A Quick Guide to Secondary Indexes in YugabyteDB
August 1, 2018
When creating a Cassandra-compatible YCQL table in the YugabyteDB database, you are required to create a primary key consisting of one or more columns of the table. Primary key based retrievals are efficient because YugabyteDB automatically indexes/organizes the data by the primary key. However, there are many use cases where you may need to retrieve data using columns that are not a part of the primary key. This is where secondary indexes help.
A secondary index can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records when querying by those columns. Secondary indexes require additional writes and storage space to maintain the index data structure.
YugabyteDB provides consistent (ACID), high-performance secondary indexes built on top of distributed ACID transactions.
Example of a User Profile Table
Let us imagine the use case of storing user profiles. To keep the example simple, let us assume that each user has a first name, a last name, an email address, and a unique user id.
Given that the user id is unique across all the users, it is an ideal candidate for being the primary key of the table. Lookups to the table by the user id will be very efficient, even if there are a large number of users. This works well for the cases when a logged in user wants to view or edit their profile.

Now, assume we want to lookup the user profile given an email address. Without any indexes, this query would end up scanning through all the users to search for a user with the given email address. For a large number of users, this operation is very inefficient.
A secondary index created on the email address column would speed up the lookups done by an email address. When a secondary index is created on a table, YugabyteDB automatically maintains a separate index table which is automatically updated when the primary table is modified. In this table the data is organized by the email address.
User Profile Table
YugabyteDB uses distributed ACID transactions under the hood in order to maintain consistency of secondary indexes. This means that from the perspective of user queries, the value of the user profile table and the secondary index table are always consistent — even when updates are happening at the same time as reads. Read more about how YugabyteDB implements distributed ACID transactions.
Note that YugabyteDB is a distributed database, which means it runs on a set of nodes. Thus, for any scenario including the above, YugabyteDB can seamlessly scale out while maintaining consistency of data.
Trying It Out
Let us try out the above scenario on YugabyteDB by performing the queries.
Remember to install YugabyteDB and connect to cqlsh in order to try out this scenario on your local machine.
First, create a YCQL keyspace called myapp by running the following command in cqlsh.
CREATE KEYSPACE myapp;
Next, create a users table with user_id as the primary key column. Each user has a firstname, a lastname and an email as additional columns.
CREATE TABLE myapp.users(
user_id bigint PRIMARY KEY,
firstname text,
lastname text,
email text
) WITH transactions = { 'enabled' : true };As mentioned before, the above table is optimized to perform lookups by the primary key column (which is the user_id column). It is also very efficient at handling the writes and scaling out for millions of users.
Now, in order to efficiently look up users by their email address, we need to create a secondary index on the email column. This can be done as follows.
CREATE INDEX users_by_email ON myapp.users (email)
INCLUDE (firstname, lastname);Note that the INCLUDE clause above causes the secondary index table to store the values for the firstname and lastname columns as well, allowing queries that need to lookup the user name by their email address to be satisfied entirely from the secondary index table. Without the INCLUDE clause, the user query would first fetch the primary key from the secondary index table, and subsequently lookup the users table by the primary key. Now that we have created the table and the secondary index, let us load some data.
INSERT INTO myapp.users (user_id, firstname, lastname, email)
VALUES (1, 'James', 'Bond', 'bond@yb.com');
INSERT INTO myapp.users (user_id, firstname, lastname, email)
VALUES (2, 'Sherlock', 'Holmes', 'sholmes@yb.com');
INSERT INTO myapp.users (user_id, firstname, lastname, email)
VALUES (3, 'Clark', 'Kent', 'superman@yb.com');
INSERT INTO myapp.users (user_id, firstname, lastname, email)
VALUES (4, 'Peter', 'Parker', 'spiderman@yb.com');
INSERT INTO myapp.users (user_id, firstname, lastname, email)
VALUES (5, 'Bruce', 'Wayne', 'bruce@yb.com');To retrieve the user profile a given user id (in this example user id 1), you can run the following:
SELECT * FROM myapp.users WHERE user_id = 1;
You should see the following:
cqlsh> SELECT * FROM myapp.users WHERE user_id = 1;
user_id | firstname | lastname | email
---------+-----------+----------+-------------
1 | James | Bond | bond@yb.com
(1 rows)Next, let us query the user profile for the email address superman@yb.com. This can be done as follows:
SELECT * FROM myapp.users WHERE email='superman@yb.com';
You should see the following:
cqlsh> SELECT * FROM myapp.users WHERE email='superman@yb.com';
email | user_id | firstname | lastname -----------------+---------+-----------+---------- superman@yb.com | 3 | Clark | Kent (1 rows)
Updating any of the values for a row should keep the index consistent. For example, let us update the email address for the above record by doing:
UPDATE myapp.users SET email='superman-new@yb.com' WHERE user_id=3;
Querying for the new email address should return the row:
cqlsh> SELECT * FROM myapp.users
WHERE email = 'superman-new@yb.com';email | user_id | firstname | lastname ---------------------+---------+-----------+---------- superman-new@yb.com | 3 | Clark | Kent (1 rows)
Querying by the older value should not have any results:
cqlsh> SELECT * FROM myapp.users WHERE email = 'superman@yb.com'; email | user_id | firstname | lastname -------+---------+-----------+---------- (0 rows)
At Scale Testing
YugabyteDB source ships with a number of sample apps. One of the workloads supported is the CassandraSecondaryIndex. This workload simply inserts unique key-value pairs into a table that has a secondary index on the value column, and performs lookups by the value column.
We setup a 3-node cluster of n1-standard-16 instance types (16 vCPU, 60GB RAM, 2 x 375GB SSD per node) in Google Cloud. The cluster had a replication factor of 3 allowing it to survive node failures. Each key-value being inserted was about 64 bytes in size.
In the write phase of the test, we loaded 100 million keys with 128 writers. The entire load took about 3 hours with a steady write IOPS of over 8K write ops/sec. Below is the load command.
$ java -jar yb-sample-apps.jar \ --workload CassandraSecondaryIndex \ --nodes 10.150.0.42:9042 \ --num_threads_read 0 \ --num_threads_write 128 \ --num_unique_keys 100000000 \ --nouuid
The graph of the write phase is shown below. The throughput of the workload was a little over 8000 writes/sec at a 12ms latency.
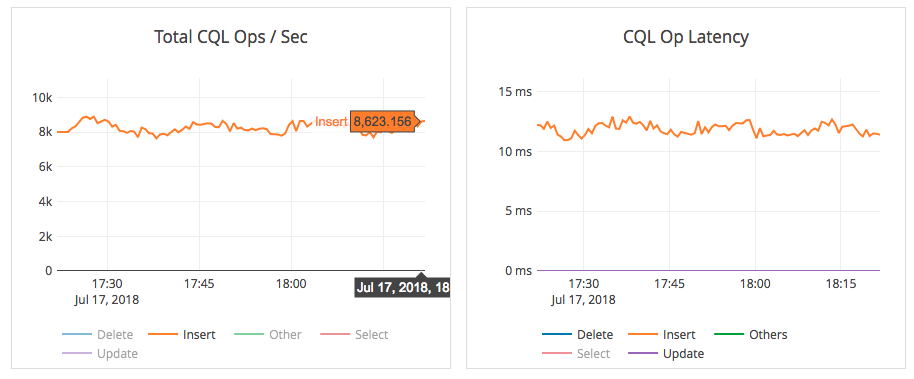
The read phase of the test looked up the 1 billion keys at random by querying their values. The reads were done using 256 readers for about 3 hours. The read IOPS were steady at about 80k read ops/sec. Below is the read command.
$ java -jar yb-sample-apps.jar \ --workload CassandraSecondaryIndex \ --nodes 10.150.0.42:9042 \ --num_threads_read 256 \ --num_threads_write 0 \ --max_written_key 100000000 \ --nouuid
Below is a graph of the total IOPS and the latency during the read phase. The graphs show about 175K reads/sec at about 0.25ms server-side latency.
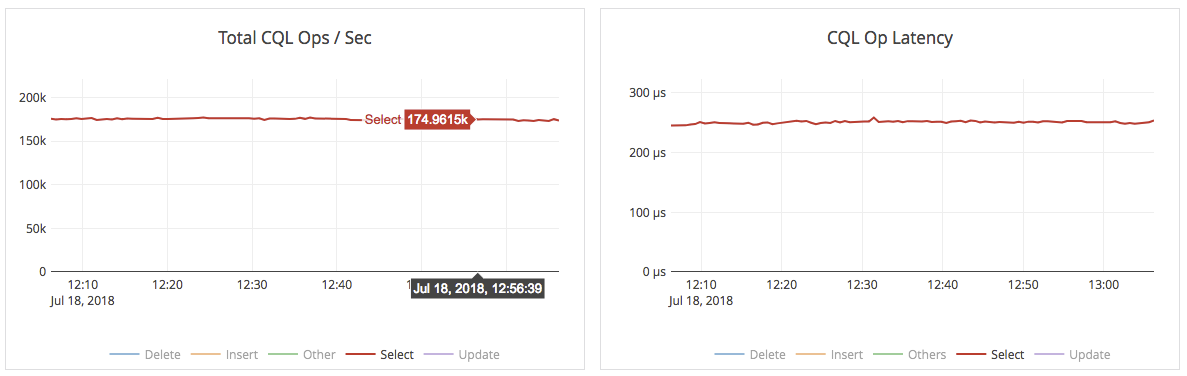
What’s Next?
A number of users have expressed interest in the secondary index feature. At the time of this writing (August 1, 2018), the secondary index feature is being beta tested out in pre-production by a few of our users. We expect secondary indexes to be ready for production in about a month (specifically, mid-August 2018).
As for next steps, here are some improvements we are working on relating to secondary indexes:
- Currently, the secondary indexes need to be created before loading data. We will soon allow secondary indexes to be created on tables with pre-existing data.
- YugabyteDB today only supports equality-based indexes. Equality-based indexes are ideal when queries try to lookup data by an exact value (as opposed to lookups for values less than or greater than a particular value). We are working on indexes that will allow comparison and range queries.
Interested? You can follow YugabyteDB on GitHub!


