Are Stored Procedures and Triggers Anti-Patterns in the Cloud Native World?
October 29, 2021
The last decade has seen a rise in usage of distributed SQL databases for transactional, cloud native applications. Popular options include Amazon Aurora, Google Spanner, YugabyteDB, and CockroachDB. All of these databases are resilient to failures and achieve high availability. However, they vary dramatically in the set of relational database management system (RDBMS) features they support.
Google Spanner and CockroachDB have chosen to rewrite the SQL engine from scratch. As a result, they do not implement many of the advanced features supported by a traditional RDBMS. Contrast this with Amazon Aurora and YugabyteDB, both of which chose to reuse the PostgreSQL query engine as the starting point — and therefore support most features. This is summarized in the table below (note: this is the current landscape as of October 2021):
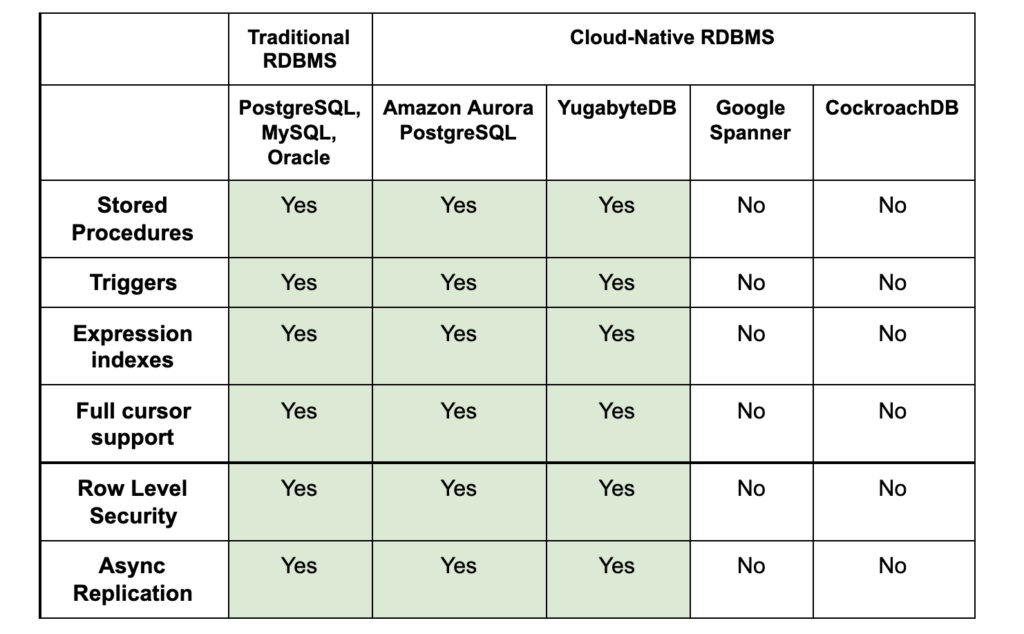
The term “stored procedures” is used in this table as a shorthand both for user-defined functions and procedures, typically written in SQL or PL/pgSQL, and for anonymous blocks, which can be written only in PL/pgSQL. The action that a trigger performs is expressed as a special kind of user-defined function. There are many reasons that established databases like PostgreSQL, Oracle Database, SQL Server, and so on support stored procedures. Some interesting examples are given below. The blog post “Using Stored Procedures in Distributed SQL Databases” by Yugabyte’s Bryn Llewellyn makes the general case.
Recently, Google Spanner announced the preview of a PostgreSQL interface for Google Spanner. This effort by Google Spanner highlights the importance of the PostgreSQL API and feature set when it comes to building cloud-native applications. That said, the current offering is very limited and does not include any of the features mentioned in the table.
Do cloud native applications really need traditional features such as triggers, partial indexes, and stored procedures that are supported in a traditional, single-node RDBMS? Or, would the lack of support impact the broad applicability of distributed SQL databases like Google Spanner and CockroachDB compared with Amazon Aurora or YugabyteDB?
In this post, we’ll explore practical examples where features such as triggers, stored procedures, expression indexes, async replication, and others are critical when building cloud native applications.
Triggers: automatic timestamps on row updates
A database trigger is a stored procedure which is automatically run whenever an event in the database occurs. For example, a trigger can be invoked when a row is inserted into a specified table, when certain table columns are being updated or when a table is dropped. Triggers are used to enforce referential integrity, or to log activity on database tables.
Many applications need to track the timestamp when a database record is created or updated. This is performed seamlessly by most traditional RDBMS using a combination of triggers and a user defined function. For example, if we wanted to automatically update the updated_at column value upon modifying any row in a table, this can be achieved in PostgreSQL (thereby YugabyteDB and Aurora as well) as shown below:
-- Create the table CREATE TABLE users ( id SERIAL NOT NULL PRIMARY KEY, name TEXT, details TEXT, created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(), updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW() ); -- Create the function that updates the timestamp CREATE OR REPLACE FUNCTION trigger_set_timestamp() RETURNS TRIGGER LANGUAGE plpgsql AS $body$ BEGIN NEW.updated_at = transaction_timestamp(); RETURN NEW; END; $body$; -- Create a trigger on the table CREATE TRIGGER set_updated_at BEFORE UPDATE ON users FOR EACH ROW EXECUTE PROCEDURE trigger_set_timestamp();
The above code instructs the database to automatically keep updating the updated_at column with the timestamp of the most-recent transaction that updated the row. The application then has only to code the business logic:
insert into users (name) values ('Yugabyte');
update users set details='superuser';
select * from users;And all the timestamp columns are automatically updated:
yugabyte=> \x yugabyte=> select * from users; -[ RECORD 1 ]----------------------------- id | 1 name | Yugabyte details | superuser created_at | 2021-08-23 13:54:28.839647+00 updated_at | 2021-08-23 13:54:37.656673+00
Now, if the underlying database does not support triggers and stored procedures, this becomes really complex – a distributed application running across multiple servers can make concurrent updates to different columns of the same row from different nodes, causing the timestamps to get out of whack. This would require the application to synchronize time across servers, which is infeasible for practical purposes.
Stored procedures: efficient geo-distributed batch updates
While cloud native applications are no longer writing their business logic using stored procedures, there are many scenarios where stored procedures remain critical for performance, especially in geo-distributed scenarios. Consider the common scenario of performing multiple UPDATE statements in a transaction as shown below:
BEGIN TRANSACTION; UPDATE mytable SET … WHERE key = k1; UPDATE mytable SET … WHERE key = k2; UPDATE mytable SET … WHERE key = k3; COMMIT;
Assume that in this geo-distributed deployment scenario, the client is running in the west coast region of the US, and the database server runs in the east coast region of the US. There is a 70ms network latency between the client and the server for each RPC call. The downside of doing the above approach is that it results in 5 separate RPC calls from the application to the database, which results in a latency of about 350ms. This is shown in the diagram below:
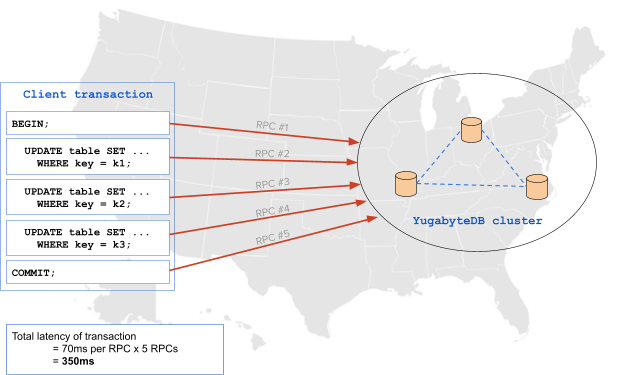
Using a PL/pgSQL encapsulation means that these multiple statements requiring many RPC calls to the database are reduced to just one statement (requiring only one RPC call). This technique improves both latency and efficiency in the execution of the query by allowing maximal batching of the operations in the database. The same scenario described above can be achieved with a single RPC using a stored procedure, dropping the latency by almost 5x to 70ms:
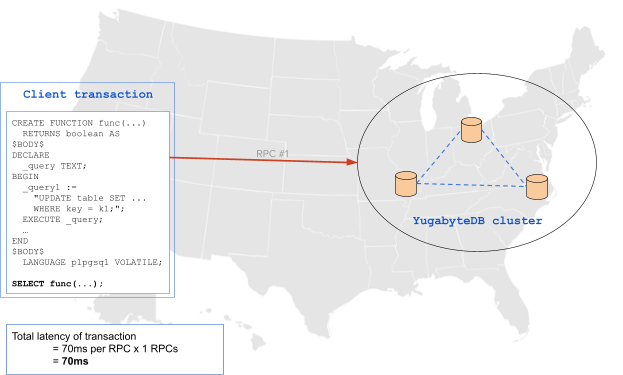
User-defined functions (UDFs): data validation in GraphQL / JAMStack applications
Let’s consider the recommended way to perform server-side data validation in Hasura, a popular GraphQL framework. The example of how to build data validation in a content management system in the Hasura documentation outlines the need for this feature. Let’s say we need to build a GraphQL application where an article’s content should not exceed 100 words. Assume that the article table shown below contains the articles written by users.
CREATE TABLE article (id uuid, title text, content text);
Anytime the content column of this table is updated, the length of the new value would have to be checked. However, this has to be done on the database side by creating a user-defined function, and invoking it from a trigger as shown below:
CREATE FUNCTION check_content_length() RETURNS trigger AS $ DECLARE content_length INTEGER; BEGIN -- split article content into words and get count select array_length(regexp_split_to_array(NEW.content, '\s'),1) INTO content_length; -- throw an error if article content is too long IF content_length > 100 THEN RAISE EXCEPTION 'Content has more than 100 words'; END IF; -- return the article row if no error RETURN NEW; END; $ LANGUAGE plpgsql;
Finally, the function defined above is invoked anytime the content column is updated using the following trigger:
CREATE TRIGGER check_content_length_trigger BEFORE INSERT OR UPDATE ON "article" FOR EACH ROW EXECUTE PROCEDURE check_content_length();
Without triggers, this would be custom code that would have to be deployed as an application server, which is significantly more complex to build and run in production environments.
Expression indexes: case-insensitive lookups
Let’s take the example of looking up users by name in a case insensitive manner. In this scenario, we assume there is a users table containing a user id and their first and last names, as shown below:
-- Create the users table CREATE TABLE users ( id SERIAL NOT NULL PRIMARY KEY, first_name TEXT, last_name TEXT, ... );
Now, let’s say we want to find all users whose first_name is ‘John’ irrespective of the capitalization when it was entered (‘John’, ‘john’, ‘JOHN’, etc). This can easily be achieved with the following expression index:
CREATE INDEX idx_first_name ON users ((lower(first_name)));
Similarly, if we wanted to look up users by their full name (first and last name), this can be done with another expression index:
CREATE INDEX idx_name ON users ((first_name || ' ' || last_name));
These indexes can be created dynamically, meaning it can build the index on the fly after the data was entered. Without expression indexes, the application would get a lot more complex—or require replication to an additional text search service.
Server-side cursors: scanning a large table
Cursors allow applications to efficiently scan through and process large data sets, without having to re-execute the query again and again. Additionally, cursors allow distributed data processing on the application side. Multiple queries can be executed to a single database backend, which allows processing subsets of the data in parallel. This prevents having to store all of the results in memory within the application.
Take an example scenario where a batch job wants to analyze all the orders placed by various customers over the last week. There could potentially be a large number of orders. And if these are fetched using a single query the result set could overwhelm the memory on the servers. Thus, this large list of orders would have to be processed in batches, which can be achieved quite easily and efficiently using cursors on the server side.
Step 1 is to declare a cursor to read the orders placed in the last week, as shown below:
DECLARE weekly_orders CURSOR FOR SELECT * FROM orders WHERE order_date > (CURRENT_DATE - INTERVAL '7 days') ORDER BY order_date;
The job can now fetch 10 orders at a time to process using the cursor as shown below:
FETCH 10 FROM weekly_orders;
In this scenario, the database maintains the pointer to the correct location in the result set, which makes the processing of data in batches really simple. Without cursors, the applications would need to repeatedly execute the SQL query, specifying a different LIMIT and OFFSET value each time. These queries that specify a LIMIT and OFFSET tend to be very inefficient because they read a lot more data from disk than requested by the user.
Row level security (RLS): multi-tenant data isolation
Multi-tenant architectures are becoming common with the rise of SaaS companies. A well designed multi-tenant architecture can enable development agility and save operational overhead by amortizing resources across tenants instead of replicating them for each tenant. That said, it is absolutely essential to ensure isolation of tenant data – no tenant should be able to access the data that belongs to another tenant. This can be enforced at the database level by using row level security (RLS). RLS policies, which define who can view what subset of the data, can be dynamically applied on tables.
Let’s take a look at a simple example of using RLS for multi-tenancy. Let’s say there is a tenant table defined as shown below:
CREATE TABLE tenant (
tenant_id SERIAL PRIMARY KEY,
name VARCHAR UNIQUE,
status VARCHAR CHECK (status IN ('active', 'disabled')),
tier VARCHAR CHECK (tier IN ('gold', 'silver', 'bronze'))
);Now, ensuring that a tenant can view rows belonging to their organization, as well as ensuring that no tenant can view rows belonging to other tenants can both be made the database concern by creating a row level security policy as shown below:
-- Turn on RLS for this table ALTER TABLE tenant ENABLE ROW LEVEL SECURITY; -- Restrict table access so any tenant can only see their rows CREATE POLICY tenant_isolation_policy ON tenant USING (tenant_id::TEXT = current_user);
The above policies can be specified for each table that needs to limit the scope of data access by any single tenant to see only their rows. Having the database do the heavy lifting to ensure isolation across different tenants is both safer and simpler when building applications.
Async replication: modernizing apps using Oracle Maximum Availability Architecture (MAA)
While synchronous replication in databases like Google Spanner, CockroachDB and YugabyteDB simplify some use cases, async replication still remains a critical feature for cloud native applications. Let’s take the example of one blueprint for achieving such a deployment using Oracle Maximum Availability Architecture (MAA), Oracle RAC clusters, and GoldenGate replication to analyze the architecture in brief. The key points are listed in the diagram below:
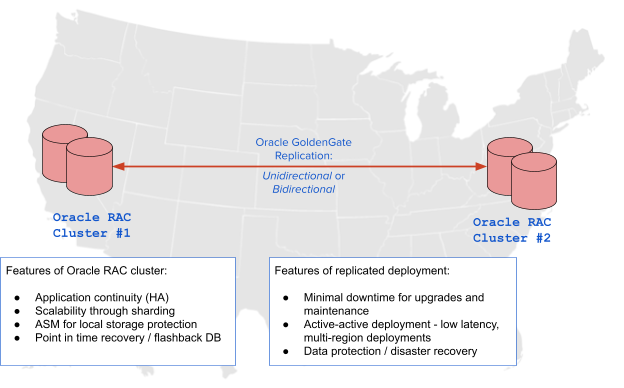
The figure above shows the various benefits being achieved. Some of the benefits gained by using async replication between clusters cannot easily be achieved in synchronously replicated “stretched” clusters. These are listed below:
- Predictable, low latency: In the case of bidirectional replication, all read and write operations incur a low latency, while all the data is replicated to the other cluster for redundancy. With synchronous replication, there is a choice between replicating data everywhere (increases latency) or geo-partitioning data (decreases redundancy).
- Testing new versions: Test new database versions (or in some cases, new application software as well) by upgrading only the async replica. The replica can be rolled back with no impact to the main cluster if something does not work as expected.
- Multi-cloud or hybrid deployments: Some scenarios require keeping data replicated between different public clouds, or between a private and public cloud. As an example, consider the example of live-migrating some use-cases between clouds using async replication. This was the strategy used by Narvar to move some workloads from AWS to GCP.
- Flexible topology (e.g., edge use cases): Async replication can be set up in a much more flexible manner than synchronous replication. As an example, consider the retail use-case where there are multiple edge locations of the database cluster in each of the physical stores across many cities. Each of these edge clusters would want to replicate their partial view of data asynchronous to a central database cluster for a consolidated view across the different physical store locations.
The equivalent of the above features can be achieved using a combination of synchronous replication within a region and asynchronous replication across regions as shown in the example below:
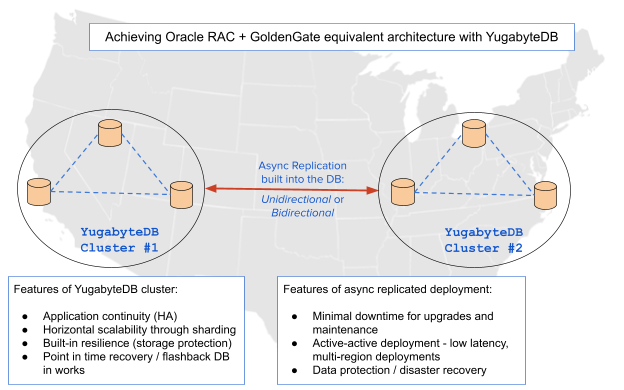
As a result, async replication remains very essential for cloud native applications and microservices.
Conclusion
Today, business logic is written in the application tier where changes can be made in programmer-friendly languages and deployed into production with greater agility using sophisticated CI/CD pipelines. This move of business logic to the application tier is often misunderstood and used as a reason by some of the newer, distributed SQL databases to not support a number of these traditional RDBMS features. However, there is a huge difference between not using a particular database feature to implement business logic, and not being able to leverage the database feature at all (because the database does not support it).
Traditional databases, such as Oracle, SQL Server, PostgreSQL and MySQL, offer powerful features as described in this post. However, leveraging these same features for cloud native applications built atop a distributed SQL database can dramatically simplify application development while also improving performance and strengthening security, without having to implement business logic.
This post outlined practical scenarios where seven traditional RDBMS features are extremely useful. Note that enabling such features on a distributed SQL database is not necessarily easy, even if the value unlocked by it is immense.
If you’re interested in working on the cutting edge of distributed SQL databases, come and join us – we’re hiring!


