Distributed SQL Summit Recap: Mastercard’s Cloud Native Journey to Distributed Databases
December 29, 2020
At the Distributed SQL Summit 2020, Ken Owens – Vice President, Cloud Native Engineering, Mastercard, presented the talk, “The Data Divide: An End User’s Cloud Native Journey to Distributed Databases.”
Because Ken has been working at the intersection of technology and financial services for more than 20 years, he brings a unique perspective to how cloud native and distributed systems can transform, what from the outside may appear to be a slow moving industry, but from the inside, quite the opposite.
In his talk he covered:
- What is the “Data Divide”?
- Why distributed databases are hard
- Lessons learned
- What’s next for Mastercard
What is the “Data Divide”?
As you can imagine, an organization like Mastercard, which deals with financial services data that underpins a lot of the commerce that happens on a daily basis, has taken a “divide and conquer” approach to data infrastructure. They have a database team that owns database infrastructure and operations, while the application team owns the data and schema design. Based on the use case and workload, Mastercard employs over 2,500 relational and non-relational databases running on everything from the mainframe, to bare metal, the cloud, and Kubernetes.
Why are distributed databases hard?
Ken answers this question by tackling it from two perspectives. For application developers who are primarily concerned with how they can get their code running in production, there are a variety of “review boards” that must first sign off. These can involve reviews around security, runtime, business processes, storage, dependencies, schema changes, and more.
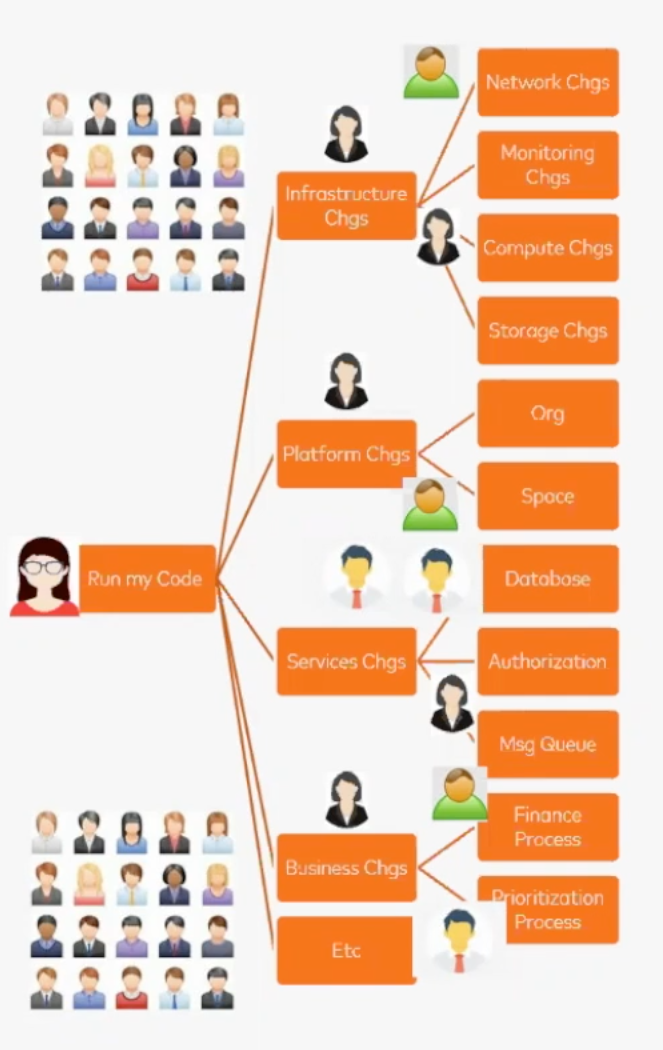
The process above is challenging enough when dealing with PostgreSQL or Oracle, and becomes even more complex for the platform and infrastructure teams when databases reside in dynamic cloud-based environments, are loose coupled, and the expectation is to support frequent, agile changes.
Lessons learned
Next, Ken covered the lessons learned in trying to reconcile the need for the effective review of code changes, while at the same time providing developers with data infrastructure that promotes faster times to production and makes the most of a cloud native environment.
- Don’t just be consumers of open source software, become contributors
- Constantly educate developers to understand and adopt the core principles of cloud native in way that stays inline with existing governance models
- Always organize development around business value and define the measurements to success
- Optimize for scale and performance
- Focus on the end user/customer experience
- Iterate, iterate, iterate
What’s next at Mastercard
In the final part of the talk, Ken discussed some of the distributed database efforts currently underway at Mastercard. They included:
- Move away from bespoke data services, to those that can be leveraged using standard APIs and data patterns
- Monitoring and logging should be fully automated and abstracted away from the application developers
- Build a “Data Service Catalog” that is constructed of patterns that can be reused in multiple operating environments including on prem or cloud
- Build a “Data Mesh” that is similar in design to a “Service Mesh” in which the data service control plane is separated from the abstracted data service models
Want to see more?
Check out all the talks from this year’s Distributed SQL Summit including Pinterest, Mastercard, Comcast, Kroger, and more on our Vimeo channel.


