Getting Started with PostgreSQL Triggers in a Distributed SQL Database
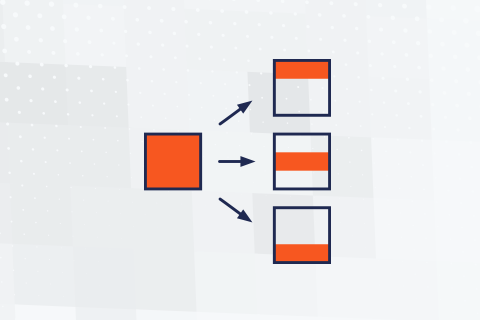
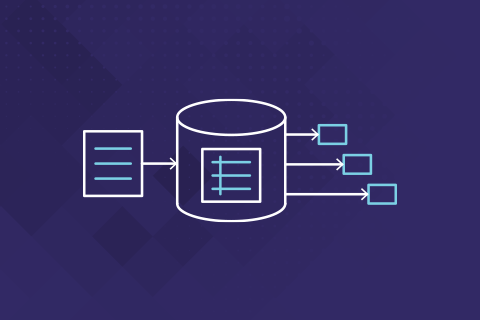
Triggers are a basic feature that all monolithic SQL systems like Oracle, SQL Server and PostgreSQL have supported for many years. They are very useful in a variety of scenarios ranging from simple audit logging, to advanced tasks like updating remote databases in a federated cluster. In this blog, we’ll look at examples of INSERT, UPDATE and INSTEAD OF triggers in Yugabyte DB.
What’s Yugabyte DB? It is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner.
…