6 Technical Challenges Developing a Distributed SQL Database
April 26, 2019
You can join the discussion on HackerNews here.
We crossed the three year mark of developing the YugabyteDB database in February of 2019. It has been a thrilling journey thus far, but not without its fair share of technical challenges. There were times when we had to go back to the drawing board and even sift through academic research to find a better solution than what we had at hand. In this post we’ll outline some of the hardest architectural issues we have had to address in our journey of building an open source, cloud native, high-performance distributed SQL database. Look for subsequent posts that will dive-deep into each respective issue.
OK, let’s get started exploring these issues from easiest to most challenging.
1. Architecture: Amazon Aurora or Google Spanner?
One decision we made early on was to find a database we could use as inspiration for YugabyteDB’s architecture. We looked closely at two systems, Amazon Aurora and Google Spanner.
Amazon Aurora is a SQL database that offers high availability. It has drop-in compatibility with popular RDBMS databases like MySQL and PostgreSQL, making it very easy to get started with and can run a wide variety of applications. Amazon Aurora is also one of the fastest growing services in the history of AWS.
The Amazon Aurora service, which is MySQL and PostgreSQL compatible, is the fastest growing service in the history of AWS.
Amazon Aurora has a scalable data storage layer, but not so for the query layer. Below are some key scalability limitations of Amazon Aurora we uncovered:
- Writes are not horizontally scalable. The only way to scale the write throughput is by vertically scaling up the node that handles all the writes (called the master). This scheme of scaling up only goes so far, thus there is an inherent limit on how many write IOPS the database can handle.
- Writes are not globally consistent. Many modern, cloud-native applications are global in nature, requiring the underlying database to be deployed across multiple regions. However, Aurora only supports multi-master deployments where the last writer (with the highest timestamp) wins in case of conflicts. This could lead to inconsistencies.
- Reads scale by using slave replicas which sacrifice consistency. In order to scale reads, applications are required to connect to slave nodes to perform reads. The application needs to reason about the reduced consistency semantics and separate end-points to connect to when using these slaves nodes to perform reads. This makes the application architecture very complex.
Alternatively, Google Spanner is a horizontally-scalable SQL database, built for massively scalable and geo-distributed applications.
Cloud Spanner is the only enterprise-grade, globally-distributed, and strongly consistent database service built for the cloud specifically to combine the benefits of relational database structure with non-relational horizontal scale.
This means that Spanner can seamlessly scale reads and writes, support geo-distributed applications requiring global consistency and perform reads from multiple nodes without sacrificing correctness.
However, it gives up on offering a lot of the feature-set that developers familiar with RDBMS database expect. For example, the following snippet from Google Spanner documentation highlights the fact that foreign key constraints or triggers are not supported.

Our Decision
We decided that a hybrid approach was in order.
- The core storage architecture of YugabyteDB is inspired by Google Spanner which is built for horizontal scalability and geo-distributed applications.
- YugabyteDB retains a PostgreSQL-compatible query layer like Amazon Aurora which can support a rich set of functionality and support the broadest range of use cases possible.
2. SQL Protocol: PostgreSQL or MySQL?
We wanted to standardize on a SQL dialect that was widely adopted. We also wanted it to be open source and have a mature ecosystem around the database. The natural choices to weigh were PostgreSQL and MySQL.
Our Decision
We chose PostgreSQL (and not MySQL) for the following reasons:
- PostgreSQL has a more permissive license which was more inline with the open source ethos of YugabyteDB.
- And it definitely did not hurt that the popularity of PostgreSQL in the last few years has been skyrocketing compared to any other SQL database!
Of the five SQL databases currently in the top 10 of DB-Engines ranking site, only PostgreSQL has been growing in popularity since 2014, while the others have flatlined or are losing mindshare.
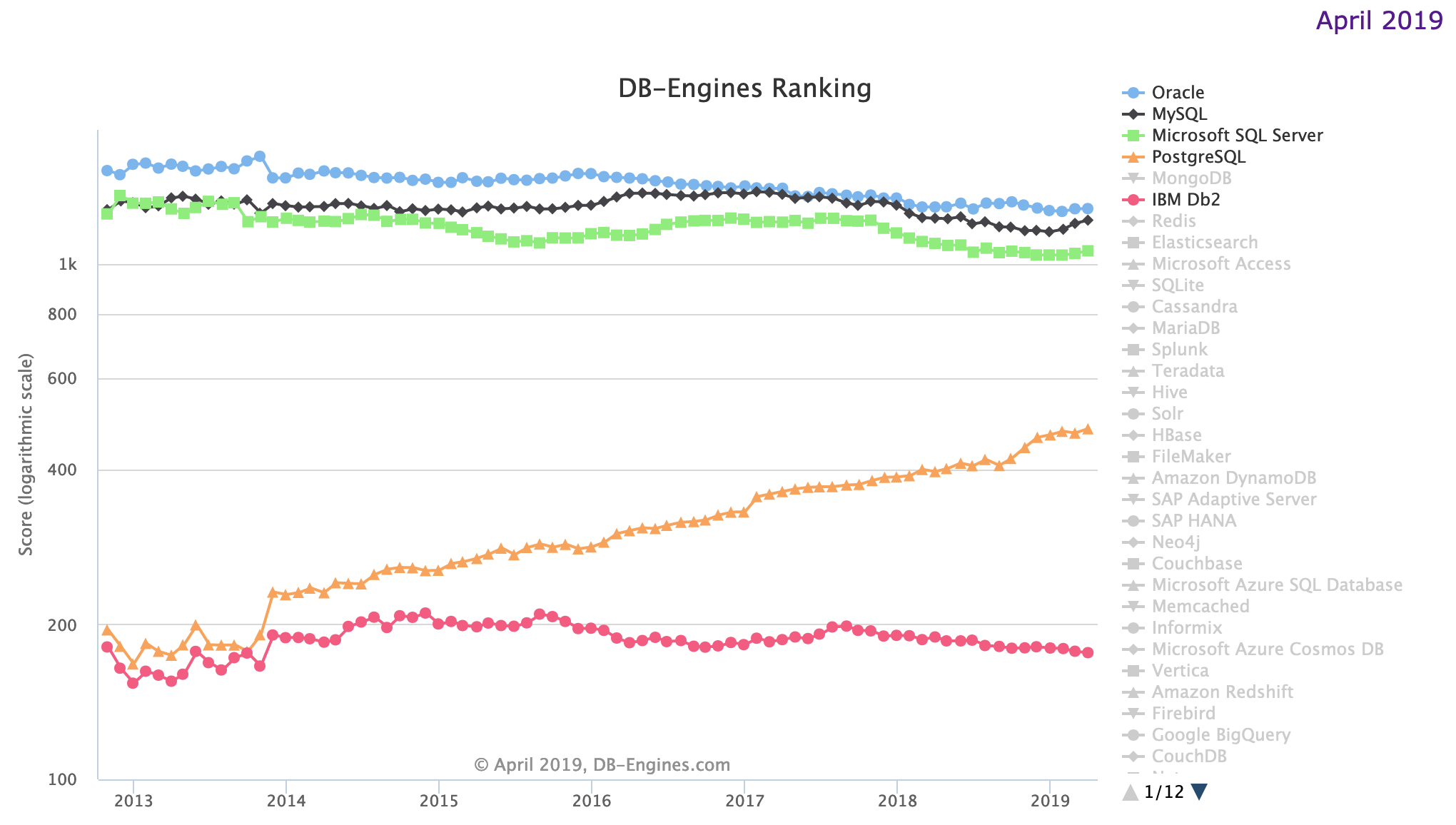
Also, for many applications, PostgreSQL is an excellent alternative to Oracle. Organizations are being drawn to PostgreSQL because it is open source, vendor neutral (MySQL is owned by Oracle), has an engaged community of developers, a thriving ecosystem of vendors, a robust feature set, and a mature code base that has been battle-hardened with over 20 years of rigorous use.
3. Distributed Transactions: Google Spanner or Percolator?
In regards to how we should design our distributed transactions, we looked at both Google Spanner and Percolator.
To summarize, Google Percolator offers high throughput but uses a single timestamp oracle. This approach is inherently not scalable, and works only for single datacenter, real-time analytics oriented (called HTAP) applications as opposed to OLTP applications. On the other hand, Google Spanner’s approach of decentralized time tracking is a great solution for both geo-distributed OLTP and single datacenter HTAP apps.
Google Spanner was built after Google Percolator, to replace manually sharded MySQL deployment in the ads backend to enable horizontal scalability and geo-distributed use-cases. However, Google Spanner is an order of magnitude harder to build given its truly distributed nature and the need for clock-skew tracking.
For more details on this topic you can read in detail about the Percolator vs Spanner tradeoffs.
Our Decision
We decided to follow the Google Spanner approach, since it can support:
- Better horizontal scalability
- Highly available and better performing multi-region deployments.
It is our strong belief that most modern cloud applications will require both of the above. In fact, compliance requirements such as GDPR and the public clouds offering 100s of regions in total are already making this a reality.
4. Does Raft Work For Geo-Distributed Workloads?
Raft and Paxos are well known distributed consensus algorithms and have been formally proven to be safe. Spanner uses Paxos. However, we chose Raft because:
- It is easier for developers and operations teams to understand than Paxos.
- It offers the ability to dynamically change membership, which is critical (example: changing machine types without affecting performance).
However, in order to ensure linearizable reads, Raft requires each leader receiving a read query to first propagate a heartbeat message to a majority of nodes in the Raft group before actually serving the read query. This could severely degrade read performance in some scenarios. An example of such a scenario is a geo-distributed deployment, where a round-trip would increase the latency dramatically as well as increase the number of failed queries in cases of events such as temporary network partitions.
Our Solution
In order to avoid the high latency of vanilla Raft, we implemented a leader lease mechanism which would allow us to serve from the tablet leader without requiring a round-trip, while preserving the linearizability property of Raft. Additionally, we utilized the monotonic clock instead of the realtime clock in order to tolerate clock skews.
5. Can We Build a Software-Defined Atomic Clock?
Being a distributed database, YugabyteDB supports multi-key ACID transactions (snapshot and serializable isolation levels) across multiple nodes even in presence of failures. This requires a clock that can synchronize time across nodes.
Google Spanner famously uses TrueTime, which is an example of a highly available, globally synchronized clock with tight error bounds. However, such clocks are not available in many deployments.
Physical time clocks (or wall clocks) cannot be perfectly synchronized across nodes. Hence they cannot order events (to establish a causal relationship) across nodes. Logical clocks such as Lamport clocks and vector clocks do not track physical time unless there is a central timestamp authority, which becomes a scalability bottleneck.
Our Solution
Hybrid Logical Clocks (HLC) solve the problem by combining physical time clocks that are coarsely synchronized using NTP with Lamport clocks that track causal relationships.
YugabyteDB uses the HLC as a highly available cluster wide clock with a user-specified max clock skew upper bound value. The HLC value is used across Raft groups as a way to correlate updates and also as the MVCC read point. The result is an ACID-compliant distributed database, as shown by Jepsen testing.
6. Rewrite or Reuse PostgreSQL Query Layer?
Last but not least, we needed to decide whether to rewrite or reuse PostgreSQL query layer.
Our Initial Decision
The YugabyteDB Query Layer has been designed with extensibility in mind. Having already built two APIs (YCQL and YEDIS) into this query layer framework by rewriting the API servers in C++, a rewrite of the PostgreSQL API seemed easier and natural at first.
Our Final Decision
We were about 5 months down this path before we realized this was not an ideal path. The other APIs were much simpler compared to the mature, full-fledged database that PostgreSQL was. We then reset the whole effort, went back to the drawing board and started anew with the approach of re-using PostgreSQL’s query layer code. While this was painful in the beginning, it has been a much better strategy in retrospect.
This approach had its own challenges as well. Our plan was to first move the PostgreSQL system tables into DocDB (the storage layer of YugabyteDB) with support for a few data types and some simple queries initially, and add more data types and query support over time.
Unfortunately, this plan did not quite work out as is. To perform what seem like simple end user commands from psql actually requires support for a wide set of SQL features. For example, the \d command, which is used to list all the tables, performs the following query internally:
SELECT n.nspname as "Schema",
c.relname as "Name",
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 'v' THEN 'view'
WHEN 'm' THEN 'materialized view'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 's' THEN 'special'
WHEN 'f' THEN 'foreign table'
END as "Type",
pg_catalog.pg_get_userbyid(c.relowner) as "Owner"
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind IN ('r','')
AND n.nspname <> 'pg_catalog'
AND n.nspname <> 'information_schema'
AND n.nspname !~ '^pg_toast'
AND pg_catalog.pg_table_is_visible(c.oid)
ORDER BY 1,2;
Satisfying the above query requires support for the following features:
WHEREclauses with support for operators such asIN, not equals, regex matches, etc.CASEclause- Joins, specifically a
LEFT JOIN ORDER BYclause- Builtins, such as
pg_table_is_visible()
Clearly, this represents a wide array of SQL features, so we had to make all of these available before being able to create a single user table! Our post Distributed PostgreSQL on a Google Spanner Architecture – Query Layer highlights how the query layer works in detail.
Conclusion
Even to the expert user, having to choose between many databases available in the market might seem overwhelming at first. This is because the choice of the database for a given type of application depends on the trade offs these databases have made in their architecture.
With YugabyteDB, we have combined a very practical set of architectural decisions in a novel way to create a unique open source, distributed SQL database. PostgreSQL’s powerful SQL features are now available to you with zero data loss, horizontal write scalability, low read latency along with the ability to run natively in a public cloud or Kubernetes.
To learn more about YugabyteDB, you can try out the SQL features it supports as well as its other core features. Do remember to try out your favorite PostgreSQL features and file a GitHub issue if you see something missing. Look forward to hearing your feedback.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Amazon Aurora and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


