Building a Strongly Consistent Cassandra with Better Performance
December 20, 2017
In an earlier blog on database consistency, we had a detailed discussion on the risks and challenges applications face in dealing with eventually consistent NoSQL databases. We also dispelled the myth that eventually consistent DBs perform better than strongly consistent DBs. In this blog, we will look more closely into how YugabyteDB provides strong consistency while outperforming an eventually consistent DB like Apache Cassandra. Note that YugabyteDB retains drop-in compatibility with the Cassandra Query Language (CQL) API.
YugabyteDB vs Apache Cassandra Performance
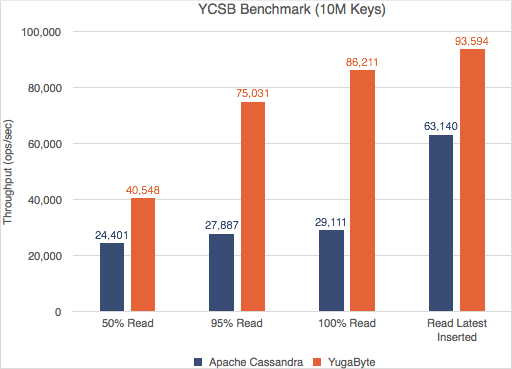
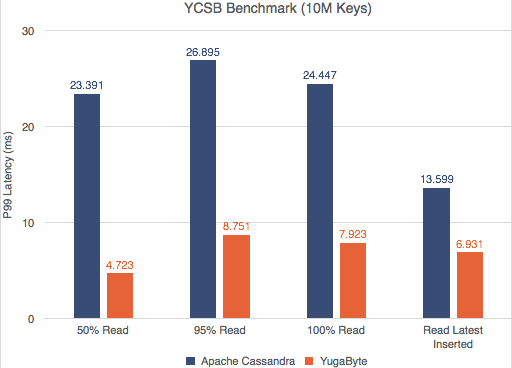
Yahoo! Cloud Serving Benchmark (YCSB) is a widely known benchmark for NoSQL databases. We ran YCSB tests against YugabyteDB and Apache Cassandra and are excited to confirm that YugabyteDB outperforms Apache Cassandra in both throughput and 99th percentile (p99) latencies.

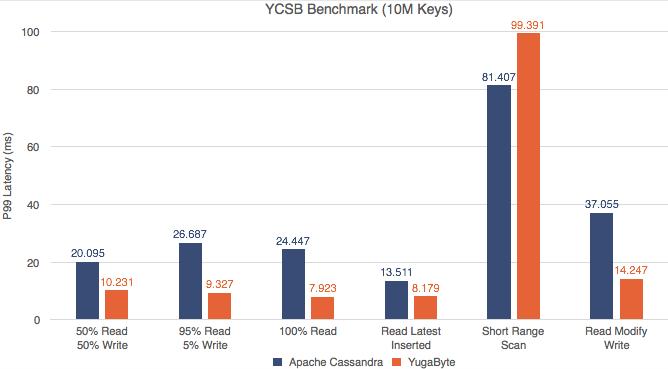
Not only does YugabyteDB outperform, the margin also widens with increasing data density (more keys). Readers who are interested to see the detailed performance numbers and the test configuration may check out our post here.
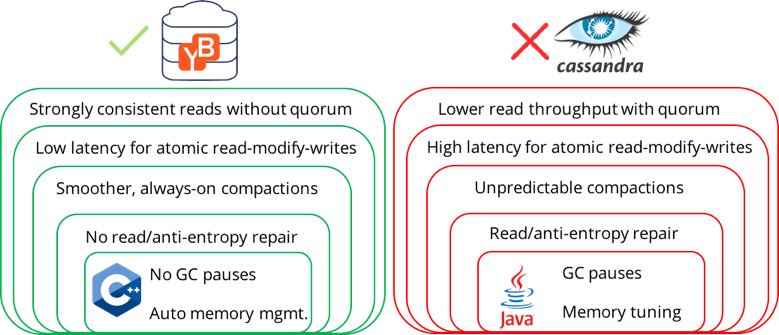
Why YugabyteDB outperforms Apache Cassandra?
There are 6 important architectural reasons that enable YugabyteDB to outperform Apache Cassandra.
1. Higher read throughput with lower latency
To achieve strong consistency (to a certain point) in an eventually consistent DB using quorum read, a read operation requires reading from all replicas in the quorum in order to return results agreed by the majority of the quorum. Because of that, the number of reads is multiplied by the replication factor (3x or more). So is the system load amplified by the same replication factor, negatively affecting the throughput of the system.
Not only is the load magnified, the response time is also more than doubled due to extra network round-trips necessary to read from the replicas. That gets even worse when the network is jammed by the extra traffic. Also, putting 3 servers in the critical path of reads has adverse effects on p99 latencies. Apache Cassandra suffers from lower throughput and higher latency because of these architectural constraints.
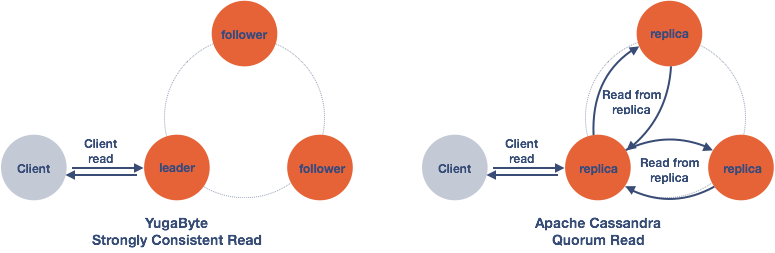
Let’s compare that to YugabyteDB performs during read operations. Because of the use of the RAFT consensus protocol, the data held by the quorum leader is guaranteed to be consistent. So a read operation requires only a single read (1x) from the leader. Therefore, YugaByte can deliver better performance as shown in the charts below because there is neither read amplification nor round-trips to other replicas.
2. Higher read-modify-write throughput with lower latencies
Non-atomic read-modify-write: In the read-modify-write workload above, YCSB models the read-modify-write operation using two separate read and write database statements without atomicity. As such, we already see that YugabyteDB outperforms Apache Cassandra.
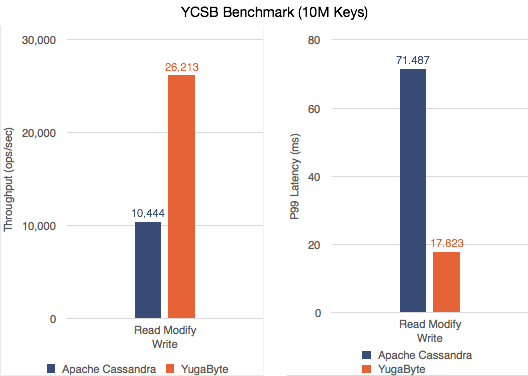
Atomic read-modify-write: To achieve atomicity, the read-modify-write operation can be executed as a single lightweight-transaction (LWT). In Apache Cassandra, an LWT requires a total of 4x round trips from the leader to the replicas to prepare, read, propose and commit the transaction. The many round trips lead to significant delays and poor LWT performance negatively affecting user applications.
In YugabyteDB, since the quorum leader always holds the consistent and update-to-date copy of the data, an LWT needs only a single (1x) round trip to the replicas to update the data. This better consistency design enables YugaByte to execute LWT way more quickly than Apache Cassandra.
3. Predictable performance during compactions
Another major source of slowdown in Apache Cassandra is background compactions. Users often complain of higher foreground latencies in their application layer when major compactions are running.
This is because long-running or major compactions “starve” the smaller but critical compaction jobs. This starvation causes an increase in read latencies. Once the larger compaction is done, the smaller compactions are able to run and latencies drop. This makes the latencies unpredictable on the application side. Advanced, technical users typically schedule their own compactions in the background in off-peak hours but these are both hard and not always possible.
In YugabyteDB, we break down compactions into major and minor compactions and schedule them in different queues and with different priorities. This guarantees a certain quality of service to the smaller, critical compactions, keeping the impact of background compactions on the user application to a minimum.
4. No read / anti-entropy repair
In an eventually consistent DB like Apache Cassandra, there is a possibility of inconsistent data in any replica. There are two ways this is dealt with.
- Read repair: A read operation requires reading from all replicas to determine the consistent result. Whenever inconsistent data is detected in any replica, the replica will require immediate foreground read repair.
- Anti-entropy maintenance: In addition, an eventually consistent DB also requires regular background anti-entropy maintenance, which compares data in all replicas and repairs any inconsistent data.
The above are expensive operations requiring a lot of CPU and network bandwidth to send copies of the data to replicas and compare them. To the end user application, this manifest itself as higher/unpredictable latencies, and the inability of the system to support larger data sets efficiently.
In the case of YugabyteDB, because of the strong consistency guaranteed by the RAFT protocol, neither read repair nor anti-entropy maintenance is necessary. This results in a low and predictable p99 latency. We did another benchmark test using Netflix Data Store Benchmark (NDBench) for 7 days and are pleased to see p99 latencies below 6 ms and even p995 under 7 ms.
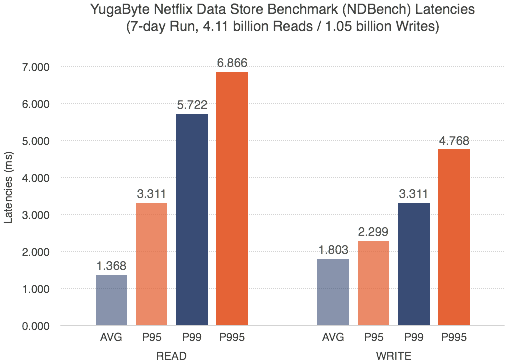
5. No garbage collection pauses
In Java-based NoSQL databases such as Apache Cassandra, long garbage collection (GC) pause is a well-known issue in production environment. It happens when the garbage collector pauses the application, marks and moves objects in-use, and discards unused objects to reclaim memory. In a long-running DB, such GC pauses often result in seconds of periodic system unavailability and long response time (the “long-tail” problem). While the state-of-the-art Garbage First (G1) GC can somewhat mitigate the issue by restricting the pause time, it unfortunately comes at the expense of reduced throughput. In the end, users will have to sacrifice either application throughput or latency.
Because YugabyteDB is implemented in C++ with no need for garbage collection, our users can have both maximal throughput and predictable response time without compromise.
6. Utilizing larger memory for better performance
Apart from GC tuning, Java memory tuning is another typical challenge Apache Cassandra users face. It requires a vast understanding of what different JVM heap sizes should be and which portion of the data is stored in off-heap buffers. And allocating more memory to Java heaps can hurt performance because of longer GC pauses. All these add up to the operational complexity that users need to overcome.
On the other hand, YugabyteDB can run efficiently on large-memory machines, and make effective use of the memory available without a need for manual tweaking and tuning.
Summary
In this blog, we dived into how YugabyteDB provides strong consistency while delivering superior performance through better design and implementation. We encourage you to download YugabyteDB and explore its core features on a local cluster.


