Apache Cassandra DB Architecture Fundamentals
August 9, 2018
What is the Apache Cassandra Database?
Apache Cassandra is a distributed open source database that can be referred to as a “NoSQL database” or a “wide column store.” Cassandra was originally developed at Facebook to power its “Inbox” feature and was released as an open source project in 2008. Cassandra is designed to handle “big data” workloads by distributing data, reads and writes (eventually) across multiple nodes with no single point of failure.
How does Cassandra work?
Cassandra is a peer-to-peer distributed system made up of a cluster of nodes in which any node can accept a read or write request. Similar to Amazon’s Dynamo DB, every node in the cluster communicates state information about itself and other nodes using the peer-to-peer gossip communication protocol.
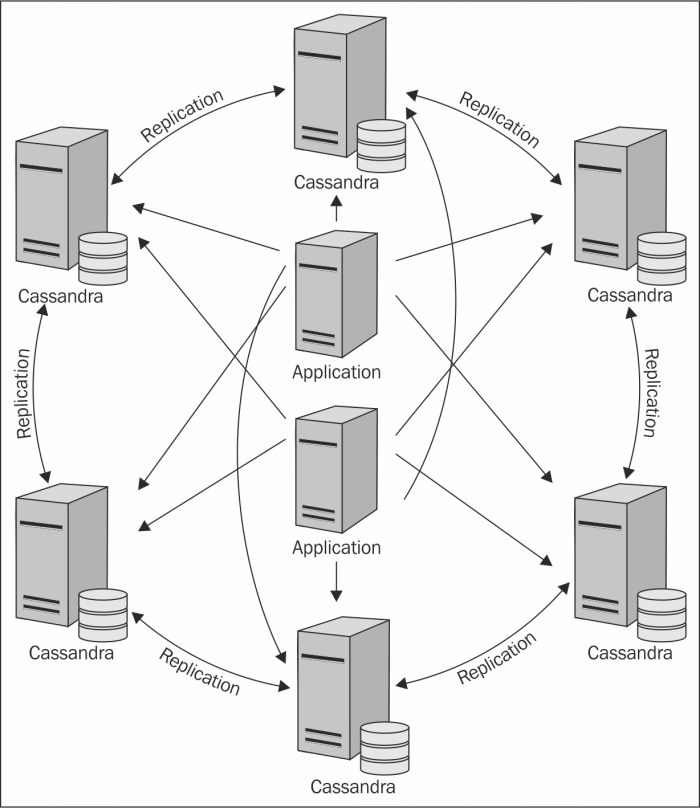
Cassandra Architecture – Source: Safari Books Online
At its core, Cassandra uses a Log Structured Merge (LSM) storage engine. The following are the key elements of the Cassandra storage engine…
Commit log
Each node in a Cassandra cluster also maintains a sequential commit log of write activity on disk to ensure data integrity. These writes are indexed and written to an in-memory structure called a memtable.
Memtable
A memtable can be thought of as a write-back cache where write I/O is directed to cache with its completion immediately confirmed by the host. This has the advantage of low latency and high throughput. The memtable structure is kept in Java heap memory by default. However, as of Cassandra 2.1, there is the option to store memtable outside of Java heap to alleviate garbage collection (GC) pressure.
SSTables
When the commit log gets full, a flush is triggered and the contents of the memtable are written to disk into an SSTables data file. At the completion of this process the memtable is cleared and the commit log is recycled. Cassandra automatically partitions these writes and replicates them throughout the cluster.
Compaction
Cassandra periodically consolidates SSTables using a process called “compaction.” The frequency of these “compactions” are dictated by several parameters set in Cassandra’s yaml configuration file or through commands using the Cassandra Query Language (CQL). In a compaction operation, Cassandra merges keys, combines columns, evicts tombstones (data that has been marked as obsolete), consolidates SSTables and creates new indexes.
YugabyteDB has a similar LSM storage engine design as Cassandra, but with additional benefits to performance and durability:
Commit log
Cassandra uses majority writes to update the commit logs of the replicas. This results in dirty reads, deletes resurfacing and lower performing quorum reads. YugabyteDB uses the Raft protocol to update commit logs while maintaining strong consistency and avoiding these issues.
Memtable
Java is notorious for GC pauses when running on large memory machines. Cassandra’s off-heap storage is an attempt to alleviate the issue, but Java GC still needs to be tuned carefully in order to run Cassandra on large memory machines. YugabyteDB is written in C++ so it avoids Java’s GC problems all together.
Compaction
YugabyteDB schedules multi-threaded compactions based on size thresholds, resulting in more predictable performance both in terms of the ingest rate, as well as, p99 read latencies.
Further reading
“Comparing Apache Cassandra to YugabyteDB”
What language is Cassandra written in?
As mentioned, Cassandra is written in Java. Long garbage collection (GC) pauses are a well-known issue in production environments. These performance issues surface when the garbage collector pauses the application (in this case Cassandra), marks and moves objects in-use, and discards unused objects to reclaim memory. In a long-running database, such GC pauses often result in seconds of periodic system unavailability and long response times (the “long-tail” problem). While use of the state-of-the-art Garbage First (G1) GC can somewhat mitigate the issue by restricting the pause time, it unfortunately comes at the expense of reduced throughput. In the end, users will have to sacrifice either throughput or latency.
YugabyteDB is implemented in C++ with no need for garbage collection. This means users can have both maximal throughput and predictable response time without compromise.
How do you read and write data in Cassandra?
The Cassandra Query Language (CQL) is used to insert, update, delete and read data in Cassandra.
YugabyteDB is CQL wire compatible. This means that the all the various Cassandra client drivers can be used to read/write into YugabyteDB clusters “as-is.” Yugabyte DB also supports Redis and PostgreSQL compatible APIs with the same underlying storage engine.
Further reading
“YugabyteDB’s API reference guide for Cassandra, Redis and PostgreSQL”
What are the consistency, availability and partition tolerance characteristics of Cassandra?
Cassandra is an “AP” database, which relative to the CAP theorem means it prioritizes availability and partition tolerance over consistency. Although Cassandra’s original design was optimized for eventual consistency, the vast majority of implementations attempt to do quorum reads and writes in order to achieve stronger consistency. The penalty for quorum reads ends up being poor performance and higher latencies, especially for read operations. To achieve linearizable consistency (single-operation, single-object, real-time order) Cassandra makes use of “lightweight transactions.” Using a quorum-based algorithm and the Paxos consensus protocol, these “lightweight transactions” can achieve consistency at the cost of four round trips. As of version 3.0, Cassandra does not support serializability, or isolation (the “I” in ACID.) Serializability is important in applications where strong data consistency and transactions are required. Serializability guarantees that the execution of a set of transactions (which may contain multiple read and write operations) is equivalent to some total ordering of the transactions.
YugabyteDB is a consistent and partition tolerant (CP) database and ensures higher orders of availability that can tuned by the end user. YugabyteDB makes use of the Raft consensus protocol and supports ACID transactions out of the box.
Further reading
“How consensus-based replication protocols work in distributed databases”
What are Lightweight Transactions (LWT) in Cassandra?
Lightweight Transactions (LWT) in Cassandra are used to provide the Compare and Set (CAS) primitive. They are used to implement conditional inserts/updates (INSERT or UPDATE IF a condition holds true) and for incrementing counters. LWT operations require four round trips and will degrade performance. From the CQL documentation:
Lightweight transactions should not be used casually, as the latency of operations increases fourfold due to the due to the round-trips necessary between the CAS coordinators.
YugabyteDB supports these LWT operations with just one round-trip because of its strongly consistent core.
Does Cassandra support secondary indexes?
Cassandra’s secondary indexes are unique to the data stored on a specific node in the cluster. This means that if a query requires data from multiple nodes, it can quickly drag down performance. A best practice in regards to secondary indexes in Cassandra is to only index a column with low cardinality and few values. Why are secondary indexes important? When correctly implemented they make it possible to execute queries faster.
YugabyteDB provides consistent, ACID-compliant secondary indexes built on top of its distributed ACID transactions. Local secondary indexes in Apache Cassandra require a fan-out read to all nodes, i.e. index performance keeps dropping as cluster size increases. With With YugabyteDB’s distributed transactions, secondary indexes will be both strongly-consistent and be point-reads rather than needing a read from all nodes/shards in the cluster.
Further reading
“A Quick Guide to Secondary Indexes in YugabyteDB.”
How is Cassandra deployed in multi-region use cases?
Cassandra’s multi-region deployments usually involve accepting writes in each region at LOCAL_QUORUM consistency. This is to ensure that write latency remains low and does not involve cross-region communication. Concurrent writes on the same record at multiple regions requires conflict resolution without application knowledge using the Last-Writer-Wins non-deterministic heuristic. This means applications may lose data that they had previously thought was committed.
YugabyteDB supports two models of multi-region deployments both with zero data loss:
Global consistency with continuous availability even under region failures or
Regional consistency with continuous availability under zone/rack failures and one or more read replicas in other regions to support low latency reads. Users get a higher degree of flexibility of how to best balance write latency and region-level failure tolerance.
Further reading
“Scale Transactional Apps Across Multiple Regions with Low Latency”
What’s next?
- Read “Building a Strongly Consistent Cassandra with Better Performance”
- Compare YugabyteDB to databases like DynamoDB, Cassandra, MongoDB and Cosmos DB.
- Get started with YugabyteDB.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


