Apache Cassandra: The Truth Behind Tunable Consistency, Lightweight Transactions & Secondary Indexes
October 22, 2018
ACID transactions were a big deal when first introduced formally in the 1980s in monolithic SQL databases such as Oracle and IBM DB2. Popular distributed NoSQL databases of the past decade including Apache Cassandra initially focused on “big data” use cases that did not require such guarantees and hence avoided implementing them altogether. Our post, “A Primer on ACID Transactions: The Basics Every Cloud App Developer Must Know” details the various types of ACID transactions (single key, single shard and multi-shard) and the underlying database engine features necessary to support such transactions.
In this post, we look at the evolution of transactions in Apache Cassandra especially in the context of Quorum Reads/Writes, Lightweight Transactions and Secondary Indexes. These features were enhanced/added in response to user demand for running transactional workloads long after the original Facebook release. However, Apache Cassandra is not even built on strongly consistent replication and hence lacks the foundation necessary for ACID transactional guarantees. As a result, these features manifest themselves as extremely confusing and poorly performing operations to application developers.
Eventually Consistent Replication
Apache Cassandra was open sourced by Facebook in 2008 after its success as the Inbox Search store inside Facebook. It was designed as a distributed storage system for managing structured data that can scale to a very large size across many commodity servers, with no single point of failure. High availability is achieved using eventually consistent replication which means that the database will eventually reach a consistent state assuming no new updates are received. As the data is replicated, the latest version of something is sitting on some node in the cluster, but older versions are still out there on other nodes. Reads execute on the closest replica and data is repaired in the background for increased read throughput. In terms of the CAP Theorem, Apache Cassandra is an Available and Partition-tolerant (AP) database.
The architecture of a single region, 3-node cluster with replication factor 3 is shown in the figure below. The data partitioning scheme used is that of a ring-based topology that uses consistent hashing to partition the keyspace into token ranges and then maps them onto virtual nodes where each physical node has multiple virtual nodes. Each token range is essentially a partition of data, noted as p1, p2, p3 and more. Each such partition has 3 replicas that are placed on the 3 different nodes. Note that all the 3 replicas are exactly equal and there is no concept of a partition leader that is used in Consistent and Partition-tolerant (CP) databases such as Google Spanner or its derivatives such as YugabyteDB. Apache Cassandra’s approach instead takes inspiration from the Amazon Dynamo paper published in 2007.
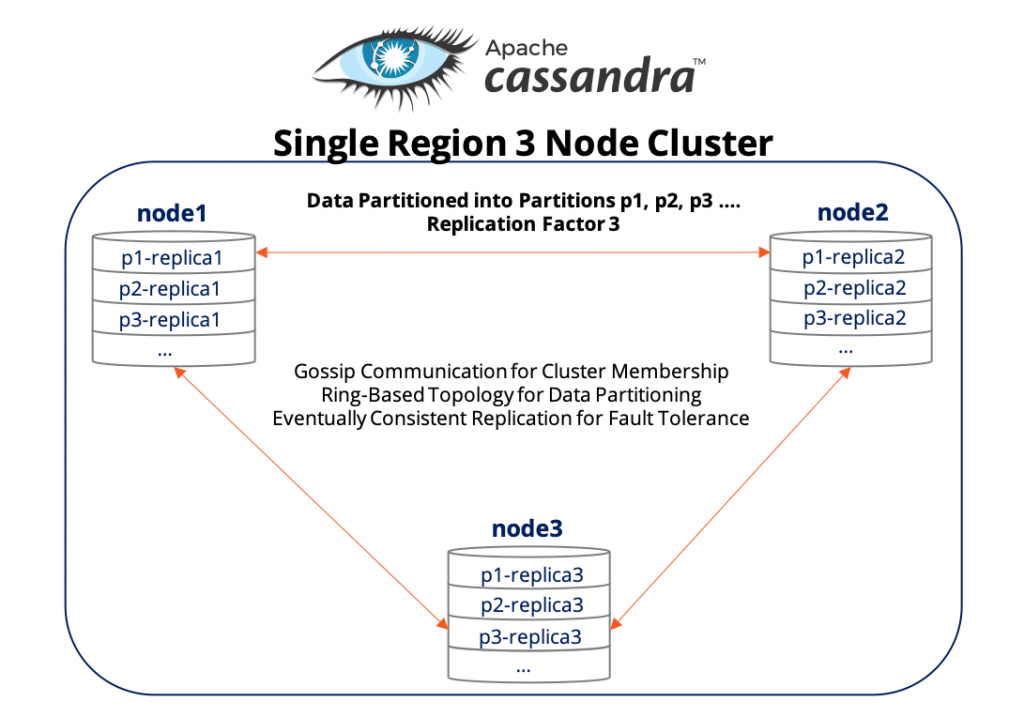 Apache Cassandra Replication Architecture
Apache Cassandra Replication Architecture
The above cluster can tolerate a single failure (entire node failure or partitioned away) without any loss of availability since the remaining 2 replicas can continue to serve the incoming read/write requests.
BASE Operations, Not ACID Transactions
Apache Cassandra operations follow the BASE paradigm which means that they are Basically Available Soft-state Eventually-consistent. This approach is the opposite of ACID transactions that provide strong guarantees for data atomicity, consistency and isolation. Each such BASE operation can have a consistency level and can be classified either as a write operation that changes the value of a key or a read operation that simply reads the value of a key.
Consistency Levels
Cassandra’s tunable consistency comes from the fact that it allows per-operation tradeoff between consistency and availability through consistency levels. Essentially, an operation’s consistency level specifies how many of the replicas need to respond to the coordinator (the node that receives the client’s read/write request) in order to consider the operation a success.
The following consistency levels are available:
- ONE – Only a single replica must respond.
- TWO – Two replicas must respond.
- THREE – Three replicas must respond.
- QUORUM – A majority (n/2 + 1) of the replicas must respond.
- ALL – All of the replicas must respond.
- LOCAL_QUORUM – A majority of the replicas in the local datacenter (whichever datacenter the coordinator is in) must respond.
- EACH_QUORUM – A majority of the replicas in each datacenter must respond.
- LOCAL_ONE – Only a single replica must respond. In a multi-datacenter cluster, this also guarantees that read requests are not sent to replicas in a remote datacenter.
- ANY – A single replica may respond, or the coordinator may store a hint. If a hint is stored, the coordinator will later attempt to replay the hint and deliver the mutation to the replicas. This consistency level is only accepted for write operations.
- SERIAL – This consistency level is only for use with lightweight transaction. Equivalent to QUORUM.
- LOCAL_SERIAL – Same as SERIAL but used to maintain consistency locally (within the single datacenter). Equivalent to LOCAL_QUORUM.
Choosing the Right Consistency Level
This post on Medium has a detailed discussion on how to pick consistency levels in Cassandra. Lower consistency levels like ONE improve throughput, latency, and availability at the expense of data correctness by not involving other replicas for the operation. And that’s the primary design point of Apache Cassandra — store large volumes of data at low consistency and high availability. However, when correctness of data starts becoming important as is the case in transactional apps, users are advised to pick read and write consistency levels that are high enough to overlap. The understanding here is that this will lead to “strong consistency” and is typically expressed as W + R > RF, where W is the write consistency level, R is the read consistency level, and RF is the replication factor. For example, if RF = 3, a QUORUM request will require responses from at least two of the three replicas. If QUORUM is used for both writes and reads (which means W=2 and R=2), at least one of the replicas is guaranteed to participate in both the write and the read request, which in turn guarantees that the latest write will be read. In a multi-datacenter environment, LOCAL_QUORUM should be used to ensure that reads can see the latest write from within the same datacenter.
As we see in the next section, the above “W + R > RF” does not work in practice because a simple quorum during read and write is not guaranteed to ensure even single-key linearizable reads, the most fundamental guarantee necessary to achieve multi-key ACID transactions.
Want Transactional Behavior? Get Ready for Dirty Data or Poor Performance
Quorum Writes & Reads ≠ Strong Consistency
Apache Cassandra quorum writes and reads are notorious for serving dirty data in presence of failed writes. As shown in the figures below, a quorum read can serve correct data when the quorum write preceding it succeeds completely.

Apache Cassandra Quorum Writes – Success Case
However, writes that fail because only a partial set of replicas are updated could lead to two different readers seeing two different values of data. This is because of the lack of rollbacks in simple quorum based consistency approaches. This behavior breaks the linearizability guarantees for single-key reads. As described in this StackOverflow discussion, a distributed consensus protocol such as Raft or Paxos is must-have for such a guarantee.
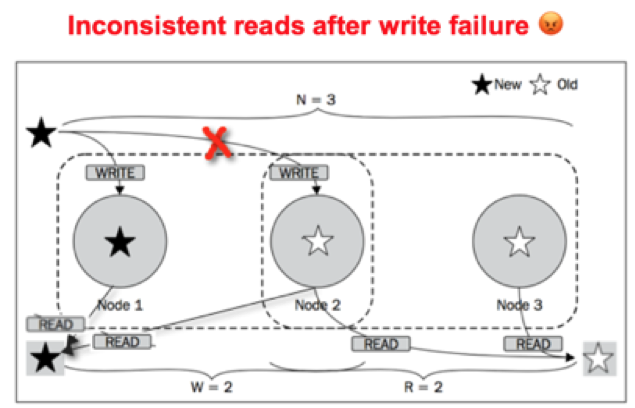
Apache Cassandra Quorum Writes – Failure Case
Lightweight Transactions = Extremely High Latency
Compare And Set (CAS) operations require a single key to be read first before updating it with new value with the goal of ensuring the update would lead to a unique value. At the Cassandra Query Language level, this means using IF EXISTS or any other IF. Under the hood, Apache Cassandra executes these operations using “lightweight” transactions.
INSERT INTO payments (payment_time, customer_id, amount) VALUES (2017-11-02 12:23:34Z, 126, 15.00) IF NOT EXISTS;
UPDATE payments SET amount = 20.00 WHERE payment_date = 2017-11-02 12:23:34Z AND customer_id = 126 IF amount = 15.00
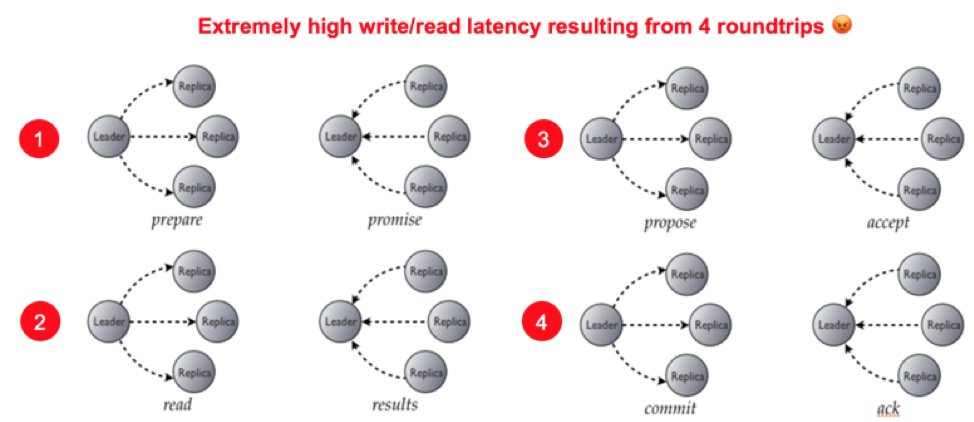
Apache Cassandra Lightweight Transactions
For lightweight transactions, Apache Cassandra upgrades its consistency management protocol to Paxos automatically but then suffers an extremely high latency of 4 round-trips between the coordinator node (aka leader node) and the replicas as shown in the figure above. Each step noted below results in a round-trip communication.
- Step 1: Propose a Paxos ballot (a timeuuid value) to all replicas of the given partition.
- Step 2: Check the condition (
IF NOT EXISTS, IF EXISTSorIF col=val). If the condition is not met, fail here. - Step 3: Else, wait for a SERIAL/LOCAL_SERIAL to accept the Paxos ballot
- Step 4: Commit and apply the mutation (
INSERT, UPDATE or DELETE)
Most production deployments of Cassandra stop using lightweight transactions after some time through complex refactoring/rearchitecture of their application logic because the 4 round-trip latency becomes impossible to hide from end users. For deployments that persist with such transactions, sporadic errors and non-deterministic behavior are common as described in this StackOverflow thread and this CASSANDRA-9328 “Won’t Fix” issue. The final comment on the issue captures the frustration of developers.
“I am completely discouraged. Is there any workaround on this? If LWT and CAS can not be actually used on non-idempotent operations, what is a real use case of the current implementation?”
Secondary Indexes = Poor Performance
Our post “Speeding Up Queries with Secondary Indexes,” we highlight the need for fast and correct secondary indexes. As described in “Cassandra at Scale: The Problem with Secondary Indexes,” secondary indexes are essentially an anti-pattern in Apache Cassandra given the way they are stored on the cluster. A primary index is global in the sense that every node knows which node has the data for the key being requested. However, secondary index is local to every node and every read with secondary indexes has to read from disk on ALL nodes. The following quote from the post highlights the problem clearly…
“So, let’s say you’re running Cassandra on a ring of five machines, with a primary index of user IDs and a secondary index of user emails. If you were to query for a user by their ID—or by their primary indexed key—any machine in the ring would know which machine has a record of that user. One query, one read from disk. However to query a user by their email—or their secondary indexed value—each machine has to query its own record of users. One query, five reads from disk. By either scaling the number of users system wide, or by scaling the number of machines in the ring, the noise to signal-to-ratio increases and the overall efficiency of reading drops – in some cases to the point of timing out on API calls. This is a problem.”
Similar to the case with lightweight transactions, Apache Cassandra production deployments that start using secondary indexes soon stop using them altogether by denormalizing their data even further so that secondary index queries become primary index queries instead. However, they have to take extreme care in engineering the solution because the update across the 2 indexes will no longer be perfectly atomic.
Summary
Application developers choosing Apache Cassandra as their default operational database understand well that their choice does not support multi-shard (aka distributed) ACID transactions. But they mistakenly believe that they can use Cassandra features such as quorum writes/reads, lightweight transactions and secondary indexes to achieve single-key ACID guarantees. This is because the Cassandra marketing and technical documentation over the years has promoted it as a “consistent-enough” database. As we reviewed in this post, that is far from the truth. The only good use of Apache Cassandra is in context of its original intent as a inexpensive, eventually consistent store for large volumes of data. Newer Cassandra compatible databases such as DataStax Enterprise and ScyllaDB suffer from the same problems as Apache Cassandra since they have not changed the design of the eventually consistent core.
For use cases that simultaneously need strong consistency, low latency and high density, the right path is to use a database that is not simply Cassandra compatible but is also transactional. This is exactly what YugabyteDB offers. Each of the problems highlighted here are solved by YugabyteDB at the core of its architecture.
- Single-key writes go through Raft (which also uses quorum) in YugabyteDB but reads are quorumless and hence can be served off a single node both for strongly consistent and timeline-consistent (aka bounded staleness) cases. Multi-key transactions are also supported through the use of a transaction manager that uses an enhanced 2-phase commit protocol.
- Lightweight transactions are obviated altogether in YugabyteDB since the Raft-based writes on a single key are automatically linearizable.
- Secondary indexes are global similar to the primary indexes so only the nodes storing the secondary indexes are queried.
What’s Next?
- Compare YugabyteDB to databases like Amazon DynamoDB, Apache Cassandra, MongoDB and Azure Cosmos DB.
- Get started with YugabyteDB on Kubernetes.
- Contact us to learn more about licensing, pricing, or to schedule a technical overview.


