Bringing Distributed SQL to VMware Tanzu
April 14, 2020
VMware Tanzu, the newest offering from VMware’s stable of proven enterprise products, brings together a portfolio of open source projects for modernizing applications and automating infrastructure management. VMware Tanzu provides a managed Kubernetes environment on VMware vSphere or any public cloud of choice that allows a consistent way to provision and deploy the code for application developers.
The Yugabyte team collaborated with VMware to certify YugabyteDB for Tanzu Kubernetes environments, and we are happy to announce the availability of YugabyteDB in the Tanzu Marketplace. As the first distributed SQL database on Tanzu Marketplace, YugabyteDB provides application developers an easy and cloud native way of scaling the relational SQL workloads for microservices applications without having to face the complexities of traditional scaling techniques (more details on scaling with YugabyteDB are explained in this blog post). Another benefit is that the joint solution provides operations teams the best of both worlds, a cloud native database that runs in the same way as other stateless application services on a Kubernetes platform.
You can find the YugabyteDB Kubernetes solution in the modern applications category of the Marketplace.

This is the first in a series of blog posts in which we’ll cover the details on getting started with YugabyteDB on VMware Tanzu, along with the best practices of architecting cloud native microservices access patterns for YugabyteDB, and managing the complete stack on VMware Tanzu platform.
In this post, we’ll go over the installation steps for deploying a highly available YugabyteDB distributed SQL cluster on a VMware Tanzu Kubernetes environment.
Deployment Architecture
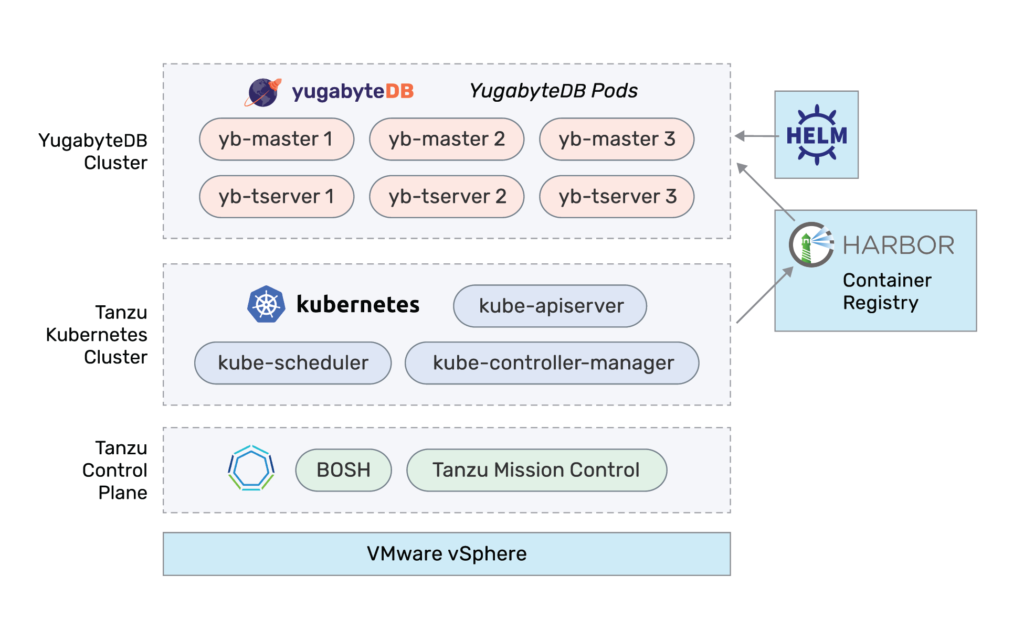
The above diagram provides a high-level overview of the components involved for deploying a YugabyteDB cluster on the VMware Tanzu stack. VMware Tanzu provides the capability of provisioning on-demand Kubernetes clusters on VMware vSphere or any cloud infrastructure of your choice.
At a high level, a YugabyteDB cluster consists of two main components: yb-tserver and yb-master. yb-tserver is the server responsible for storing the actual data and serving the client requests. yb-master is a lightweight server responsible for maintaining the system metadata and table shard location information. You can learn more about the components in a YugabyteDB cluster here.
Getting Started with YugabyteDB on VMware Tanzu
Prerequisites
- Access to a VMware Tanzu Kubernetes grid
- Minimum cluster requirements:
- 1x master node: 2 CPU, 4GB RAM
- 3x worker nodes: 8CPU, 16GB RAM
- Enable privileged container acces
- Access to Harbor registry
- Helm 2 and Tiller installed on the Tanzu Kubernetes cluster
- Docker installed locally
- About 15 minutes
Upload the YugabyteDB Container Image to Harbor Registry
Pull the YugabyteDB container image from Docker Hub:
$ docker pull yugabytedb/yugabyte:2.1.2.0
Log in to Harbor registry using your credentials:
$ docker login harbor.corp.local -u developer
Tag the images for uploading to Harbor:
$ docker tag yugabytedb/yugabyte:2.1.2.0 harbor.corp.local/yugabytedb/yugabyte:2.1.2.0
Push the Docker images to Harbor:
$ docker push harbor.corp.local/yugabytedb/yugabyte:2.1.2.0
On uploading the container image to Harbor, Harbor validates the images and runs the security vulnerability checks. Generally, Harbor will be configured to prevent vulnerable images from running with the severity of high or above.
Install YugabyteDB on Tanzu Kubernetes Cluster
YugabyteDB provides multiple ways of deploying the cluster on Kubernetes environments, including:
- YugabyteDB Helm chart
- YugabyteDB Operator
- YugabyteDB Platform
In this blog post we’ll be using YugabyteDB Helm charts for installing YugabyteDB on the Tanzu Kubernetes environment. As noted in the prerequisites section, we will be using Helm 2 for this purpose. You can refer to YugabyteDB documentation for Helm 3 instructions as well as other deployment methods.
Log in to the Tanzu Kubernetes environment
Get started by logging into the VMware Tanzu Kubernetes environment and getting credentials for the Kubernetes cluster where YugabyteDB is going to be installed:
$ pks login -a uaa.corp.local -u vmware -p ***** -k $ pks get-credentials yb-demo-cluster $ kubectl config use-context yb-demo-cluster
Create the service accounts required for Helm 2
Before you can create the cluster, you need to have a service account that has been granted the cluster-admin role:
$ kubectl create -f https://raw.githubusercontent.com/yugabyte/charts/master/stable/yugabyte/yugabyte-rbac.yaml
Add YugabyteDB chart to the Helm repository
$ helm repo add yugabytedb https://charts.yugabyte.com $ helm repo update
Review the values.yaml of the YugabyteDB Helm chart
Update the container repository to Harbor; the YugabyteDB image will pulled from the Harbor container registry:
Component: "yugabytedb"
Image:
repository: "harbor.corp.local/yugabytedb/yugabyte"
tag: 2.1.2.0
pullPolicy: IfNotPresent
resource:
master:
requests:
cpu: 2
memory: 4Gi
limits:
cpu: 2
memory: 4Gi
tserver:
requests:
cpu: 2
memory: 4Gi
limits:
cpu: 2
memory: 4Gi
Deploy the YugabyteDB cluster
By default, the YugabyteDB Helm chart installs a 3-node Yugabyte DB cluster with Replication Factor 3 so that every row of the database is stored using 3 replicas spread across the 3 nodes.
$ helm install -f values.yaml yugabytedb/yugabyte --namespace yb-demo --name yugabyte-demo-cluster --wait
Check YugabyteDB Cluster Status
Every YugabyteDB cluster exposes a YugabyteDB Master UI, which provides the details of the cluster, sharding information of the tables, and also the cluster metrics. Retrieve the Master UI load balancer IP address using the below command:
$ kubectl get service/yb-master-ui -n yb-demo
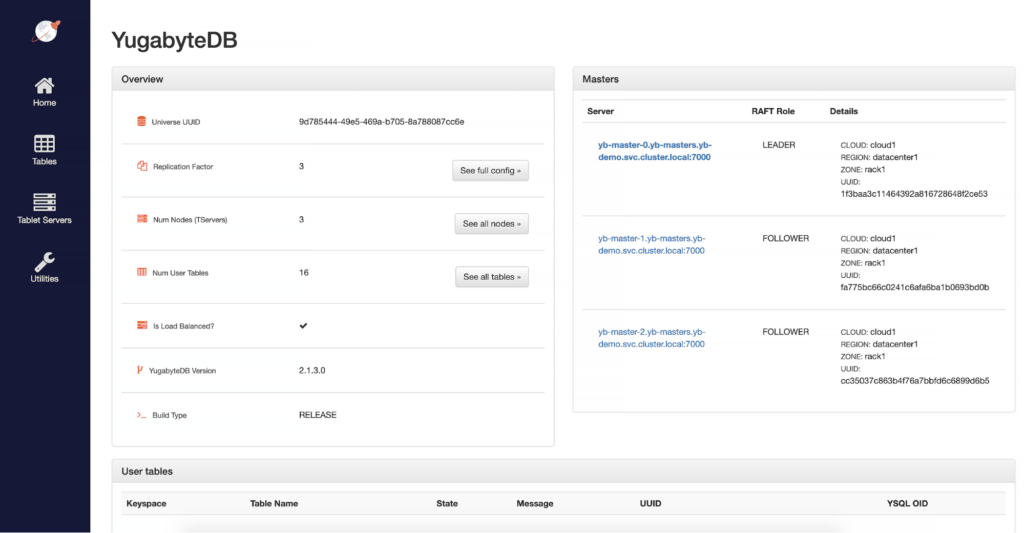
This blog post shows a quick and easy way to get started with YugabyteDB on the VMware Tanzu platform. As you can see with less than 15 minutes, we were able to deploy a highly available distributed SQL database on the Tanzu Kubernetes grid and this allows developers to quickly prototype backend services in the same way as other stateless application services on Kubernetes platform.
Stay tuned for the next blog post that will cover domain modeling for distributed SQL databases and developing cloud native applications using Spring Boot microservices on VMware Tanzu platform. In the meanwhile, you can explore below topics to familiarize yourself with distributed SQL concepts.
What’s Next?
- Learn more about internals of Distributed SQL
- Learn more about Spring + YugabyteDB
- Join the Spring community Slack channel
- Install YugabyteDB on your laptop and run a Spring Boot app


