Distributed PostgreSQL on a Google Spanner Architecture – Storage Layer
March 18, 2019
In this post, we’ll dive into the architecture of the distributed storage layer of YugabyteDB, which is inspired by Google Spanner’s design. Our subsequent post covers the Query Layer, where the storage layer meets PostgreSQL as the SQL API. Finally, here is a follow-up post that highlights the key technical challenges we faced while engineering a distributed SQL database like YugabyteDB.
Logical Architecture
YugabyteDB is comprised of two logical layers, each of which is a distributed service that runs on multiple nodes (or pods in case of Kubernetes).
Yugabyte Query Layer (YQL) forms the upper layer of YugabyteDB that applications interact with using client drivers. YQL deals with the API specific aspects (such as query compilation, data type representations, built-in functions and more). It is built with extensibility in mind, and supports two APIs, namely Yugabyte SQL or YSQL (PostgreSQL compatible) and Yugabyte Cloud QL or YCQL (with Cassandra QL roots).
DocDB, a Google Spanner-inspired high-performance distributed document store, serves as the lower layer. It offers strong consistency semantics including single-row linearizability as well as multi-row ACID transactions (with snapshot isolation currently and serializable isolation in the near future). It is highly resilient to various kinds of failures, having successfully undergone Jepsen testing recently (stay tuned for an official announcement soon).
Why Google Spanner as Inspiration for DocDB?
To power its geo-distributed, random access OLTP workloads (think Gmail, Calendar, AdWords, Google Play, and more), Google built Spanner, arguably the world’s first globally consistent database. Even though it was first introduced to the world in 2012 as a design paper, work on Spanner started much earlier in 2007. Initially, Spanner offered only a key-value API along with support for distributed transactions, external consistency, and transparent failover across data centers. Since then it has evolved into a globally-distributed, SQL-based RDBMS that today underpins almost every mission-critical service at Google. A subset of the Spanner system was made publicly available in 2017 on the Google Cloud Platform as a proprietary managed service called Google Cloud Spanner.
DocDB’s sharding, replication, and transactions designs are inspired by the designs outlined in the Spanner papers. The most important benefit of this choice is that no single component of the database can become a performance or availability bottleneck for geo-distributed, random access SQL-based OLTP workloads. Transactional database designs proposed in other papers such as Yale’s Calvin, Amazon’s Aurora, and Google’s Percolator cannot guarantee this benefit. The single global consensus leader used for transaction processing in Calvin can itself become the bottleneck. Additionally, critical SQL constructs such as long-running session transactions and high-performance secondary indexes are not possible in Calvin. Amazon’s Aurora uses a monolithic SQL layer on top a distributed storage layer, thus suffering from lack of horizontal write scalability. And finally, Google’s primary rationale for building Spanner was to address the lack of low-latency distributed transactions in Percolator.
How DocDB Works?
Data in DocDB is stored in tables. Each table is composed of rows, each row contains a key and a document. DocDB is built around 4 major design principles. As highlighted in the previous section, the first 3 are inspired by the Spanner architecture while the final principle is key to ensuring a high-performance and flexible storage system.
- Transparent sharding of tables
- Replication of shard data
- Transactions across shards (aka Distributed transactions)
- Document-based persistence of rows
Transparent Sharding of Tables
User tables are implicitly managed as multiple shards by DocDB. These shards are referred to as tablets. The primary key for each row in the table uniquely determines the tablet that the row lives in. There are different strategies for partitioning the data into tablets, a couple are outlined below.
Hash-based data partitioning scheme computes partition id for each row. This is achieved by computing a hash value of the primary key columns (or a subset thereof) of the table. This strategy results in an even distribution data and queries across a cluster of nodes. It is ideal for applications requiring low latencies, high throughput and to deal with large datasets. However, this scheme does not work well for range queries, where applications want to list all keys or values between a lower and an upper bound.
You can see an example of this partition scheme in the figure below. The partition that each row falls into is denoted by a unique color. Thus, we are partitioning the 7 row table below into 3 tablets, each row falling into a random partition.
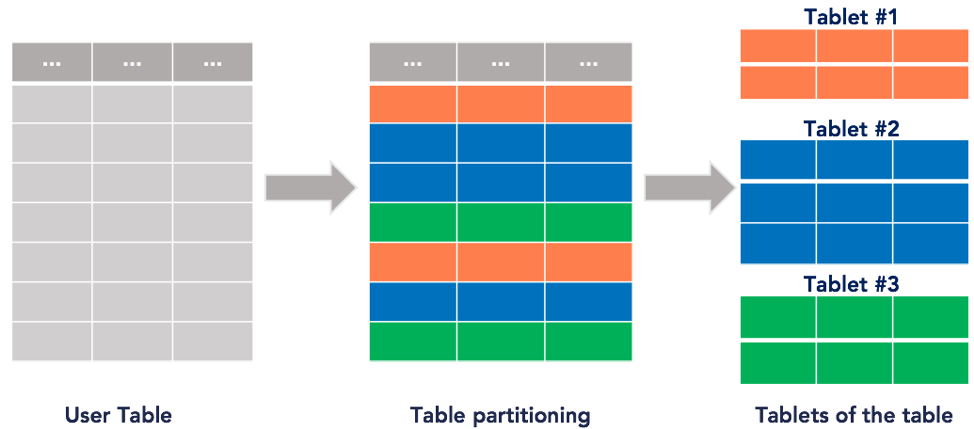
Hash-based data partitioning
Range-based data partitioning scheme partitions the table in the natural order of the primary key. This strategy allows applications to perform efficient range queries, where the applications wants to look up all values between a lower and an upper bound. However, this scheme may result in an uneven split of the data, which needs frequent dynamic re-partitioning of tablets. Further, depending on the access pattern, this scheme may not be able to balance queries across all nodes evenly.
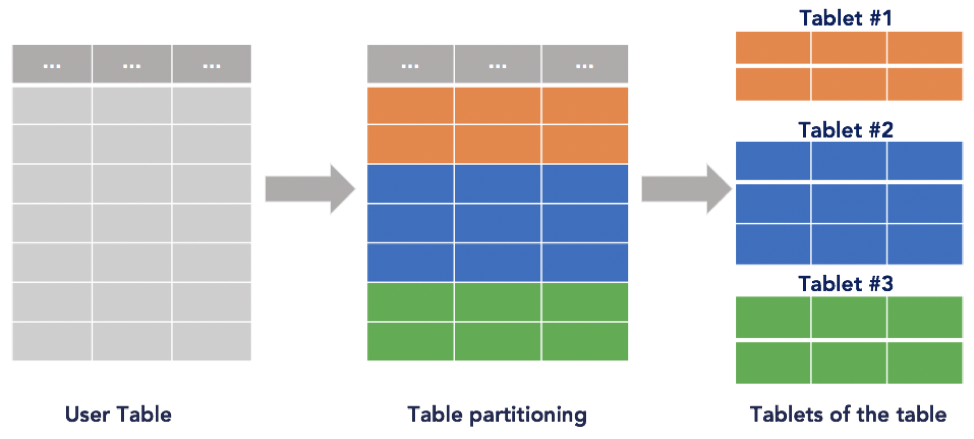
Range-based data partitioning
DocDB currently supports both hash partitioning and range partitioning. See the hash and range sharding in YugabyteDB documentation for more details.
Replication of Shards – Single-Row Linearizability
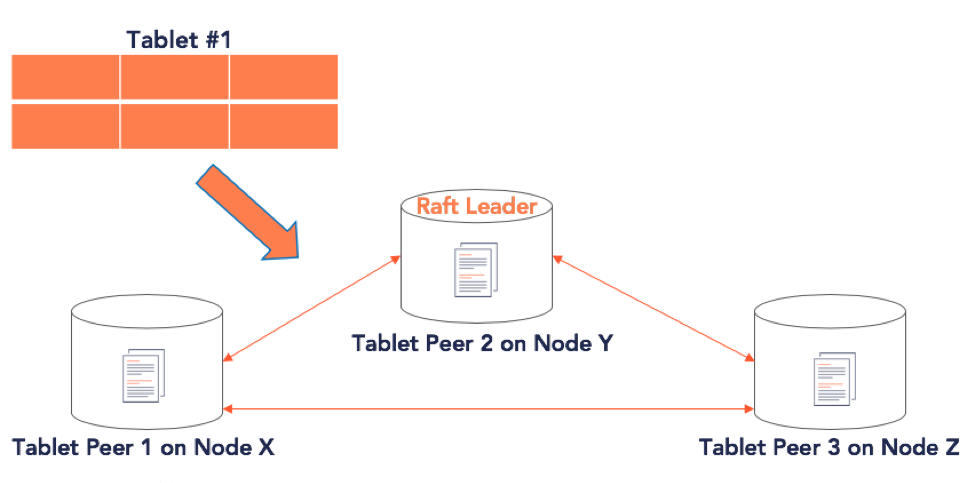
DocDB replicates the data in each tablet across multiple nodes, making the tablets fault tolerant. Each replica of a tablet is called a tablet peer. Fault tolerance (or FT) is the maximum number of node failures a tablet can survive while continuing to preserve correctness of data. The replication factor (or RF) is the number of copies of data in a YugabyteDB universe. FT and RF are highly correlated – to survive k faults, the RF should be configured to 2k+1.
As a strongly consistent database core, DocDB’s replication model makes single-key updates linearizable even in the presence of failures. Linearizability is one of the strongest single-key consistency models, and implies that every operation appears to take place atomically and in some total linear order that is consistent with the real-time ordering of those operations.
Tablet data is replicated across the various tablet-peers using a distributed consensus algorithm. A consensus algorithm allows a set of machines to agree on a sequence of values even if some of those machines may fail. Raft and Paxos are well known distributed consensus algorithms and have been formally proven to be safe. Spanner uses Paxos. However, we chose Raft since it is easier to understand than Paxos and offers critical features like the ability to dynamically change membership.
Leader Leases
The most straightforward way to implement a fault-tolerant distributed storage system would be to implement it as a Replicated State Machine over one of the distributed consensus algorithms discussed above. Every operation on the state machine would go through the consensus module to ensure that all the replicas of the state machine agree on the operations and the order in which they would be applied.
Most practical systems (examples: Paxos Made Live and Paxos Made Simple) however, do slightly better by only requiring write operations to go through the consensus module, while allowing read operations to be served by the leader of the Raft group, which would be guaranteed to have all the up to date values. Since different peers in the Raft group could possibly be operating in different terms (with different leaders) it is possible that multiple peers could consider themselves to be the leader (for different terms) simultaneously. To ensure that the system is only allowed to read the value from the leader corresponding to the latest term, Raft paper suggests that the leader – before responding to a read operation – shall communicate with a majority of peers to confirm leadership for the latest term.
The main disadvantage of this approach is that read performance may suffer, especially in geo-distributed clusters. YugabyteDB overcomes this performance limitation by using Leader Leases, which is an alternative way to ensure that reads will only be served by the latest leader. This ensures that you can read data from the leader without round-trips to any of the other nodes. The leader lease mechanism guarantees that at any point in time there is at most one server in any tablet’s Raft group that considers itself to be an up-to-date leader that is allowed to serve consistent reads or accept write requests. In other words, without leader leases, stale reads can occur since an old leader that got partitioned away may serve a consistent read request thinking it still is the leader.
With leader leases, a newly elected leader cannot serve reads (or accept writes) until it has acquired a leader lease. During a leader election, a voter must propagate the longest remaining duration time of an old leader known to that voter to the new candidate it is voting for. Upon receiving a majority of votes, the new leader must wait out the old leader’s lease duration before it considers itself as having the lease. The old leader, upon the expiry of its leader lease, steps down and no longer functions as a leader. The new leader continuously extends its leader lease as a part of Raft replication.
Note that leader leases do not rely on any kind of clock synchronization or atomic clocks, as only time intervals are sent over the network. Each server operates in terms of its local monotonic clock. The only two requirements to the clock implementation are:
- Bounded monotonic clock drift rate between different servers. E.g. if we use the standard Linux assumption of less than 500µs per second drift rate, we could account for it by multiplying all delays mentioned above by 1.001.
- The monotonic clock does not freeze. E.g. if we’re running on a VM which freezes temporarily, the hypervisor needs to refresh the VM’s clock from the hardware clock when it starts running again.
Transactions Across Shards – Multi-Row Distributed Transactions
Distributed ACID transactions modify multiple rows in more than one shard. DocDB supports distributed transactions, enabling features such as strongly consistent secondary indexes and multi-table/row ACID operations.
Let us take an example and look at the architecture in the context of this example. Below is a simple distributed transaction that updates two keys, k1 and k2.
BEGIN TRANSACTION
UPDATE k1
UPDATE k2
COMMIT
We already know from the previous sections that (in the general case) these keys could belong to two different tablets – each of which has its own Raft group that could live on a separate set of nodes. So the problem now boils down to updating two separate Raft groups atomically. Updating two Raft groups atomically requires that the leaders of the two Raft groups (which accept the writes and reads for these keys) agree on the following:
- Make the keys readable to the end user at the same physical time
- Once the write operation is acknowledged as a success, the keys should be readable
Note that we are not yet talking about handling conflicts, which are overlapped partial updates from another transaction.
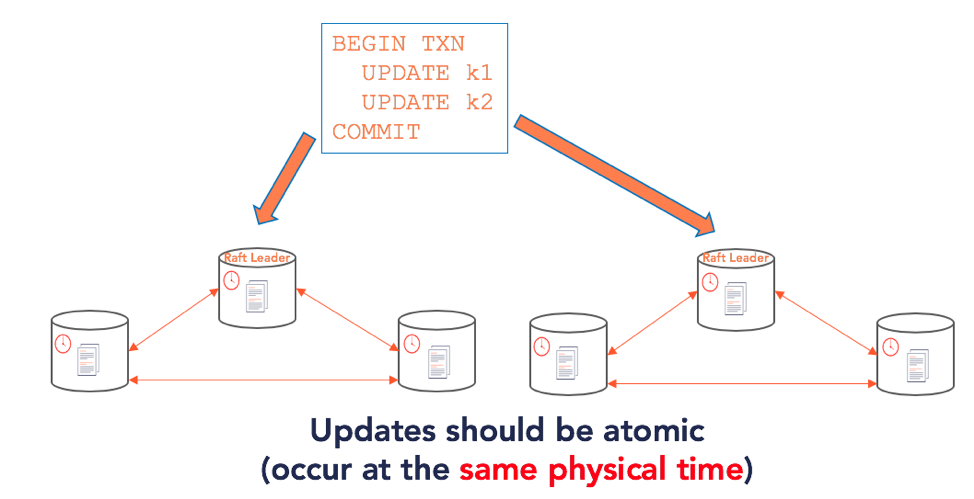
Making an update across two nodes at the same physical time requires a clock that can synchronize time across nodes, which is not an easy task. TrueTime, used by Google Spanner, is an example of a highly available, globally synchronized clock with tight error bounds. However, such clocks are not available in many deployments. Regularly available physical time clocks cannot be perfectly synchronized across nodes and hence cannot provide ordering across nodes.
Removing the Need for TrueTime with Raft & Hybrid Logical Clocks (HLC)
Instead of TrueTime, DocDB uses a combination of Raft operation ids and Hybrid Logical Clocks (HLC). HLC combines physical time clocks that are coarsely synchronized (using NTP) with Lamport clocks that track causal relationships. Each node in the cluster first computes its HLC. HLC is represented as a (physical time component, logical component) tuple as shown in the figure below. The finer grained ordering of events within a coarsely synchronized physical time interval is achieved with a monotonically increasing counter.

Once HLCs are available on each node, DocDB exploits the fact that Raft operation ids and HLC timestamps (both of which are issued by the tablet leader) are strictly monotonic sequences. Thus, YugabyteDB first establishes a one to one correlation between the Raft operation id (comprised of a term and an index) and the corresponding HLC at that time on that tablet’s Raft leader (comprising of a physical time component and a logical component) by writing both values against each entry into the Raft log.
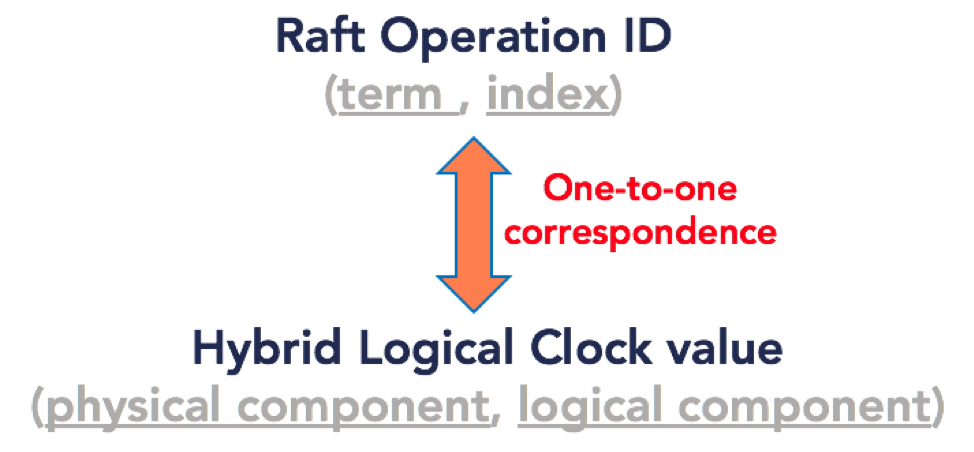
Thus, the HLC can be leveraged as a proxy for the Raft operation id. The HLCs in a cluster act as a distributed, global clock that is coarsely synchronized across independent Raft groups. This would not be possible with just Raft operation ids. Thus, we now have a notion of physical time that independent nodes can agree on.
The second part of the problem is when the nodes should serve reads. This is accomplished by using the HLC is to track the read point as well. The read point determines which updates should be visible to end clients. In the case of single-row updates, the leader issues the update an HLC value. An update that has been safely replicated onto a majority of nodes as per the Raft protocol can be acknowledged as successful to the client and it is safe to serve all reads up to that HLC. This forms the foundation for multi-version concurrency control (MVCC) in DocDB.
For distributed transactions, nodes write a transaction record in the pending state and provisional records. This is covered in detail in a separate post on how distributed transactions work in YugabyteDB. When the transaction record gets updated to the committed state, the transaction will be assigned a commit HLC. When that HLC value becomes safe to serve to clients, the transaction becomes visible to end clients atomically. Note that the exact algorithm to determine the safe time up to which reads can be served is more involved, and is a topic for an entirely new post by itself.
Document-based Persistence of Rows
In the previous section, we looked at how the data in each tablet is replicated with strong consistency while being fault tolerant. The next step is to persist it in each tablet peer’s local document store in a manner that is highly efficient for reads and writes. DocDB local store uses a highly customized version of RocksDB, a log-structured merge tree (LSM) based key-value store. We enhanced RocksDB significantly in order to achieve scale and performance.
How exactly does a document get persisted in DocDB? Let us take an example document as shown below.
DocumentKey1 = {
SubKey1 = {
SubKey2 = Value1
SubKey3 = Value2
},
SubKey4 = Value3
}In this example, the document key, called the DocKey has the value DocumentKey1. For each document key, there is a variable number of subkeys. In our example above, the subkeys for the document are SubKey1, SubKey1.SubKey2, SubKey1.SubKey3 and SubKey4. Each of these subkeys is encoded according to the serialization format shown below.
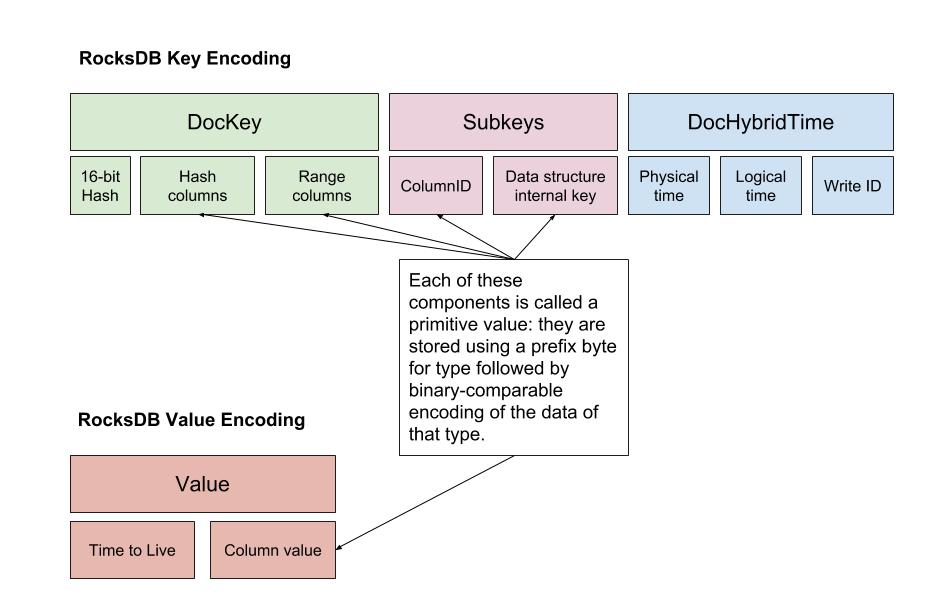
The byte-buffer that results from serializing one or more documents is prefix-compressed in order to make it efficient to store in memory (block-cache) or on disk (files). DocDB supports the following operations with high efficiency:
- Replacing an entire document
- Updating a subset of attributes from a document
- Querying for an entire document or for just a subset of attributes
- Compare-and-set operations within a document
- Scans both within a document or across documents
Every row in a SQL table corresponds to a document in DocDB. Since DocDB allows fine-grained updates and lookups of individual document attributes, the columns of a row in the SQL table can be updated and queried very efficiently. The details of how this works will be covered in a subsequent part of this series.
Summary
Bringing the Google Spanner architecture to life in the world of open source, cloud native infrastructure while retaining high-performance characteristics has been an exciting engineering journey to say the least. Add to that the opportunity to reuse and extend a mature SQL layer such as that of PostgreSQL. The proverbial “kid in the candy store” feeling is very much real for us 🙂
In the next post of this series, we dive into the details of how exactly we reused PostgreSQL’s query layer and made it run on DocDB. In a follow-up post, we highlight the lessons we learned in building such a “Spanner meets PostgreSQL” database over the last 3+ years.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner, and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing, or to schedule a technical overview.


