A Busy Developer’s Guide to Database Storage Engines — The Basics
June 28, 2018
Editor’s note – This is the first part of a two-part series on database storage engines:
- A Busy Developer’s Guide to Database Storage Engines — The Basics (this post)
- A Busy Developer’s Guide to Database Storage Engines — Advanced Topics
When evaluating operational databases, developers building distributed cloud applications tend to focus on data modeling flexibility, consistency guarantees, linear scalability, fault tolerance, low latency, high throughput, and easy manageability as high priority concerns. However, it is essential to have a good understanding of the underlying storage engine to reason about how the database actually delivers on these core promises. This post aims to help busy developers make informed choices in the context of database storage engines.
A database storage engine is an internal software component that a database server uses to store, read, update, and delete data in the underlying memory and storage systems.
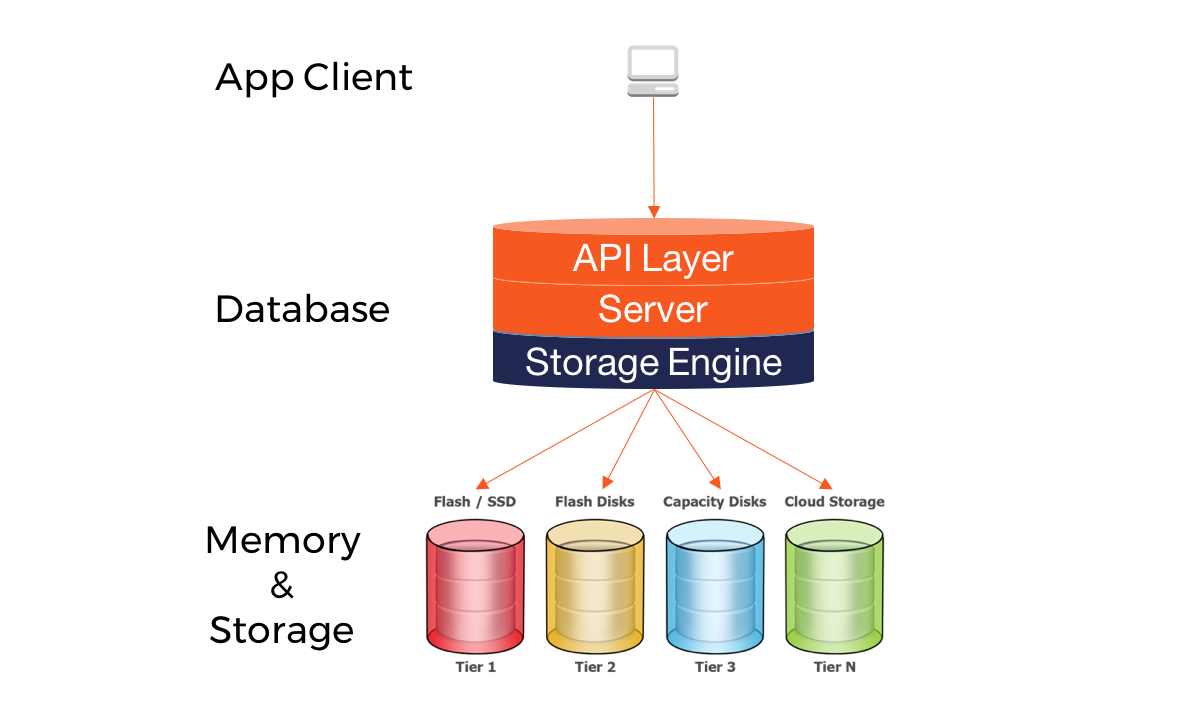
While there have many types of database storage engines since the early 1970s, only two of them are popular enough to merit a discussion in the context of modern distributed cloud applications — B-tree based and LSM tree based.
B-Tree Based Engine
First introduced in 1971, a B-tree is a self-balancing tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time.
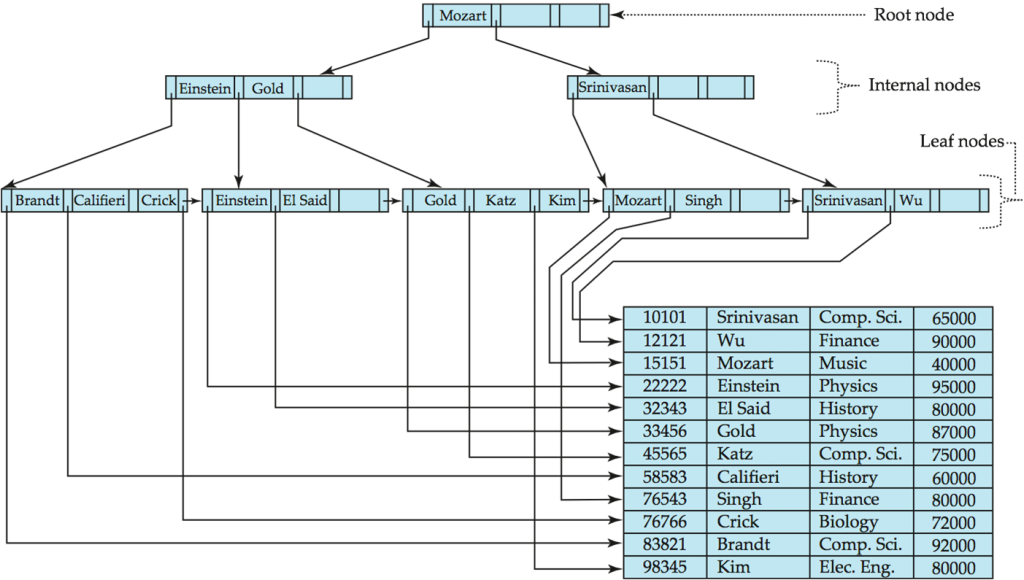
The State of the Storage Engine describes the B-tree based storage engine as a combination of B-tree based primary/secondary indexes along with row-based storage (where a row is a single record in the database).
Pros & Cons
B-trees usually grow wide and shallow, so for most queries very few nodes need to be traversed. The net result is high throughput, low latency reads. However, the need to maintain a well-ordered data structure with random writes usually leads to poor write performance. This is because random writes to the storage are more expensive than sequential writes. Also, a minor update to a row in a block requires a read-modify-write penalty of an entire block.
Real-World Usage
The default storage engines of popular monolithic relational/SQL databases follow the B-tree architecture — the list includes Oracle DB, MS SQL Server, IBM DB2, MySQL (InnoDB), and PostgreSQL. While it may be tempting to conclude that B-tree engines are only for SQL databases, it should be noted that even NoSQL databases can be based on B-tree engines. E.g. MMAPv1, the original storage engine of MongoDB (default in versions prior to 3.2), is B-tree based. Couchbase is another NoSQL database powered by a B-tree engine.
Log Structured Merge (LSM) Tree Based Engine
As data volumes grew in the mid 2000s, it became necessary to write larger datasets to databases. B-tree engines fell out of favor given their poor write performance. Database designers turned to a new data structure called log-structured merge-tree (or LSM tree), that was first published in academic research in 1996.
The LSM tree is a data structure with performance characteristics best fit for indexed access to files with high write volume over an extended period.

LSM trees use an algorithm that defers and batches index changes, cascading the changes from a memory-based component (C0 in the above picture) through one or more disk components (C1 to CL) in an efficient manner reminiscent of merge sort. Note that random writes at the in-memory C0 component are turned into sequential writes at the disk-based C1 component.
Pros & Cons
LSM engines are the de facto standard today for handling workloads with large fast-growing data. The primary reason behind their success is their ability to do fast sequential writes (as opposed to slow random writes in B-tree engines) especially on modern flash-based SSDs that are inherently better suited for sequential access. They are also better suited for tiered storage where different types of storage with different performance/cost characteristics, such as RAM, SSD, HDD, and remote file stores (such as AWS S3), can be leveraged, especially when data volume grows beyond what can be stored on a single storage mechanism.
The next obvious question to ask — do LSM tree based engines exhibit poor read throughput in comparison to B-tree based engines? In theory, the answer is yes as shown by this benchmark from WiredTiger, a storage engine with support for both B-tree and LSM engines. This is because LSM engines demonstrate higher read and space amplification than B-trees. In simpler terms, LSM engines consume more CPU resources during read operations and take more memory/disk storage. E.g. a point query with an LSM tree may require multiple random reads. However, these issues get mitigated in practice. Storage is becoming cheaper with time. Reads are made faster with approaches such as bloom filters (to reduce the number of files to be checked during a point query) and per-SSTable min-max metadata hints (for efficient range queries).
Real World Usage
LSM engines are now default in popular NoSQL databases including Apache Cassandra, Elasticsearch (Lucene), Google Bigtable, Apache HBase, and InfluxDB. Even widely adopted embedded data stores such as LevelDB and RocksDB are LSM based. One such embedded RocksDB implementation is MyRocks that replaces the default InnoDB engine in MySQL. DocDB, the YugabyteDB storage engine, is also built on a custom version of RocksDB.
As noted previously WiredTiger, MongoDB’s default storage engine, comes in both B-tree and LSM configurations. However, MongoDB ships WiredTiger in only B-tree configuration with the rationale of keeping it simple for users. As expected, the result is poor write performance for workloads with large data volumes. As noted in the MongoDB JIRA for LSM Support, users deal with this issue by adding a separate in-memory data tier such as Redis to offload some of the incoming write requests and then persist only aggregate results in MongoDB. While this solution may look like an application-level change of a B-tree engine to LSM (where Redis becomes the in-memory C0 component), it is more complex and error-prone (including data loss) than using a true LSM engine.
Summary

At the core, database storage engines use an index management algorithm that is optimized for either read performance (B-tree) or write performance (LSM). The database API layer (SQL vs. NoSQL) is a choice independent of the storage engine since both B-tree and LSM engines are used in SQL and NoSQL databases.
The next post concludes the series with a review of advanced considerations in storage engine design such as consistency, transactions, concurrency, compactions, and compression.


