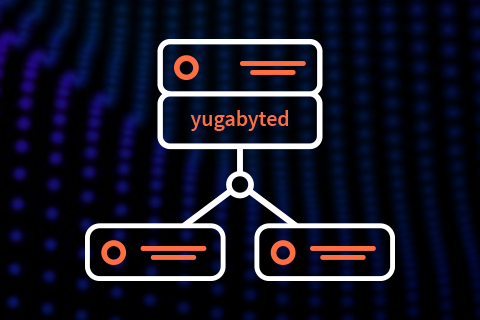
Using Envoy Proxy’s PostgreSQL & TCP Filters to Collect Yugabyte SQL Statistics
Layer 7 proxies like NGINX and HAProxy have been popular since the mid-2000s. The term “proxy” refers to their role as an intermediary for the traffic between an application client and an application server. The “layer 7” classification comes from the fact that these proxies take routing decisions based on URLs, IPs, TCP/UDP ports, cookies, or any information present in messages sent over a layer 7 (aka application layer) networking protocol like HTTP and gRPC.
…