads
- Support for distributed ACID transactions
- Ability to automatically geo-distribute data
- Auto-sharding capabilities
- Open source with commercial backing
YugabyteDB deployments at Kroger
At the conclusion of the talk, Mahesh walked us through two topologies of YugabyteDB deployments at Kroger. The first deployment is a geo-distributed deployment spread across three regions.
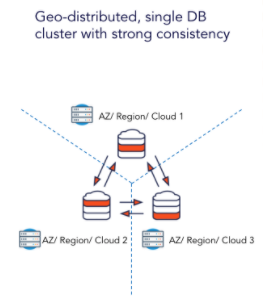
The second one involves asynchronous replication between two YugabyteDB clusters across regions.
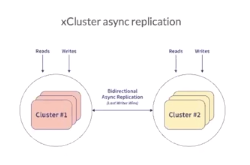
Ultimately, YugabyteDB plays a key role in enabling microservices and digital transformation at Kroger. Because YugabyteDB is able to deliver single digit millisecond latencies at the data tier, coupled with its fault tolerant design, it is proving to be a solution that could be used in other use cases at Kroger.
Learn More About Kroger’s Omnichannel Transformation
- How Kroger’s Data Architecture Powers Omnichannel Retail Experiences at Scale
- How Kroger Enhances Customer Experience with Omnichannel Optimization
How a Modern Data Layer Powers Omnichannel Success
 Master omnichannel success with YugabyteDB, and discover how top retailers optimize operations, diversify channels, and elevate customer experiences.
Master omnichannel success with YugabyteDB, and discover how top retailers optimize operations, diversify channels, and elevate customer experiences.


