Announcing YugabyteDB 2.2 – Distributed SQL Made Easy
July 15, 2020
We are excited to announce the general availability of YugabyteDB 2.2! The highlight of this release is that YugabyteDB now supports fully-transactional distributed backups thus making mission-critical distributed SQL deployments operationally simple, even for the most demanding enterprise environments. This release also includes critical new features such as online index builds, colocated tables, and deferred constraints. The end result is that YugabyteDB continues to make distributed SQL easy. For those of you who are new to distributed SQL, YugabyteDB is a Google Spanner-inspired, cloud native distributed SQL database that is 100% open source. It puts a premium on high performance, data resilience, and geographic distribution while ensuring PostgreSQL wire compatibility.
In this post, we’ll share what’s new in 2.2, and a preview of upcoming features currently in beta.
Summary of New YugabyteDB 2.2 Features
Here’s a summary of the new generally available and beta features in our latest release. All features are described in detail later in this post.
Generally available in release 2.2:
- Transactional distributed backups
- Online index builds
- Deferred constraints for foreign keys
- yugabyted server for single-node clusters
- Colocated tables
- TPC-C results
In beta in release 2.2:
- Online schema changes for YCQL
- Automatic tablet splitting
- yugabyted server for multi-node clusters
- Change Data Capture
Also new and noteworthy since our last release:
- Design for online schema changes for YSQL
- Design for row-level geo-partitioning
- Continued community momentum
YugabyteDB 2.2 Generally Available Features in Detail
Transactional Distributed Backups
Prior to this release, YugabyteDB backups came in two flavors: snapshot-based distributed backups that handled single-row transactions and full backups that backed up all committed data of a database. This meant the only way to handle backups with multi-row transactions (even the ones used internally for secondary indexes) was to use full backups. However, full backups are expensive from a resource consumption standpoint and also time intensive for large data sets. The snapshot-based distributed backup approach has now been enhanced to handle multi-row transactions. And this feature is available for both YCQL (in the context of a single table and its associated indexes) as well as YSQL (in the context of all tables and relations in a single SQL database).
Online Index Builds
An index, created using one or more columns of a database table, provides the basis for both rapid random lookups and efficient access of ordered records when querying by those columns. However, it is not easy to identify the comprehensive list of indexes at the time of table creation because speeding up queries is essentially an ever-changing business requirement. YugabyteDB 2.2 supports online build of indexes that are created on non-empty tables thus ensuring that the data for the new indexes is backfilled for the existing rows, without any downtime on the cluster. This support includes simple and unique indexes for YCQL as well as simple indexes for YSQL. Unique indexes for YSQL are a work in progress.
Deferred Constraints for Fast Relational Data Loads
Application developers are used to declaring constraints that their data must obey, and then leaving it to relational databases to enforce the rules. The end result is higher developer productivity because of simpler application logic and lower error probability. Automatic constraint enforcement is a powerful feature and should be leveraged whenever possible. However, there are times when it is necessary to temporarily defer enforcement. One such example is during the data load of a relational schema where there are cyclic foreign key dependencies. Data migration tools usually defer the enforcement of foreign key dependencies to the end of a transaction by which data for all foreign keys would ideally be present. YSQL now supports DEFERRABLE INITIALLY IMMEDIATE and DEFERRABLE INITIALLY DEFERRED clauses on foreign keys. This should also allow YSQL to power Django apps. Work on deferring additional constraints including those for primary keys is in progress.
Colocated Tables for Reducing JOIN Latency
The traditional RDBMS approach of modeling parent-child relationships as foreign key constraints can lead to high-latency JOIN queries in a geo-distributed SQL database. This is because the tablets (aka shards) containing the child rows may be hosted in nodes/zones/regions different from the tablets containing the parent rows. Colocated tables avoid this problem by sharing a single tablet across all the tables. Colocation can also be at the overall database level where all tables of a single database are located in the same tablet and hence are managed by the same Raft group. Database-level colocation for YSQL, which started as a beta feature in the 2.1 release, is now generally available in the 2.2 release. Note that tables that do not want to reside in the overall database’s tablet because of the expectation of large data volume can override the feature at table creation time and hence get independent tablets for themselves.
The natural question to ask is what happens when the “colocation” tablet containing all the tables of a database becomes too big and starts impacting performance? The answer lies in automatic tablet splitting which is now available in beta. More details can be found in the Beta features section of this post.
TPC-C Results
The TPC-C benchmark models a typical OLTP application. It simulates an inventory management system, with a configurable number of warehouses. Increasing the number of warehouses increases the data set size, the number of concurrent clients as well as the number of concurrently running transactions. We are excited to announce that our open source TPC-C benchmark implementation for YugabyteDB is now ready to use! While this implementation is not officially ratified by the TPC organization, it follows the TPC-C v5.11.0 specification faithfully.
The results of running the above TPC-C benchmark with 10, 100, and 1000 warehouses are shown below. YugabyteDB was running on a 3-node cluster using c5d.4xlarge AWS instances (each with 16 CPU cores, 32GB RAM, and 1 x 400GB nvme volumes). The benchmark itself was run for 30 minutes.
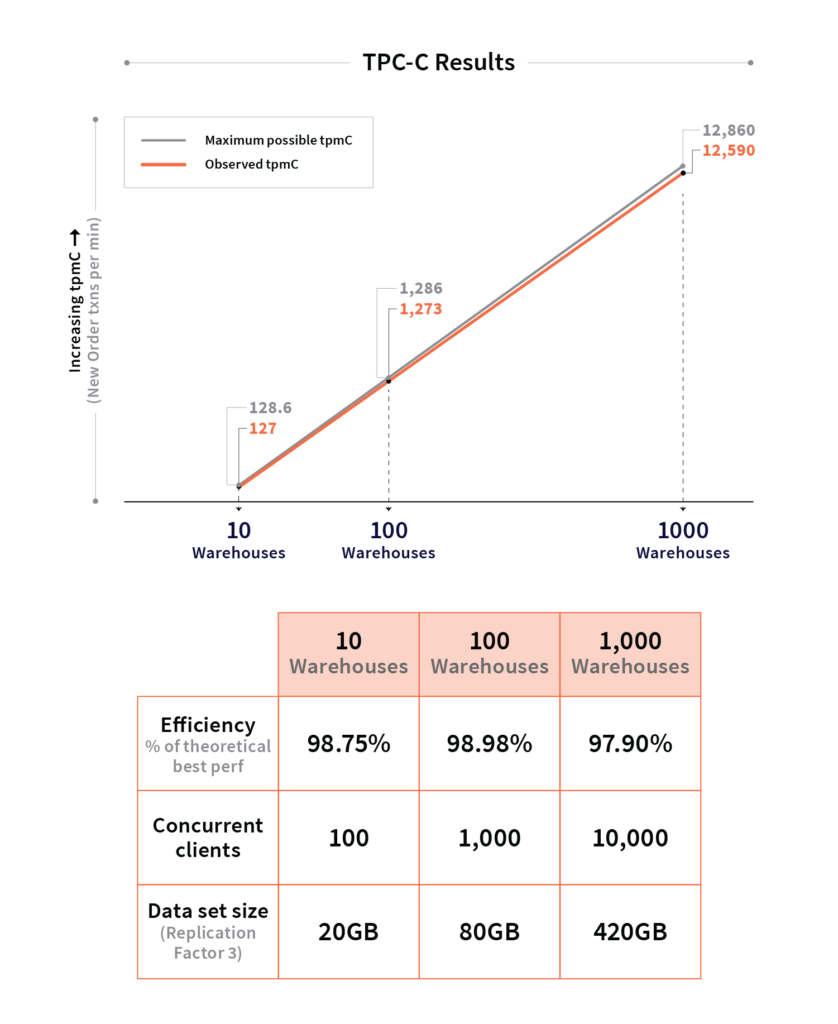
You can read more about benchmarking YugabyteDB using TPC-C along with the instructions to reproduce the above results in the YugabyteDB docs. Results for 10,000 and 100,000 warehouses are expected to be available shortly.
yugabyted for Single-Node Clusters
YugabyteDB has traditionally relied on a 2-server architecture with YB-TServers managing the data and YB-Masters managing the metadata. However, this can introduce a burden to new users who want to get started right away without even understanding the underlying architecture. The new yugabyted server acts as a parent server across YB-TServer and YB-Master. It also adds a new UI server (similar to the Yugabyte Platform UI) that allows users to experience a richer data placement map and metrics dashboard. yugabyted is now generally available for single-node deployments. See it in action by following the quick start instructions.
The Road Ahead: YugabyteDB 2.2 Beta Features in Detail
What can you look forward to beyond YugabyteDB 2.2? Let’s take a look at some of the features in beta.
Online Schema Changes for YCQL
Most applications have a need to frequently evolve the database schema, while simultaneously ensuring zero downtime during those schema change operations. Therefore, there is a need for schema migrations (which involve DDL operations) to be safely run in a concurrent and online manner alongside foreground client operations. In case of a failure, the schema change should be rolled back and not leave the database in a partially modified state. With the 2.2 release, not only has the overall DocDB framework for supporting such schema changes in an online and safe manner been introduced, but also this feature is now available in beta in the context of YCQL.
Automatic Tablet Splitting for Large Tables
As highlighted in the Colocated Tables section above, automatic tablet splitting ensures that a single large tablet can be split into multiple small tablets which can then be rebalanced across the available nodes. This is a form of advanced horizontal sharding that allows large data sets to exploit the compute and storage resources available on multiple nodes of the cluster as opposed to being limited to the resources at a single node.
yugabyted for Multi-Node Clusters
The new yugabyted server, which acts as a parent server across YB-TServer and YB-Master, can also be used to create multi-node clusters by simply starting new yugabyted servers with the --join option.
Change Data Capture for Streaming Data
Change Data Capture (CDC) allows external clients to subscribe to modifications happening to the data in a database. This is a critical feature in a number of use cases, including the implementation of an event-driven architecture that uses a message bus (such as Apache Kafka) to propagate changes across multiple microservices. YugabyteDB permits the continuous streaming of data without compromising on the foundational “global consistency” benefit that enables any node to process writes independent of other nodes and that too with full ACID guarantees. Such a CDC design is the first of its kind in the realm of distributed databases. Instructions on how to stream data out to Apache Kafka or local stdout from a YugabyteDB 2.1 cluster can be found in the official documentation.
Design-Ready Features
Online Schema Changes for YSQL
Adding support for online schema changes in YSQL including operations such as add/drop column, drop/rename table is a work in progress. Detailed design documentation as well as feature progress are available on GitHub.
Row-level Geo-Partitioning
In the context of globally-consistent multi-region clusters, row-level geo-partitioning enables data stored in a single table to be partitioned according to a user-specified column that maps range shards to nodes located in specific regions. For example, a cluster that runs across 3 regions in the US, UK, and the EU can rely on the Country_Code column of the User table to map the user’s row to the nearest region that is in conformance with GDPR rules.
Row-level geo-partitioning in YugabyteDB will be built by extending the concept of table partitions in the PostgreSQL syntax. Table partitions allow a single table to be vertically split into multiple sub tables on the same node so that each table can be queried and stored independently on that single node. Note that for distributed databases like YugabyteDB, this concept of vertical splitting (on a single node) is different from sharding which can be thought of as horizontal splitting (across multiple nodes). While PostgreSQL has traditionally used this feature to implement tiered storage (where colder data gets stored on cheaper/slower storage), YugabyteDB intends to leverage table partitions for multiple needs including query performance improvements and row-level geo-partitioning. Detailed design documentation is now available for review.
Community Momentum
Following our “Why We Changed YugabyteDB Licensing to 100% Open Source” announcement in July 2019, YugabyteDB became a 100% Apache 2.0-licensed project even for enterprise features such as encryption, distributed backups, change data capture, xCluster async replication, and row-level geo-partitioning. This means we never market to our users under a fake open source license like Business Source License where one can “try” for a limited time but in reality there is no other choice but to “buy”. Note that Yugabyte’s commercial products focus only on database administration as opposed to the industry-standard practice of “open core” where proprietary database features are upsold on an open source core.
Given that it has been exactly a year since we announced the above changes, we would like to give an update on how this change has played out on the ground with our users. We are excited to share YugabyteDB community has grown leaps and bounds in the last year! Our belief that we can deepen our community engagement by strengthening our commitment to open source has been fully validated. Following are some of the key engagement metrics.
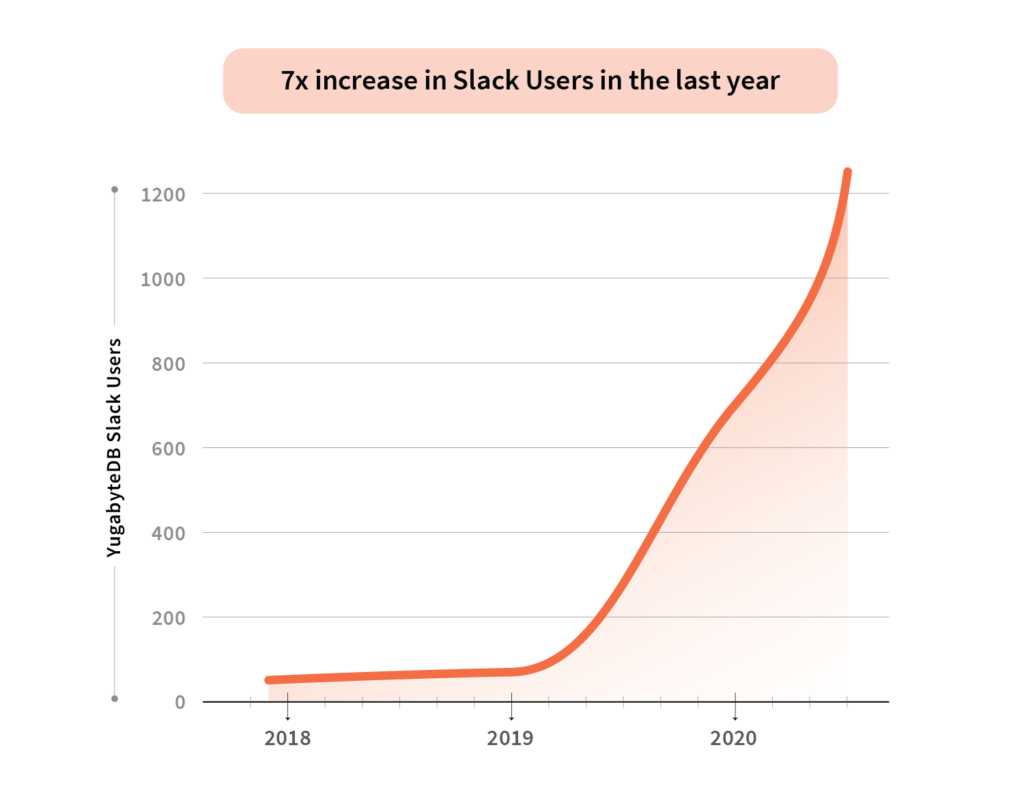
Slack Users
1300+ Slack users with a 7x increase in the last year
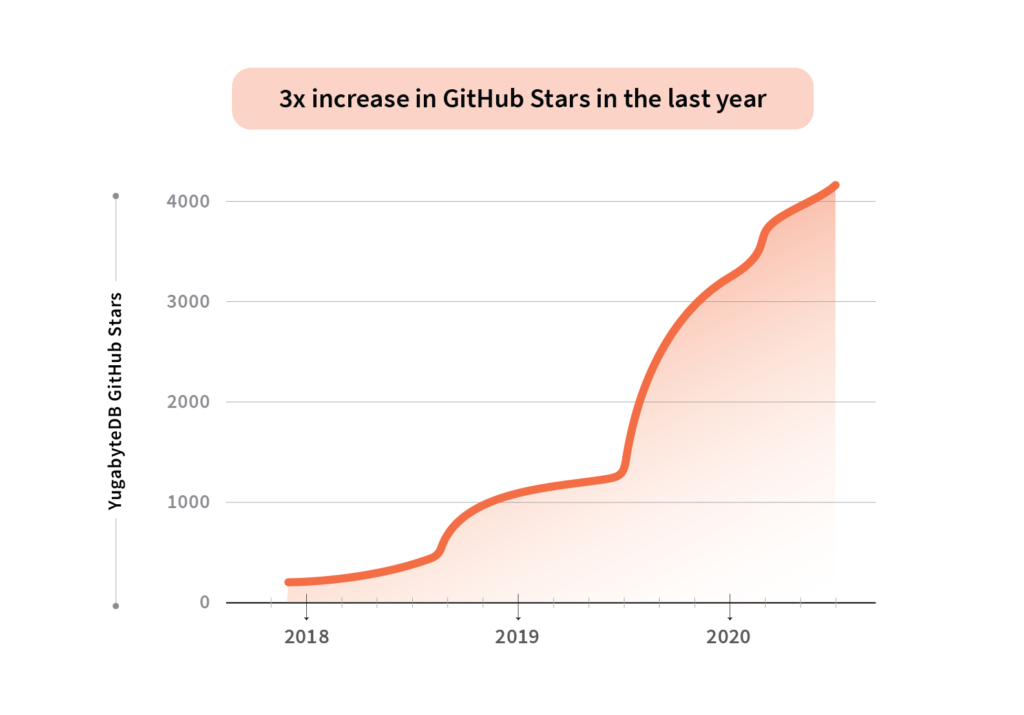
GitHub Stars
4100+ GitHub stars with a 3x increase in the last year
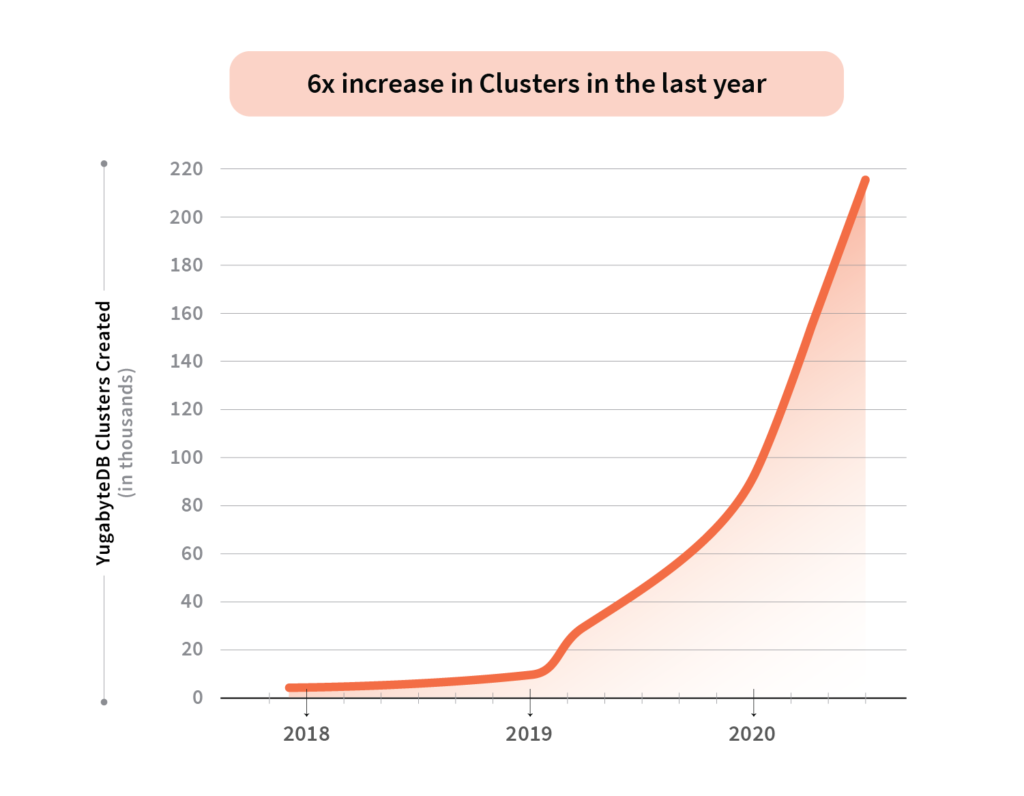
Clusters Created
6x increase in clusters in the last year
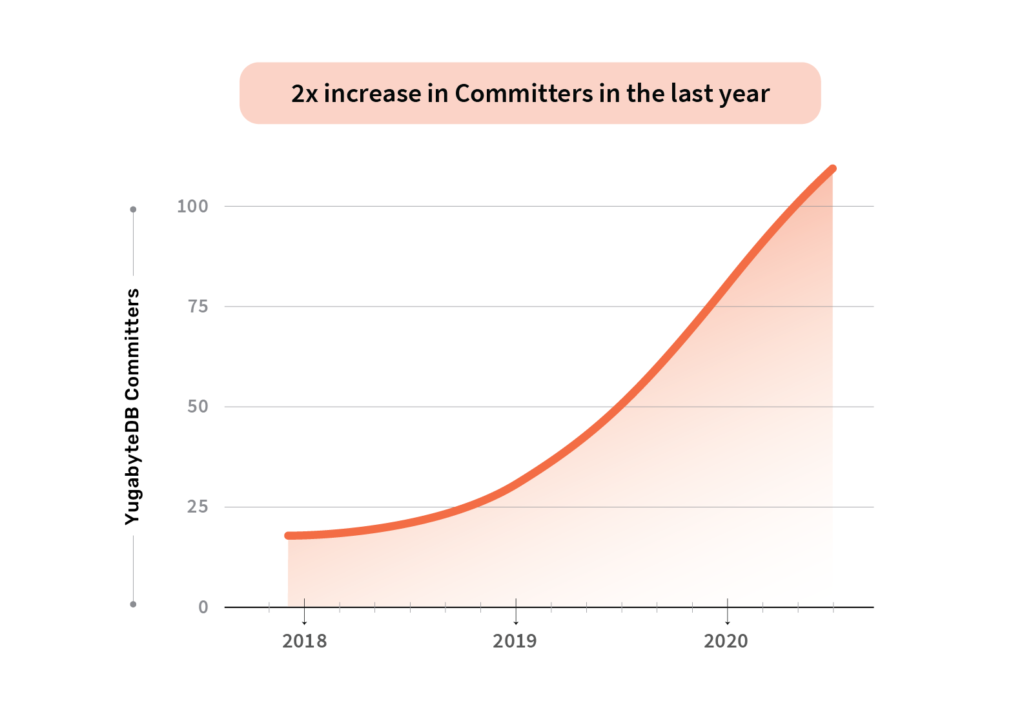
Committers
110+ committers with a 2x increase in the last year