Distributed SQL Databases on Kubernetes Webinar Recap
April 26, 2021
We recently presented the live webinar on how to run distributed SQL databases on Kubernetes. This session focused on the design of stateful workloads in Kubernetes, the architecture and deployment of YugabyteDB in Kubernetes, and best practices to run cloud native stateful workloads with a real-world example.
In this blog post, we provide the playback recording and slides, and recap some highlights from the presentation.
If you have additional questions about running the YugabyteDB distributed SQL database on Kubernetes, or about distributed SQL databases or designing stateful database workloads on Kubernetes in general, you can ask them on our YugabyteDB Slack channel, Forum, GitHub, Stackoverflow, or contact us on our website.
Webinar Recording and Slides
Please find the webinar recording here and embedded below, and the slides here.
Distributed SQL Databases on Kubernetes Presentation Highlights
Enterprise Adoption of Kubernetes
We kicked off the webinar by highlighting the adoption of Kubernetes in enterprise Fortune 500 companies and how Walmart, eBay, and Target have achieved business flexibility, rapid deployment, and cloud native architectures with it. We then touched upon the VMware State of Kubernetes 2020 report, which highlights the adoption of Kubernetes, its massive growth for deploying critical business workloads, and benefits to large enterprises.
Containerized data workloads running on Kubernetes offer several advantages over traditional VM / bare metal-based data workloads, including but not limited to:
- Better cluster resource utilization
- Portability between cloud and on-premises
- Self-service experience and seamlessly scale on demand during peak traffic
- Robust automation framework can be embedded inside CRDs (Custom Resource Definitions) or commonly referred to as a ‘K8s Operator’. Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop.
- Simple and selective instant upgrades and rolling upgrades with zero downtime
Introduction to Distributed SQL Databases
The presentation covered what is a distributed SQL database, further adding that distributed SQL databases:
- Support SQL features and each distributed SQL database differs in terms of the depth of the SQL features it supports
- Are resilient to failures, which means if you have deployed in the cloud and you lose a node or a zone, your distributed SQL database should be able to survive that failure automatically without manual intervention
- Are horizontally scalable, which means if you need to expand the number of nodes that you have for processing power or storage, you should be able to do so by simply adding nodes
- Are geographically distributed, which means you should be able to deploy the database in a multi-zone, multi-region, and/or multi-cloud configurations
YugabyteDB Deployment in Kubernetes
YugabyteDB was architected to support all of the above. Additionally, YugabyteDB was specifically architected as a cloud native database, which means it can run on Kubernetes, VMs, bare metal, any cloud provider, container, and data center. At the same time, the database architecture provides high performance in terms of providing both massive throughput and extremely low latency, and YugabyteDB is one hundred percent open source. The entire database, including all the enterprise features such as backups, encryption, security, and more, are made available under the Apache 2.0 license, which is one of the most permissive open source licenses out there.
Architecture
YugabyteDB uses StatefulSets to deploy the database cluster in Kubernetes. Specifically, there are two StatefulSets, which get deployed using Yugabyte Helm charts. Helm is an open source packaging tool that helps install applications and services on Kubernetes. Yugabyte Helm chart is a package containing all resource definitions necessary to create an instance of YugabyteDB, including StatefulSets – yb-masters, TabletServers (yb-tservers), headless services, and load balancers.
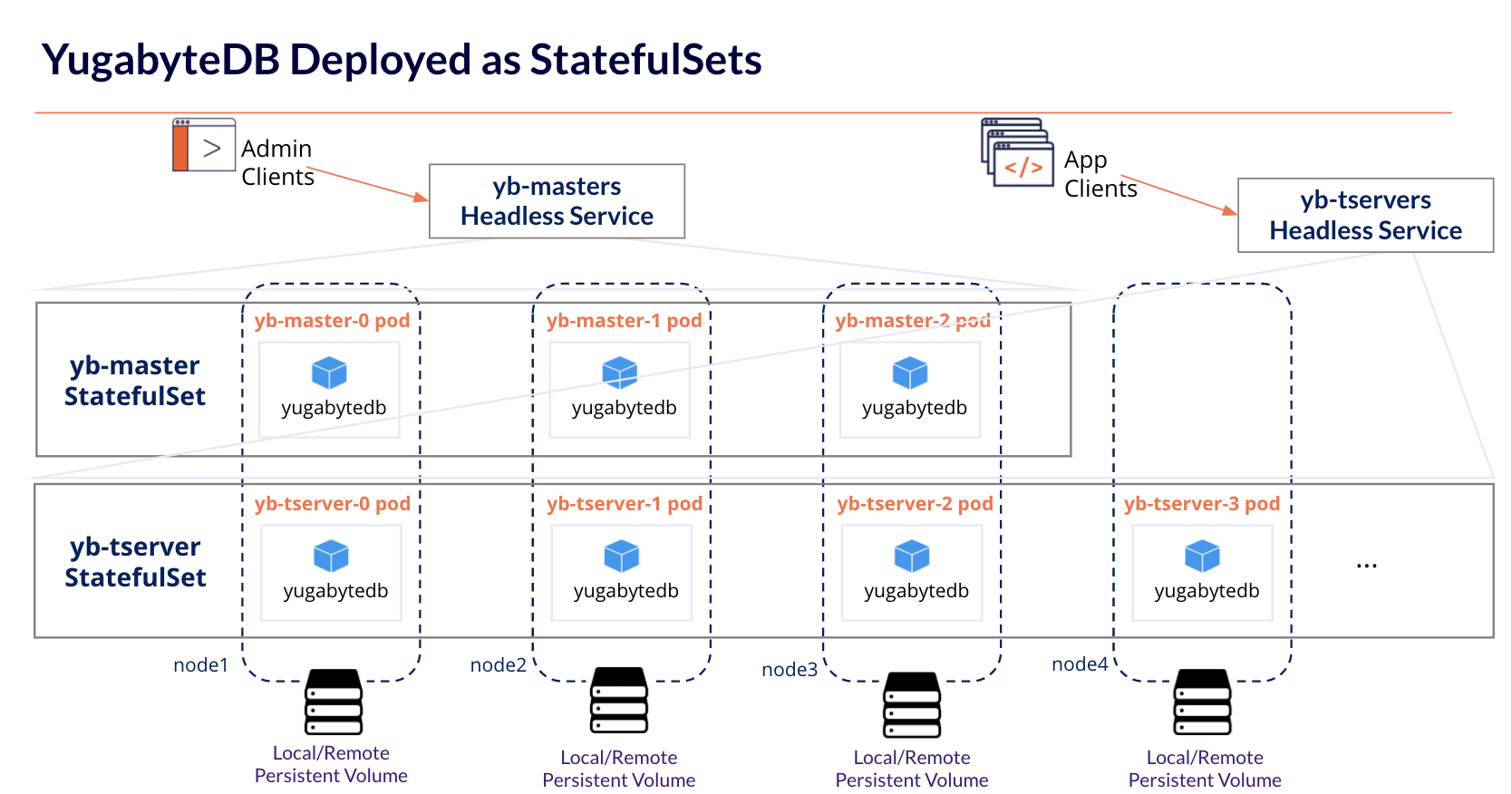
Deployment Topologies
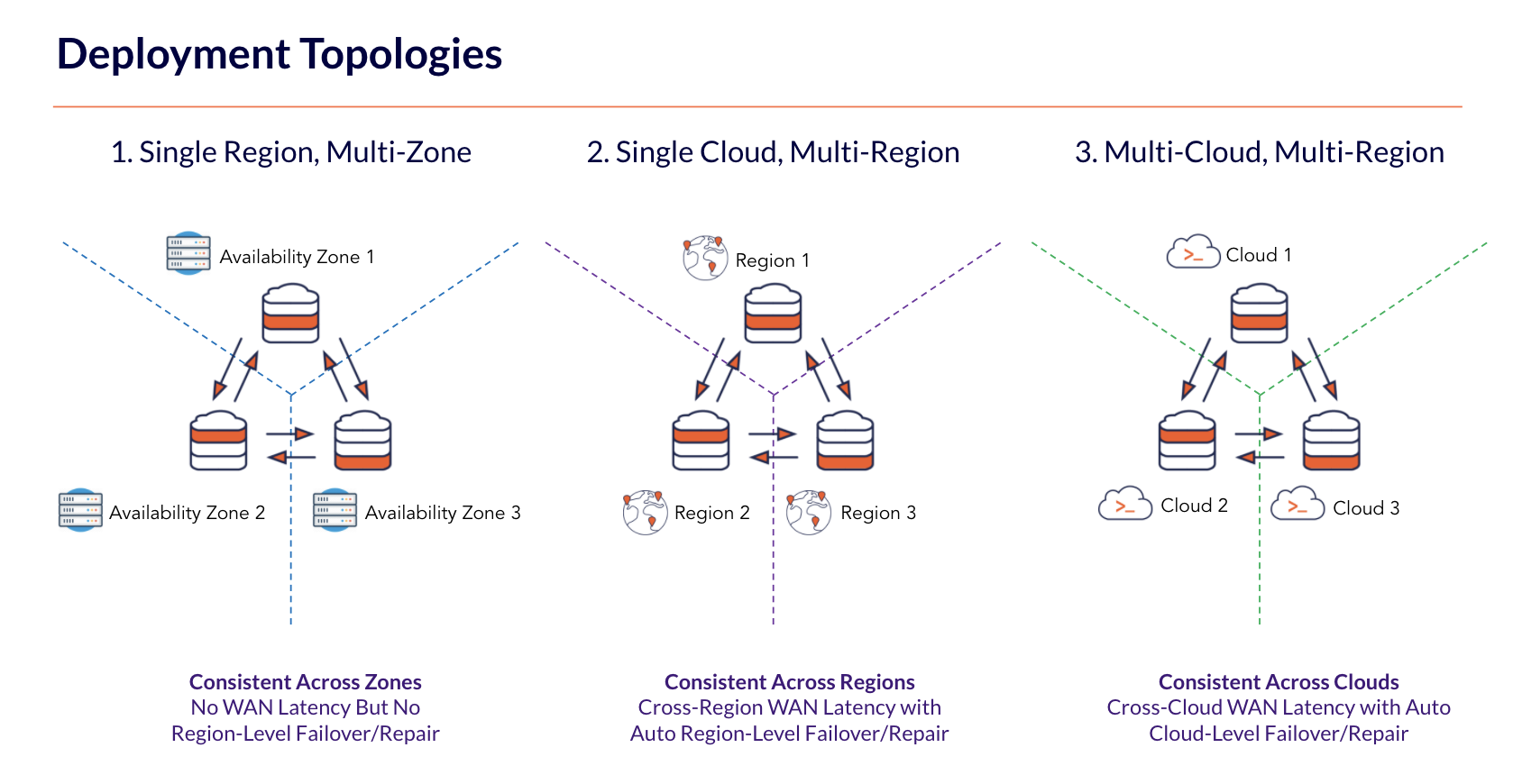
YugabyteDB can be deployed across different topologies, including Synchronous and Asynchronous Replication. The figure below shows how synchronous replication can be achieved in three configurations:
1. Single Region – Multi-Availability Zones
2. Multi-Region – Single Cloud
3. Multi-Region – Hybrid Cloud
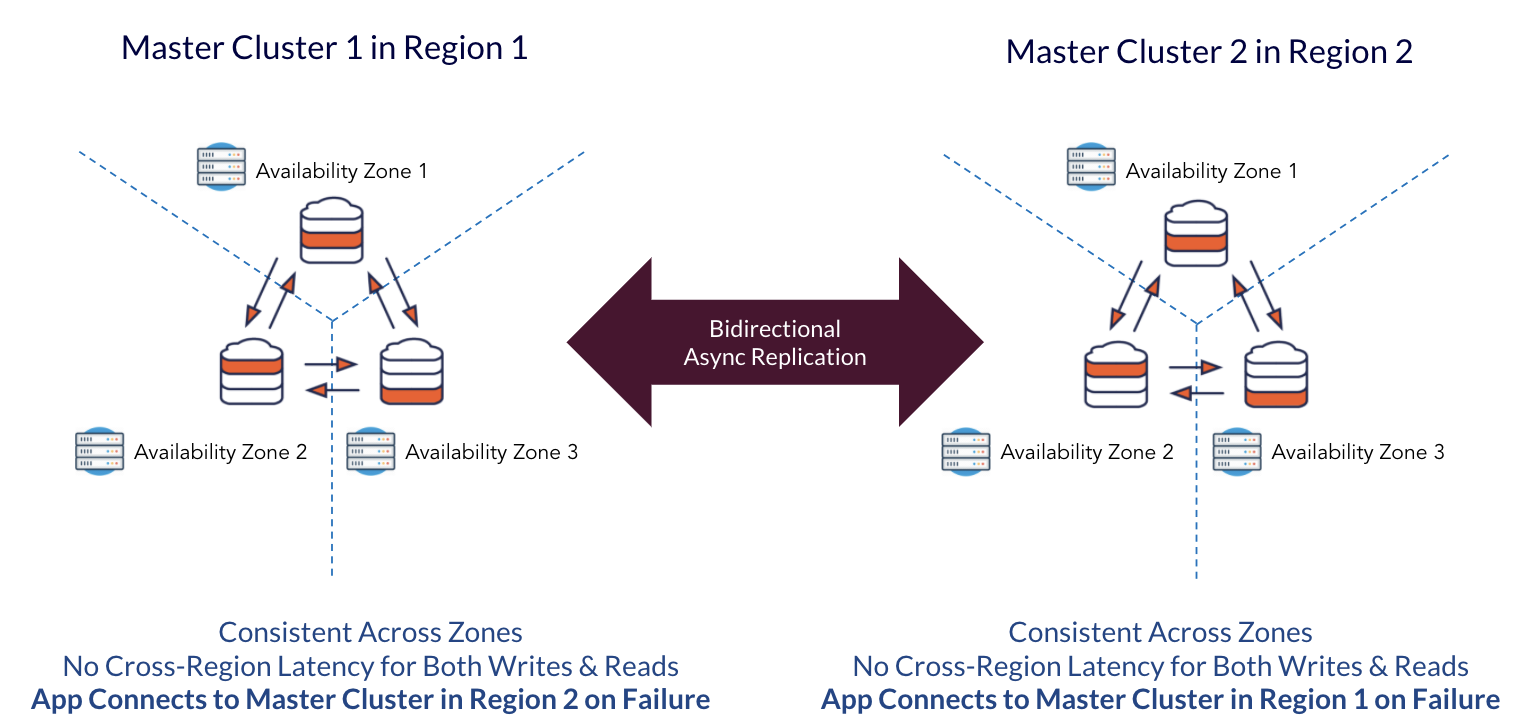
YugabyteDB can also be deployed in Asynchronous Replication topology to perform unidirectional or bidirectional data replication. The prerequisite here is that the application has to be architected to handle the downsides of unavailability of recently committed data in the master-follower configuration as well as account for potentially conflicting writes in the master-master configuration.
Deploying Yugabyte in Multi-Cluster Kubernetes Environments
Multi-cluster Kubernetes deployment is one of the hottest areas in the Kubernetes domain, especially with stateful database workloads. This webinar covered the architectural considerations and networking prerequisites required for achieving seamless deployments.
Key requirements:
- Pod to pod communication over TCP ports using RPC calls across three Kubernetes clusters
- Global DNS Resolution system across all the Kubernetes clusters so that pods in one cluster can connect to pods in other clusters
- Ability to create load balancers in each region or cluster
- Ability to assign RBAC privileges: ClusterRole and ClusterRoleBinding
Yugabyte Demo on Kubernetes
Yugabyte Platform is used to deploy YugabyteDB across any cloud anywhere in the world with a few clicks, simplify day-2 operations through automation, and get the services needed to realize business outcomes with the database. The self-service portal included in Yugabyte Platform enables developers to spin up a database for their apps in minutes by delivering a private database-as-a-service (DBaaS). It also allows you to roll software patches across your cluster with zero downtime. We provided a live demo of Yugabyte Platform in action in the webinar, which we summarize below.
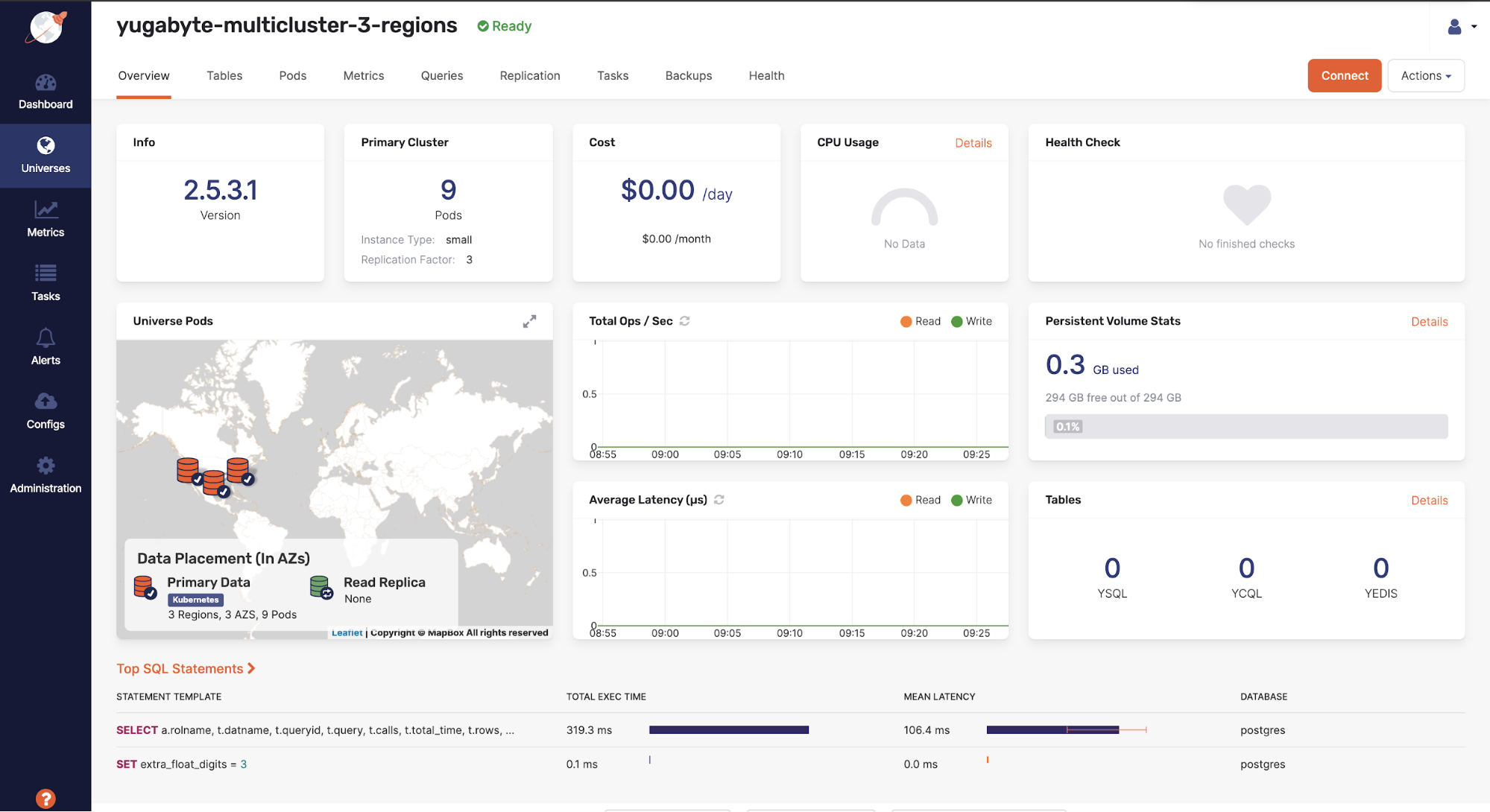
Yugabyte Platform dashboard
The Yugabyte Platform dashboard gives a quick overview of what’s currently going on with the cluster. You can see details such as the database version, the number of nodes deployed, the size of these nodes, as well as the general health of the cluster. You can also find key metrics to see the throughput and latency within the cluster, including the queries that are currently being run on the cluster.
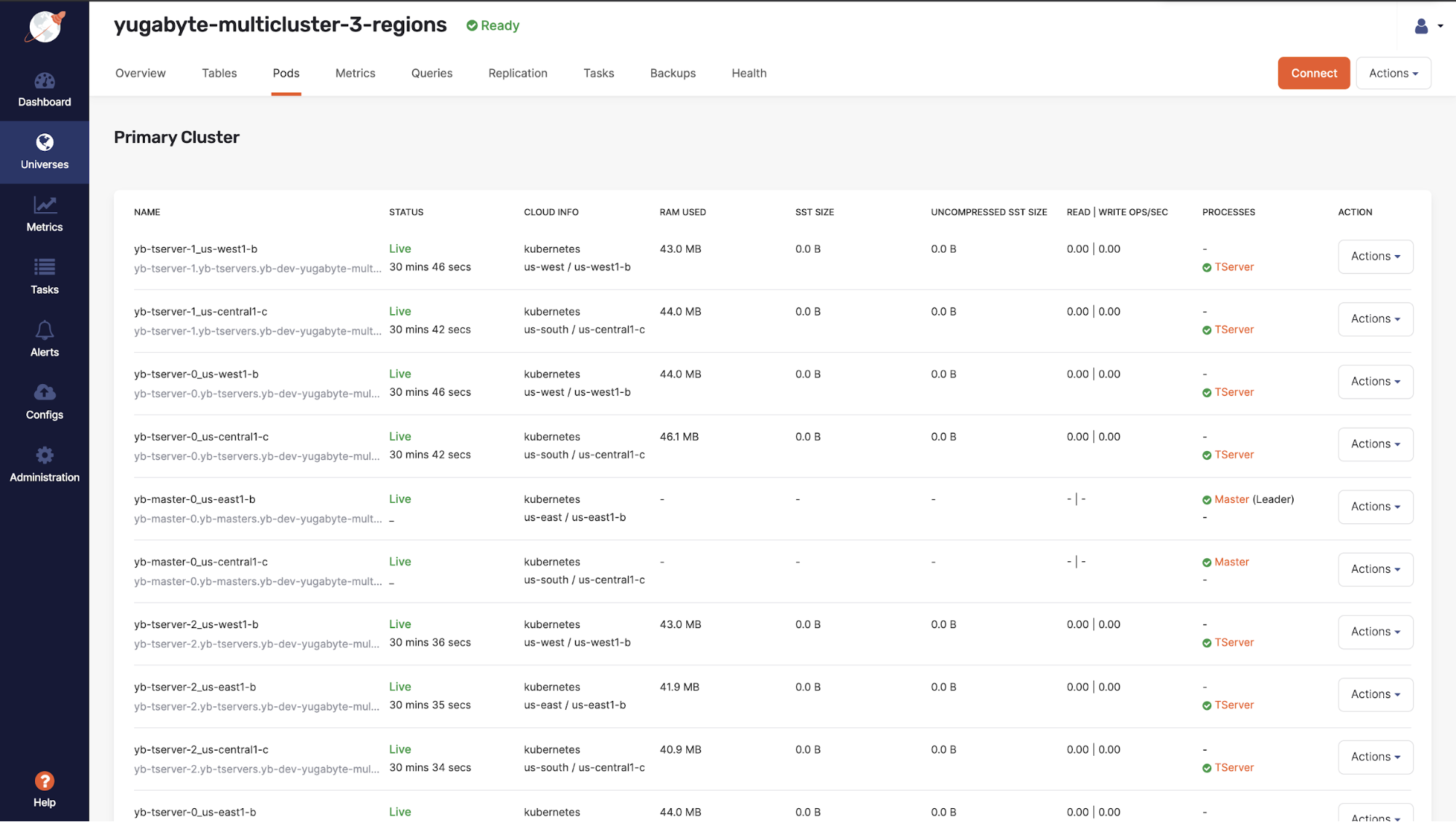
Yugabyte Platform cluster view
Above, you can see a list of the currently running nodes. When using Kubernetes as the provider, a single pod for each yb-tserver and yb-master process is deployed. The yb-master process is not directly in the read or write path. Instead, it is more of a coordinator for the Yugabyte Universe and stores all the metadata for the nodes like tablet locations, keyspaces, databases, tables, etc. The yb-tserver is the process that actually does all the heavy lifting; it handles the user data for the tables and the primary process involved in querying data.
You can also see the throughput on each of these tserver pods and the data on each node on this page. We show two different size metrics here – the sstable size and the uncompressed sstable size. We use snappy compression, which generally gives anywhere from 5 to 10x compression.
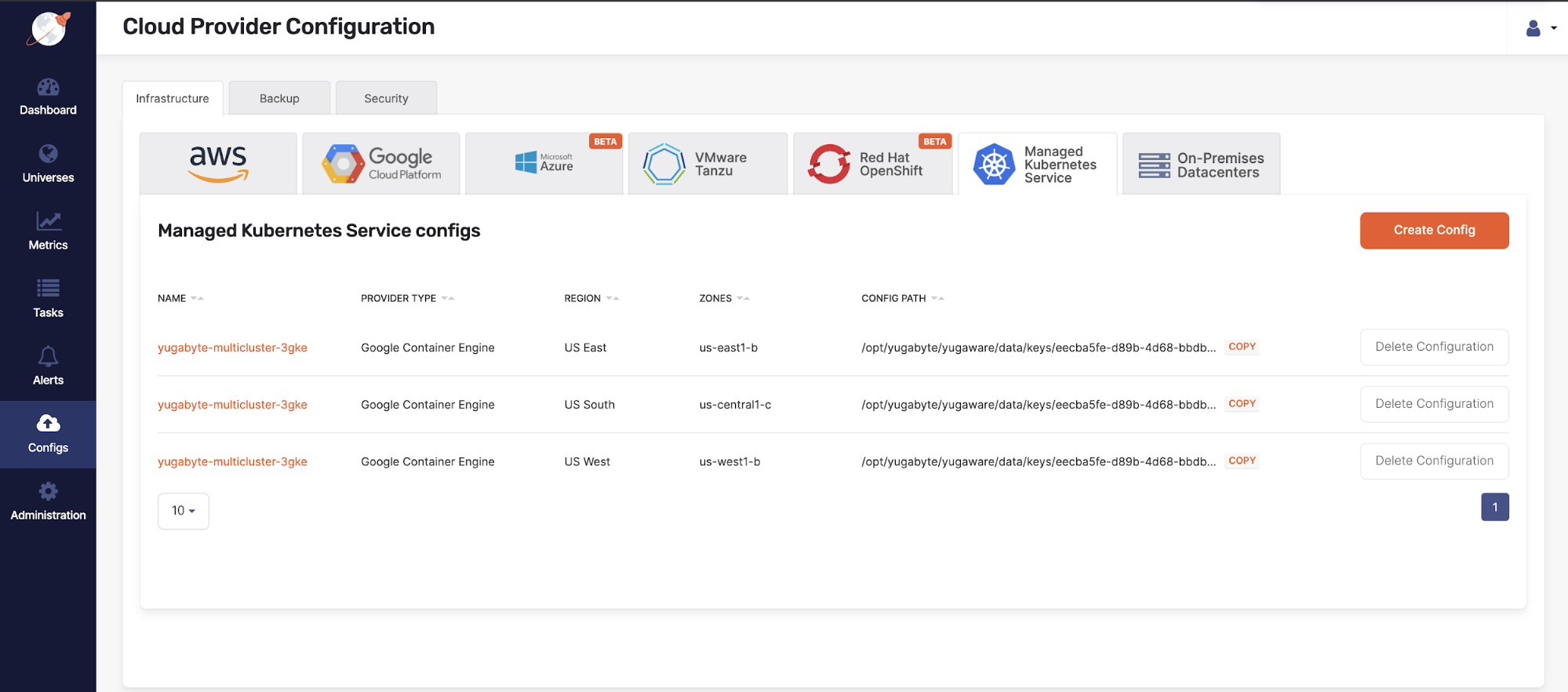
Yugabyte Platform cloud provider configuration
Here is the config section used to create the config files used by Yugabyte Platform to deploy your universes across different cloud providers. As you can see here, you are able to deploy universes across all three of the major cloud providers, as well as several Kubernetes providers. In this demo we used Google Container Engine (GKE) Kubernetes distribution. To create the config, you will need to pick one of the providers from this list of Kubernetes providers. From there you’ll need to give the config a name and upload a kube config and provide a service account that will be used to spin up the pods. We use quay.io to store our containers for both Yugabyte Platform as well as YugabyteDB. After this you can add the regions that you’d like to deploy your pods to.
In addition to Kubernetes and the major cloud providers, you can also configure Yugabyte Platform to deploy to your own on-premises data centers. What all these providers allow you to do is be cloud agnostic so you’re never tied to anyone provider and can even deploy universes across multiple providers.
In the webinar, we demonstrated a few operational scenarios, including resilience to node failures and scaling out.
Node Failure
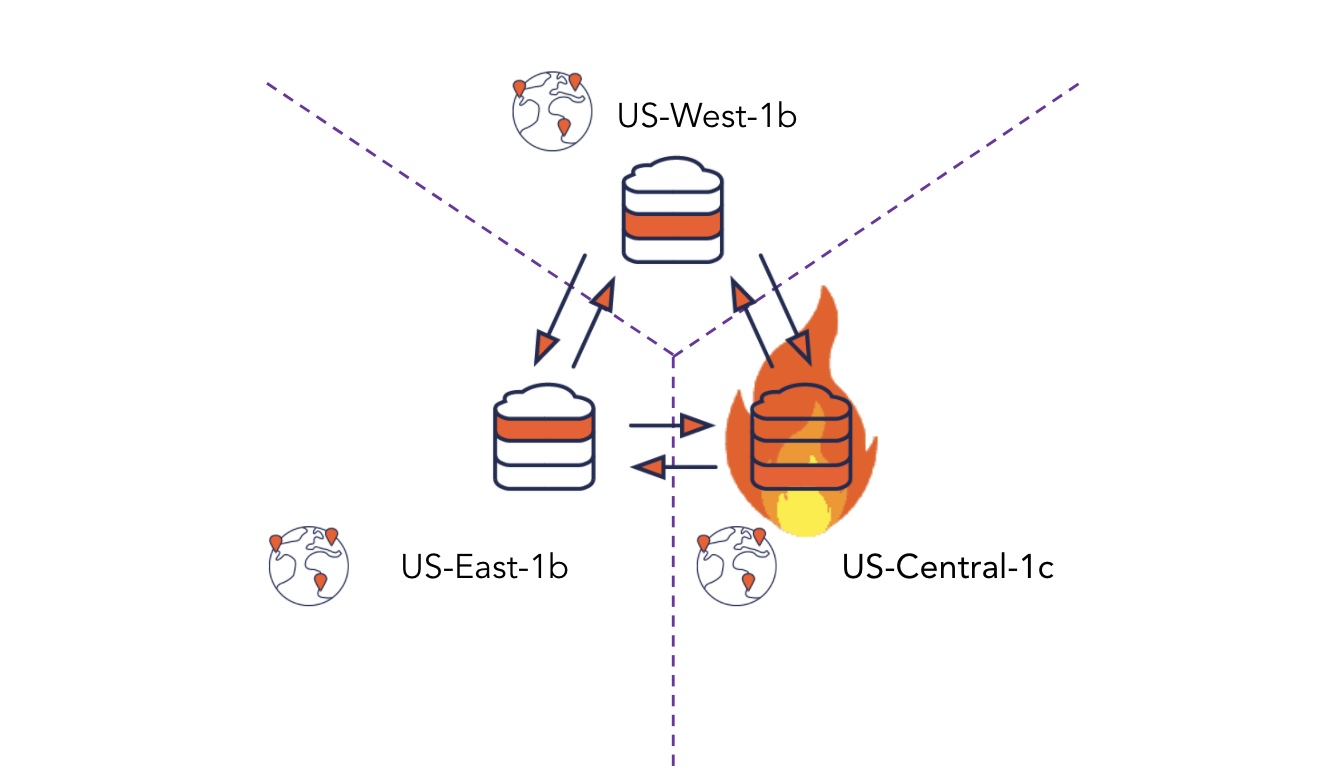
Having a node go down is a common occurrence in YugabyteDB whether it be for upgrades to the software, software patching or in extreme cases when there is an infrastructure failure of the underlying IaaS node. With many other databases this would cause major issues on the application and become an outage, but because of the YugabyteDB’s built in HA and resiliency when a node goes down there is no impact on the application.
In the demo we simulated this failure by terminating one of the running tserver pods while a workload was actively running against it. In normal deployments using VMs or bare metal servers, when a node goes down it’s up to the user to then deploy a new server and remove the downed node. Adding Kubernetes into the architecture removes all of this manual work and allows for automatic self healing within the cluster. When a pod goes down, Kubernetes will see that it’s dead and automatically spin up a new pod in its place in seconds, which removes any need for manual intervention.
Scaling the YugabyteDB Cluster
Yugabyte Platform allows you to seamlessly add new nodes to the universe without any impact to your application. In fact, the moment that a node is added to a universe you start to see the benefit from that node. This is because the moment a new node gets its first tablet, it is able to start servicing queries for the data that resides in this tablet and YugabyteDB is able to move the data for the tablets much faster than the normal streaming of data. It’s for these reasons we see the immediate benefit when new nodes are added. Now let’s go through what exactly it looks like on the tserver level when a node is added.
In Figure 1 we have the cluster in what is called steady state, where there is no movement of the tablets or data and the tablet leaders are balanced across the tservers.
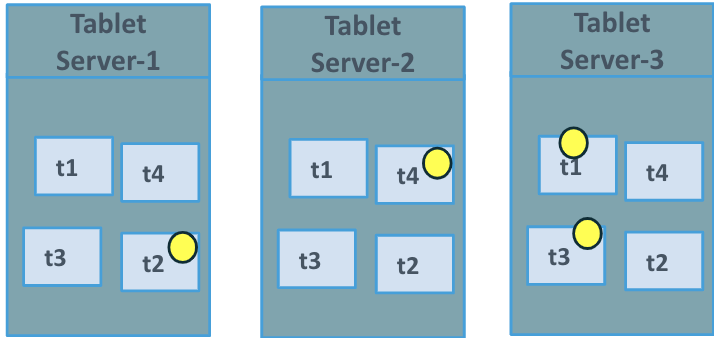
Figure 1. Pre Node Add Steady State
Now in Figure 2 we can see that the new tablet server “Tablet Server-4” is being added to the universe and the other tablet servers recognize it as part of the cluster.
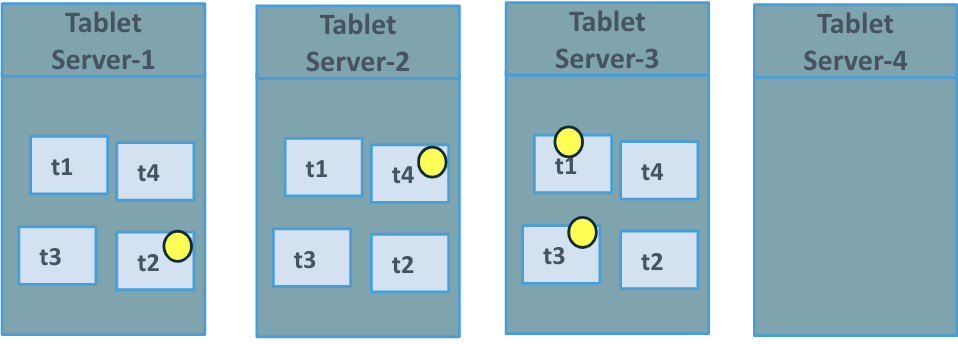
Figure 2. Start of Node Add
In Figure 3 we see the first tablet has been copied over to tablet 4. As you can see it has actually taken over as the leader to tablet 2 and will start to service the reads and writes for that tablet.
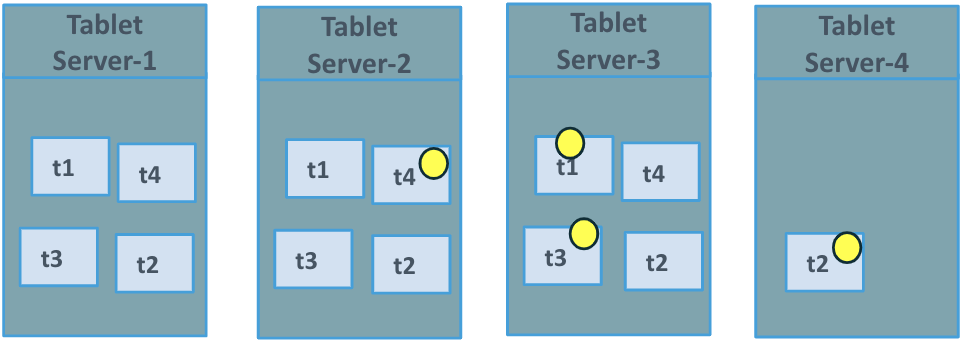
Figure 3. Tablet Data Movement
Finally in Figure 4 we see that the universe has gotten back to a steady state where all the tablets have been balanced out and no further data movement is occurring.
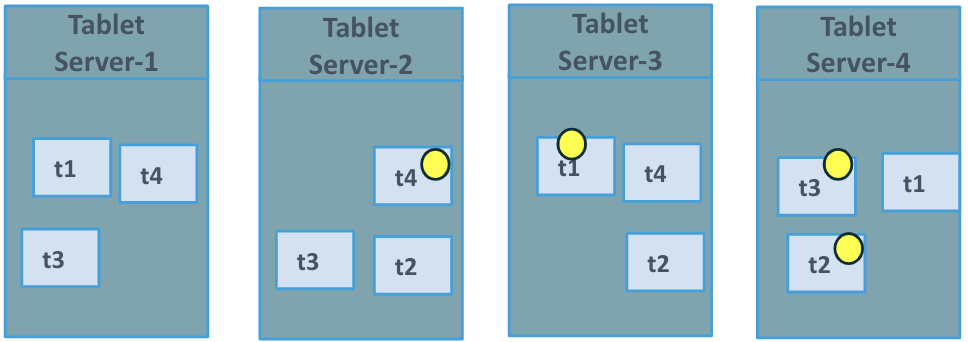
YugabyteDB does a fantastic job at horizontal scaling; it’s quick, easy, and you immediately get the benefits of the new node when it starts to join the cluster. When you combine that with Kubernetes infrastructure, you get a system that can easily spin up new nodes (pods) without the burden of needing to provision new machines. This is just one example of what makes running YugbabyteDB on Kubernetes great.
Cloud Native Microservices Application Demo
We also presented a real-world demo with an e-commerce application, including Spring Boot microservices, React.JS on the frontend, Istio for traffic management, Apache Spark for analytics, and YugabyteDB as the transactional database.
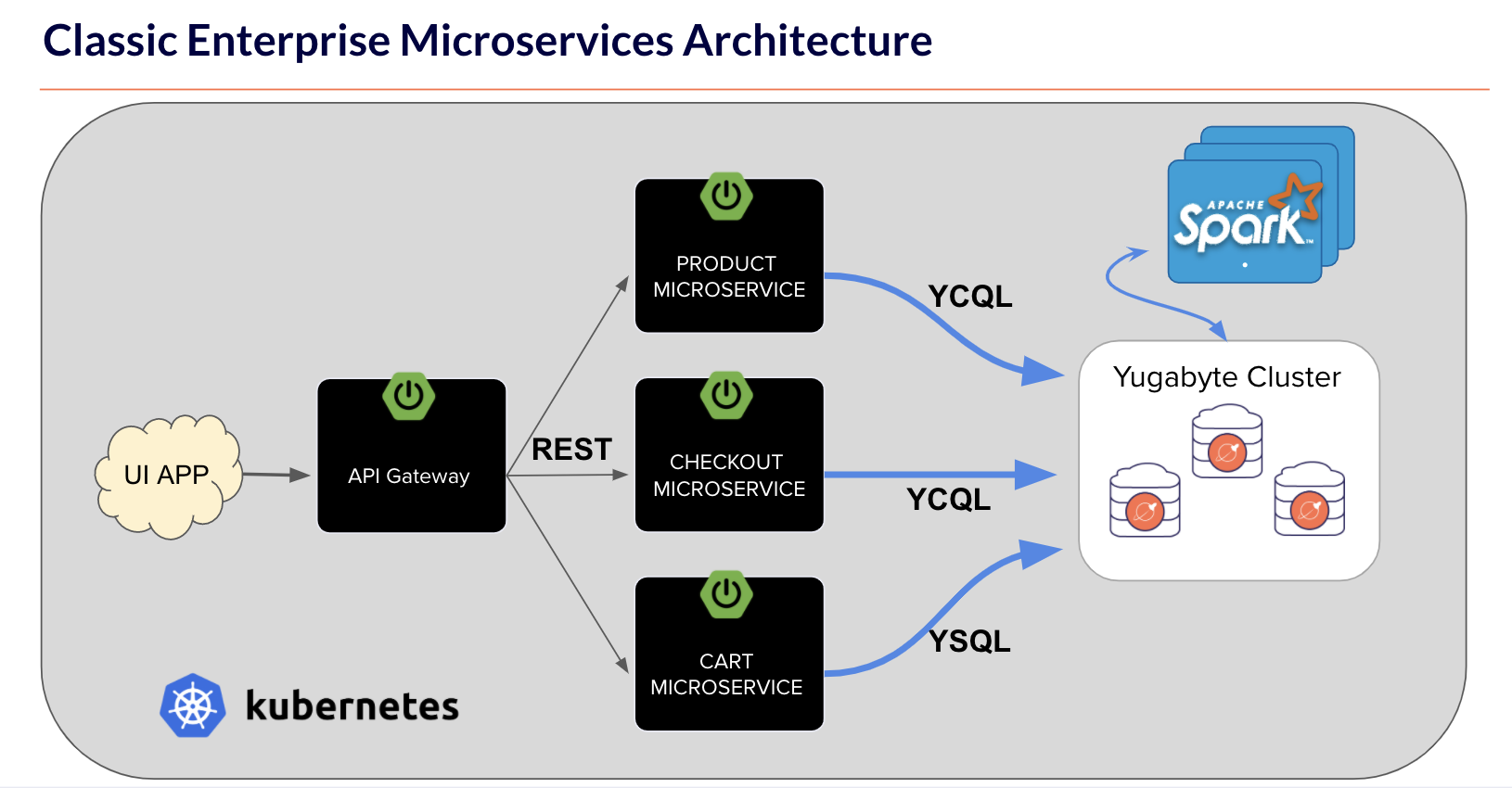
The complete tech stack we demonstrated is cloud native, is architected to simulate a real world microservices environment, and enables us to show how the different components in the stack – from the stateless microservices to the stateful database – can scale linearly without any downtime and how with YugabyteDB multi-region deployments, databases and applications are fault tolerant against region outages. The entire application with sample dataset is available in this GitHub repository: https://github.com/yugabyte/yugastore-java
What’s Next?
As a quick reference, you can find the playback of the webinar recording here and the slides here. In addition, we are building a hands-on Yugabyte Kubernetes workshop that will be available soon, as well as a new blog on YugabyteDB multi-cluster Kubernetes deployments. Stay tuned!


