Distributed SQL Summit 2021: Rajkumar Sen on Fulfilling the Data Modernization Dream
October 27, 2021
It’s critical for enterprises to modernize and democratize their database to drive digital transformation. Being stuck with legacy infrastructure only causes massive problems downstream, such as an inability to scale due to high costs, fragility, and vendor lock-in. It also creates a burden to add more infrastructure to scale with a requirement to be always-on, lowering developer productivity.
Distributed SQL databases solve this problem for enterprises by providing lower TCO, multi-location geo-distribution, self-healing capabilities, and PostgreSQL compatibility. This gives developers, devOps, or DBAs an easy on-ramp to development without learning a new language or architecture.
At Distributed SQL Summit 2021, Rajkumar Sen, Founder and Chief Architect at Blitzz.io, gave a focused talk on how to modernize legacy data infrastructure using a distributed SQL database and continuous data replication. Let’s break down some highlights from his presentation.
Data modernization and democratization
Vendor lock-in is a major issue facing enterprises. Companies need to be able to move and transform data to modern cloud native architectures, as well as house data based on the best platform for the application. According to Sen, the idea of having silos in an organization to house data or a specific platform should not exist. Removing silos allows organizations to be more agile in development, implementation, and scaling.
Sen said vendor lock-in also holds back enterprises from moving data due to complexity, which results in downtime, loss of data, and the re-engineering of architecture and applications. For example, Amazon’s transition from Oracle into a combination of DynamoDB and RedShift was a complex, multi-year migration that required a whole new data model rewrite while ensuring there was very little to no downtime. Some of the rewrites forced Amazon to transition some of the relational schema into a NoSQL schema. This caused implications that were far-reaching, adding more stress to application developers.
The main point here, Sen said, is that the provisioning of this exercise was expensive and involved taking core business risks that not all enterprises can take-on. But if an enterprise does embark on the journey to migrate, it should:
- Retain relational data models.
- Select a feature-rich, distributed SQL database.
- Build new applications.
- Migrate existing applications.
- Migrate data with little or no downtime by keeping both systems in sync during transition.
With YugabyteDB — a truly distributed SQL database for transactional applications that is 100% open source — enterprises have the ability to run in any cloud environment. YugabyteDB is able to handle cloud native applications using SQL and NoSQL. It’s PostgreSQL compatible, highly resilient, highly available, horizontally scalable, and geographically distributed. This helps companies lower TCO, migrate with ease, and scale up without the need to maintain huge infrastructure or be locked-in due to any custom architecture.
Using Change Data Capture (CDC) technology during migrations
According to Sen, when migrating to modern architecture from legacy systems with no downtime, it’s important to keep both legacy systems and modern distributed databases in sync. The use of CDC technology can help pick up transactions from the source, transform the data to the target system, and apply the transaction on the target. To keep both in sync, it needs to perform continuous data replication from the legacy system to the new distributed database. CDC provides guaranteed transactional integrity and the ability to repair and replay, as well as handle DDLs and bi-directional data replication.
Three main requirements of a cloud native CDC are:
1. Transactional integrity, where data is consistent with the source and able to maintain a global order of transactions as source.
2. Scalability, where Extract and Load data move at a high volume and velocity while also being able to auto scale up and out.
3. Low data latency, with replication and minimal impact on source.
Sen presented the below architecture which implements CDC. It’s called a Global System of Access:
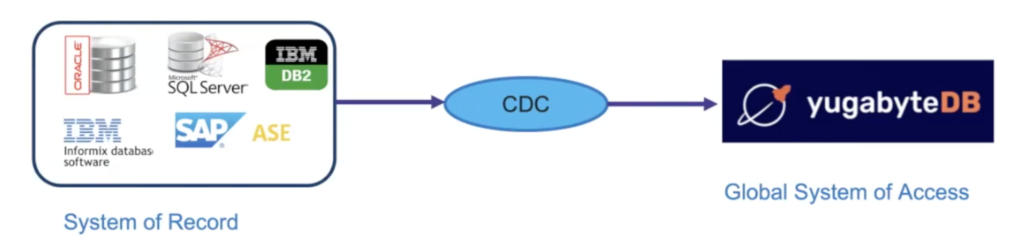
This architecture allows an enterprise to retain their legacy system as a system of record. Existing applications are then re-written and use the new database as a Global System of Access. This way, Sen said, companies can offload all the “read” requests to this system and reduce cost on the system of record. Additionally, developers can begin to build new applications on the Global System of Access.
In the past, Sen said, there was a need to build cross-DC redirects based on where the requests originated, which would increase latency. By using a feature-rich modern database like YugabyteDB that handles geo-distribution, there is no need to maintain these DC redirects. This also provides enterprises the flexibility to deploy on-prem, cloud, or hybrid cloud.
One addition to this architecture is a “proxy” underpinning the application, as illustrated below:
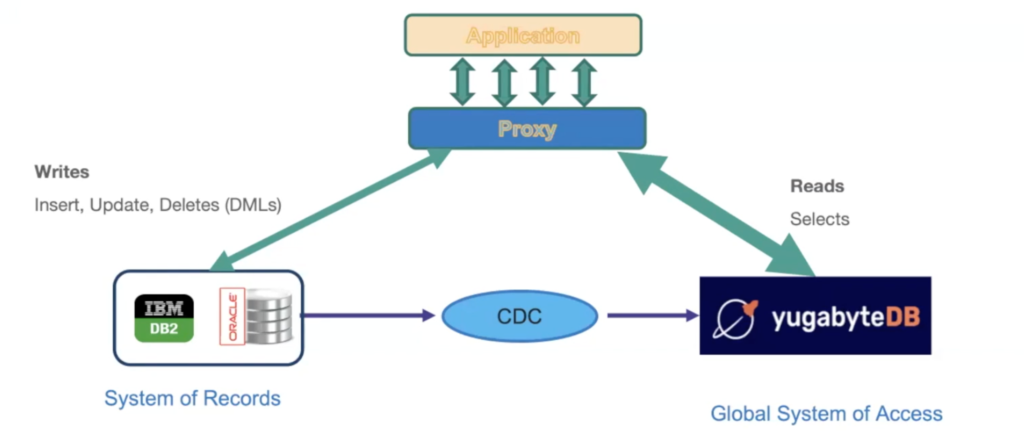
The role of the proxy is to primarily route the requests from the user. Most applications have more volume on “read” requests (80%) than “write” requests (20%). As a result, using a modern database to facilitate “read” requests helps to reduce latencies, lower TCO, and provide a better customer experience.
Summary
According to Sen, the future is in implementing a distributed SQL database like YugabyteDB. Relying on legacy systems to run microservices, born-in-the-cloud applications, and Edge and IoT applications is not the solution.
Want to learn more about YugabyteDB in action? Check out all the sessions from this year’s Distributed SQL Summit on-demand, including talks from Fiserv, General Motors, Kroger, Rakuten, Wipro, and others!


